Manually scrape data using browser extensions
Overview
Teaching: 15 min
Exercises: 10 minQuestions
How can I get started scraping data off the web?
How can I use XPath to more accurately select what data to scrape?
Objectives
Introduce the Chrome Scraper extension.
Practice scraping data that is well structured.
Use XPath queries to refine what needs to be scraped when data is less structured.
Using the Scraper Chrome extension
Now we are finally ready to do some web scraping using Scraper Chrome extension. If you haven’t it installed in your machine, please refer to the Setup instructions.
For this lesson, we will be using two UCSB department webpages: East Asian Languages and Cultural Studies and Jewish Studies. We are interested in scraping contact information from faculty within these departments with the help of Xpath and Scraper.
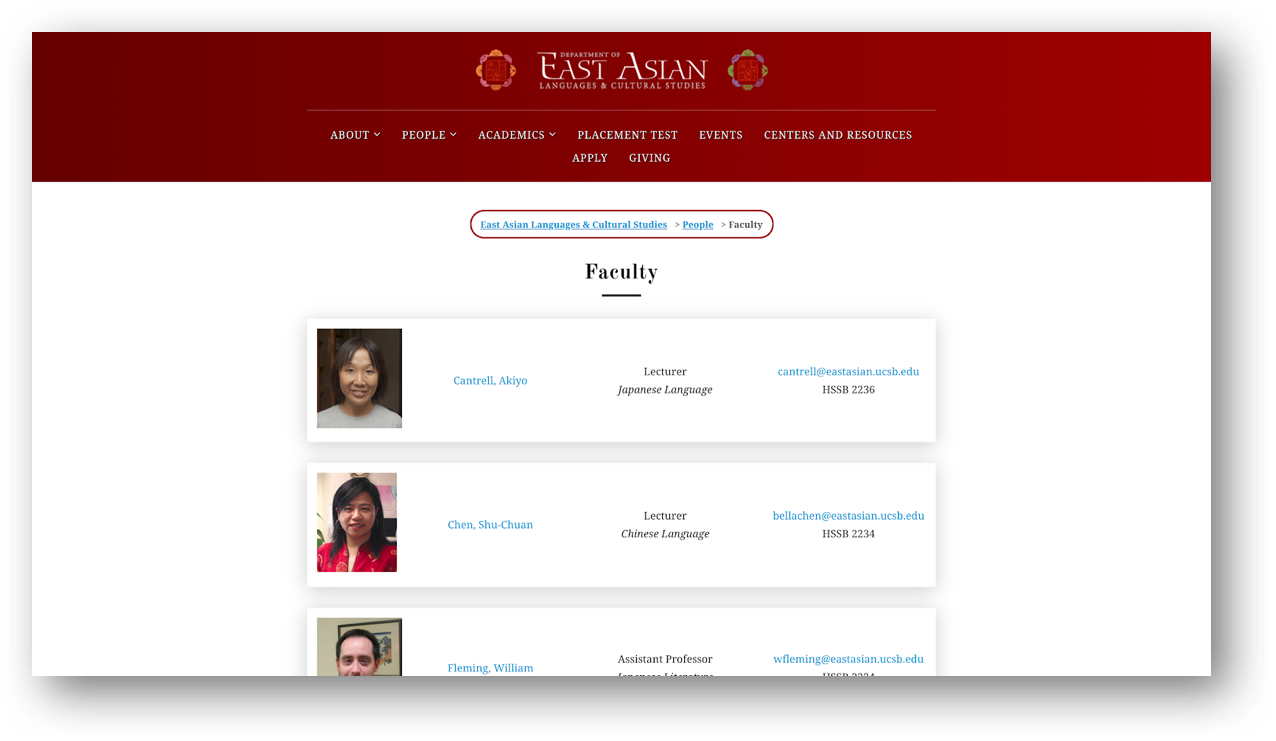
First, let’s focus our attention on the East Asian Languages and Cultural Studies webpage https://www.eastasian.ucsb.edu/people/faculty/.
We are interested in downloading the list of faculty names and their email addresses.
Scrape similar
With the extension installed, we can select the first row in the faculty list, do a right-click and choose “Scrape similar” from the contextual menu. Please note that the icon can

You can select the picture as well. Make sure you do not right-click on a hyperlinked text. Alternatively, the “Scrape similar” option can also be accessed from the Scraper extension icon, but we have found that often times you can experience a glitch with the path with this option.
Either operation will bring up the Scraper window:
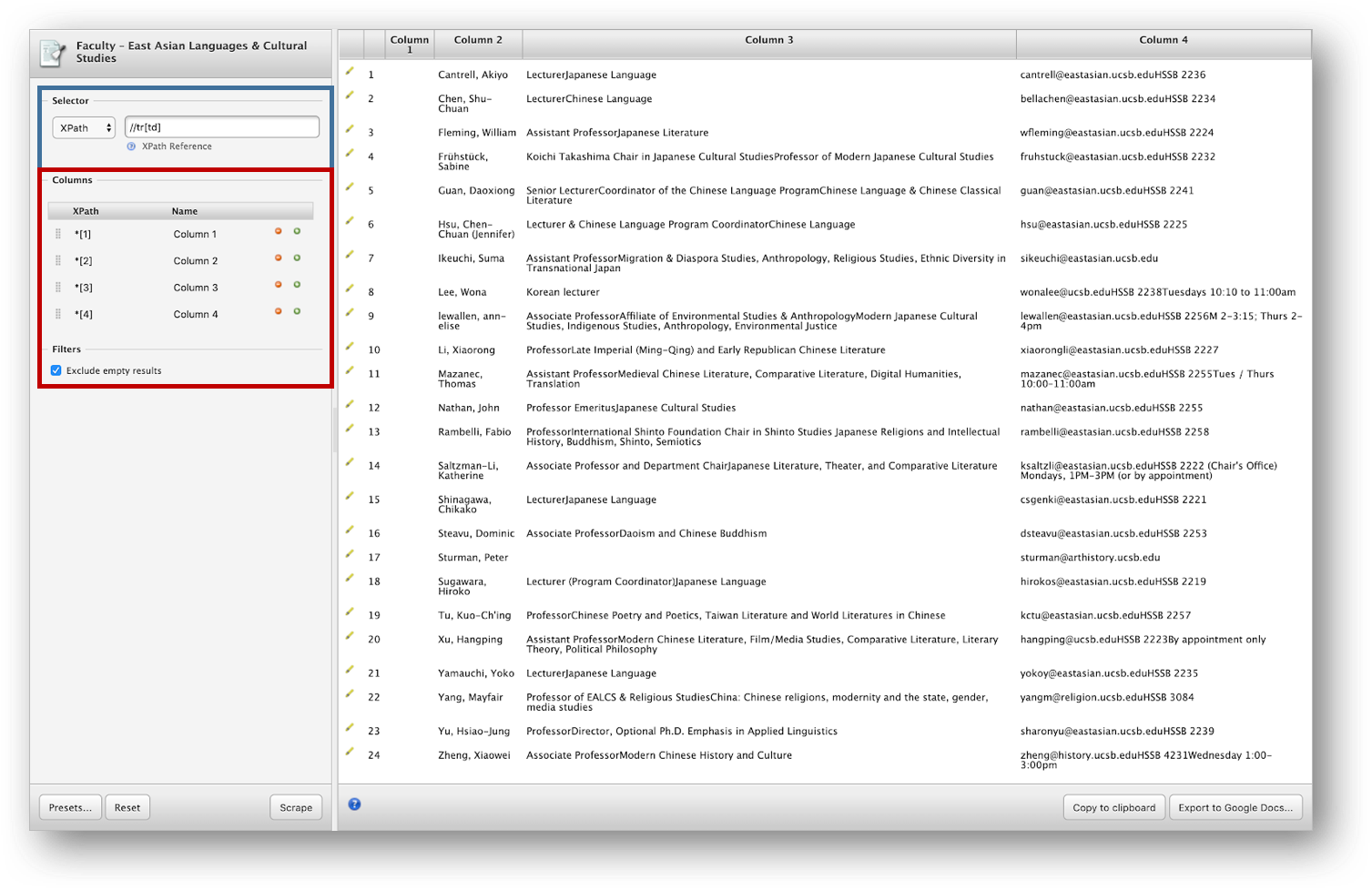
We can notice that Scraper has generated XPath queries that correspond to the data we had selected upon calling it. The Selector (highlighted in blue in the above screenshot) has been set to //tr[td] which selects all the rows of the table, delimiting the data we want to extract.
In fact, we can try out that query using the technique that we learned in the previous section by typing the following in the browser console:
Tip: Use the following shortcuts to Open Console Panel:
Mac: (Command+Option+J)
Windows/Linux: (Control+Shift+J).
Remember:
<tr>defines a row in a table and<td>defines a data cell in a table
$x("//tr[td]")
The above query will return something like:
<- (48)
Which we can explore in the console and check for highlights to make sure this is the right data.
Could you guess why we got 48 as a result?
There are 24 rows with faculty profiles, but in between them we had tr box shadows, if we unselect “Exclude empty results” which is set by default, we will get empty rows in our output. So it is wise to keep this option always selected.
Scraper also recognized that there were four columns in that table, and has accordingly created such columns (highlighted in red in the screenshot), each with its own XPath selector, *[1], *[2], *[3] and *[4].
To understand what this means, we have to remember that XPath queries are relative to the current context node. The context node has been set by the Selector query above, so those queries are relative to the array of tr elements that have been selected.
We can replicate their effect by trying out the following expression in the console:
$x("//tr[td]/*[4]")
This should select only the fourth element of the table.
But in this case, we don’t need to fiddle with the XPath queries too much, as Scraper was able to deduce them for us, and we can copy the data output to the clipboard and past it into a text document or a spreadsheet.
There is a bit of data cleaning we might want to do prior to that, though.
- The first column is empty because we have selected the photo and scraper recognizes that as an element, however, images are not included in the scraping process, so we can remove it using the red (-) icon and click on scrape to see the change. Let’s do the same thing with column three because we are not interested in getting their positions and specialties for this example.
- We also want to rename the other columns remaining accordingly, so let’s change them to Faculty_name and Contact_info.
Custom XPath queries
Sometimes, however, we do have to do a bit of work to get Scraper to select the data elements that we are interested in.
Note that we still have other info such as office location and times along with emails. So what if we want to get a column only with emails instead? We should add a new column and rename it as Email and use Xpath to help us to refine that. To add another column in Scraper, use the little green “+” icon in the columns list.
Let’s inspect the link to identify on the developer’s console the exact path for the email addresses. Select the email > right-click (make sure to not click in the email) > Inspect. Then, hover the mouse over the email > right-click > copy > copy Xpath. Note that there will be an option to copy the Full path but you do not need that as we have already scraped from a portion of the website.
Tip:
You can copy the path to a notepad, it will help you to compare it with scrap and understand better where the element you are interested in is located. You should have the path bellow or something slightly different if you have selected other faculty email as the <tr> [row number] will represent the data you have selected:
//*[@id="site-main"]/div/div/div[2]/div/table/tbody/tr[1]/td[4]/a
Challenge 3.1: Scrape Emails
Which path would you have to provide to Scraper to get the emails in one column?
Solution
You should get a column with emails with any of following paths after hitting scrape:
`*[4]/a or ./td[4]/a`Note that Scraper gave you a starting path based on what you have scraped
//tr[td], so you have only to add the continuation of it. In order to tell Scraper extension we are only interested in the emails, we will have to indicate the data that is in the fourth <td> Table Data Cell Element and add the specific path to the email address/a(anchor element). Don’t forget the dot (.) or the (*) in the beginning of the Xpath expression. As we learned in the previous lesson, it is how you tell the path to select the current context node and to match the element node, respectively.You can remove the contact column now and copy the output to the clipboard.
Let’s scrape a different website
Now let’s turn to the Jewish Studies webpage www.jewishstudies.ucsb.edu/people for practicing XPath queries a little bit more.
Note that the profiles on this webpage are laid out differently from the first example. Here, the information is not displayed in well-defined rows and columns. So, when we scrape the webpage, we should get one row per faculty with only one string of data.
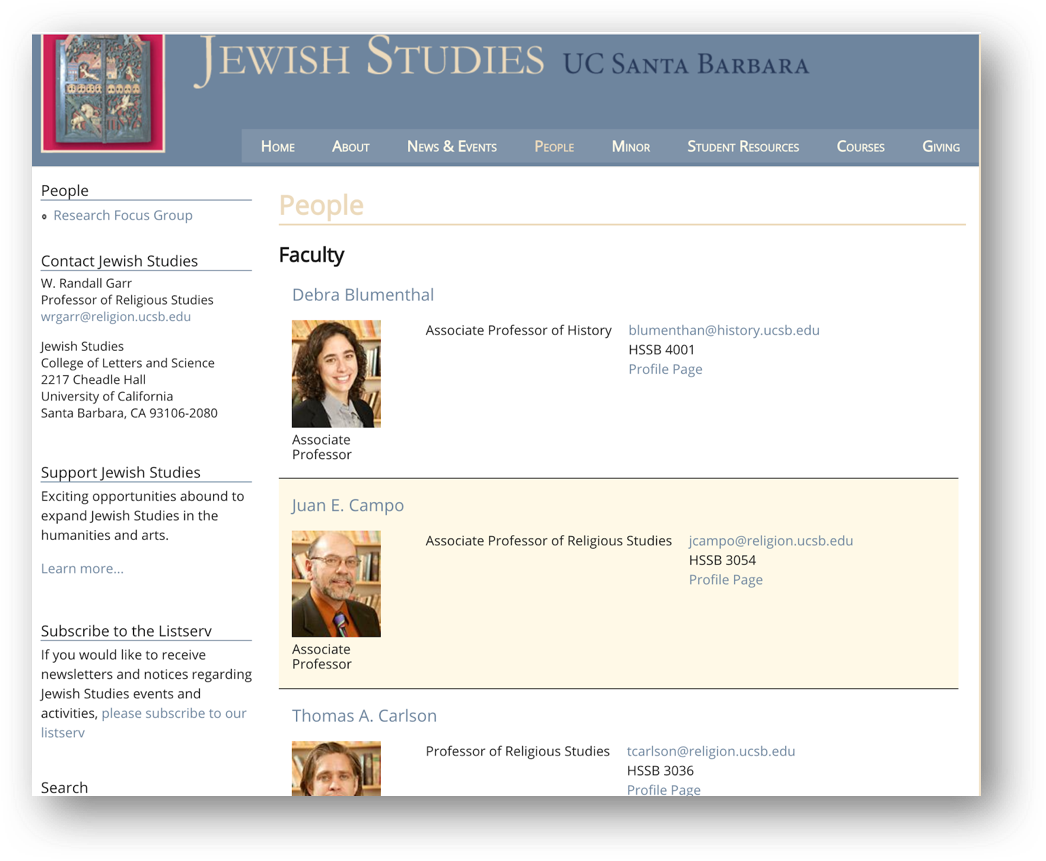

If we want to have this data in a more reusable format, we will have to create columns indicating the exact path we want to scrape the data from, considering that these paths will be a continuation of the one highlighted in the image above.
For this particular case, we want to have four columns:
| 1. Name | 2. Email | 3. Position | 4. Office |
Using the function to inspect where the element is located on the webpage, identify the correct paths, and scrape the information we need.
For the first column “Name” we will have to inspect where the name is located to get the right path to it.
Select one of the Faculty names > right-click > inspect. It will open the developer window as indicated below:
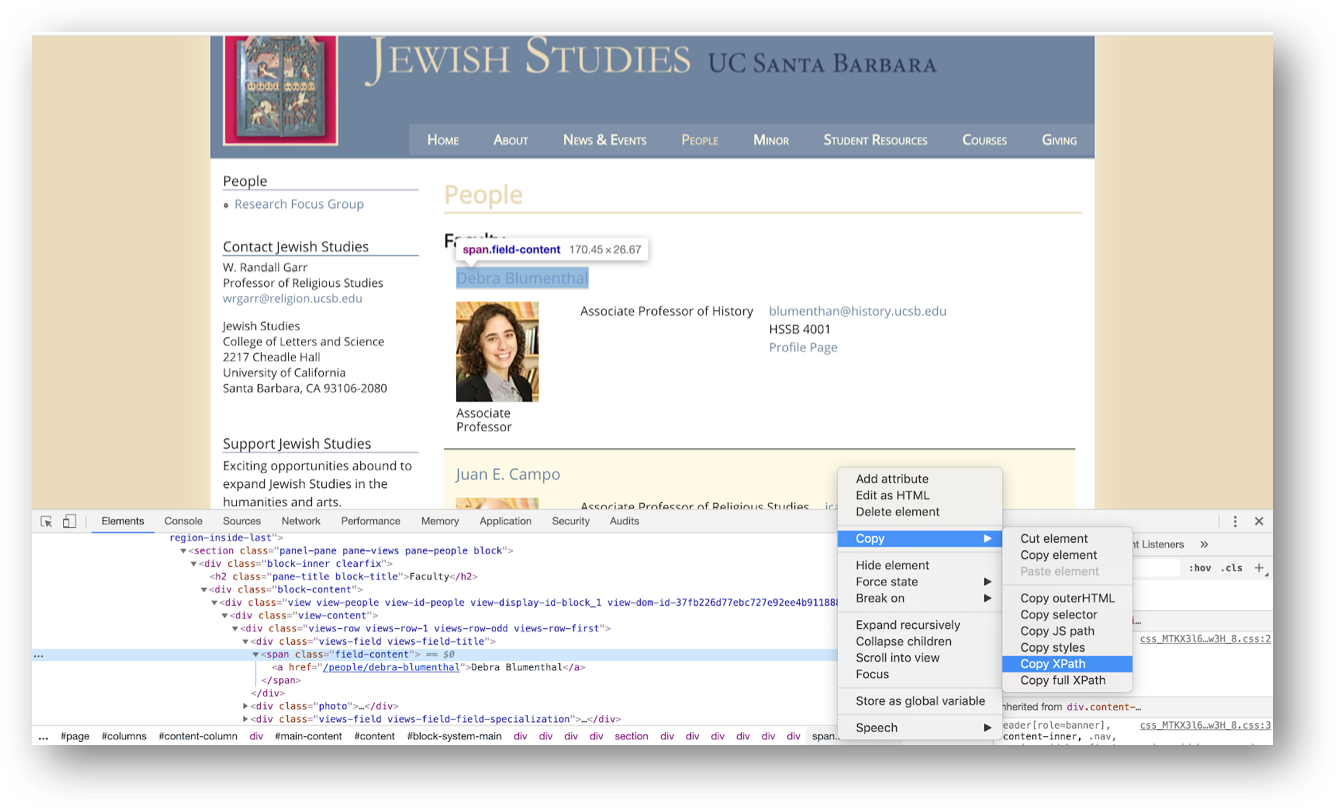
In the developer tools window select the html element containing the faculty name, right-click, then choose Copy Xpath.
You should get this path:
//*[@id="block-system-main"]/div/div/div/div/section[1]/div/div/div/div/div[1]/div[1]/span
Note
You only have to specify in the expression things that are not included in the original XPath automatically created by Scraper. Compare the two and see how we can express the path to Scraper.
Challenge 3.2: Why do both these Xpaths work?
Question: In this case, either of the following paths would work. Do you know why?:
./div[1]/span ./div/spanAlternatively, you can also get it right if you use:
./div/span/a ./div[1]/span/aSolution
The
/spanindicates the inline text of a document. If you provide the extra/a(anchor element) you are telling Scraper to get the information that is in another child node, which happens to also include the faculty name as an anchor to the faculty biopage. Including[1]or not does not change the outcome because there is only one division class within the division block-level for each of the faculty profiles.
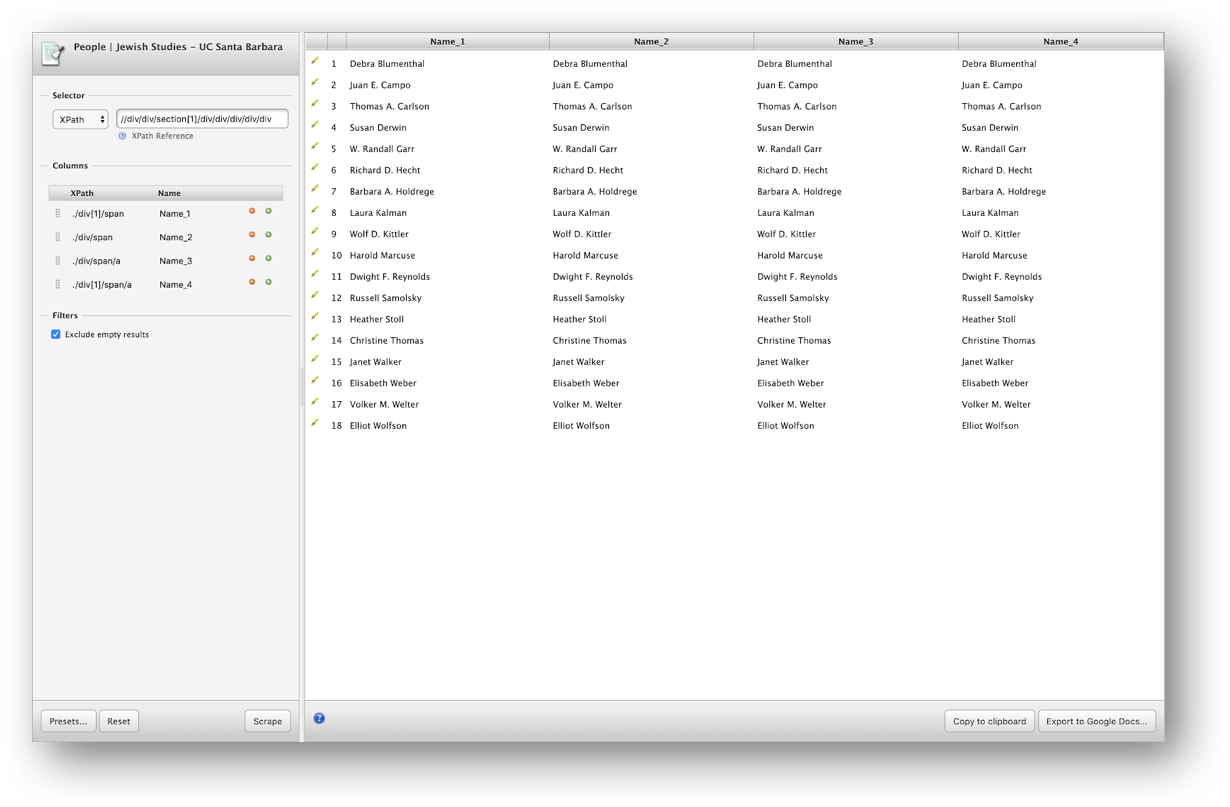
Challenge 3.3: Scrape Three Columns
Now that you have learned how to get the right path to create columns for names, follow the same steps to get the three other columns Emails, Position, and Office.
Solution
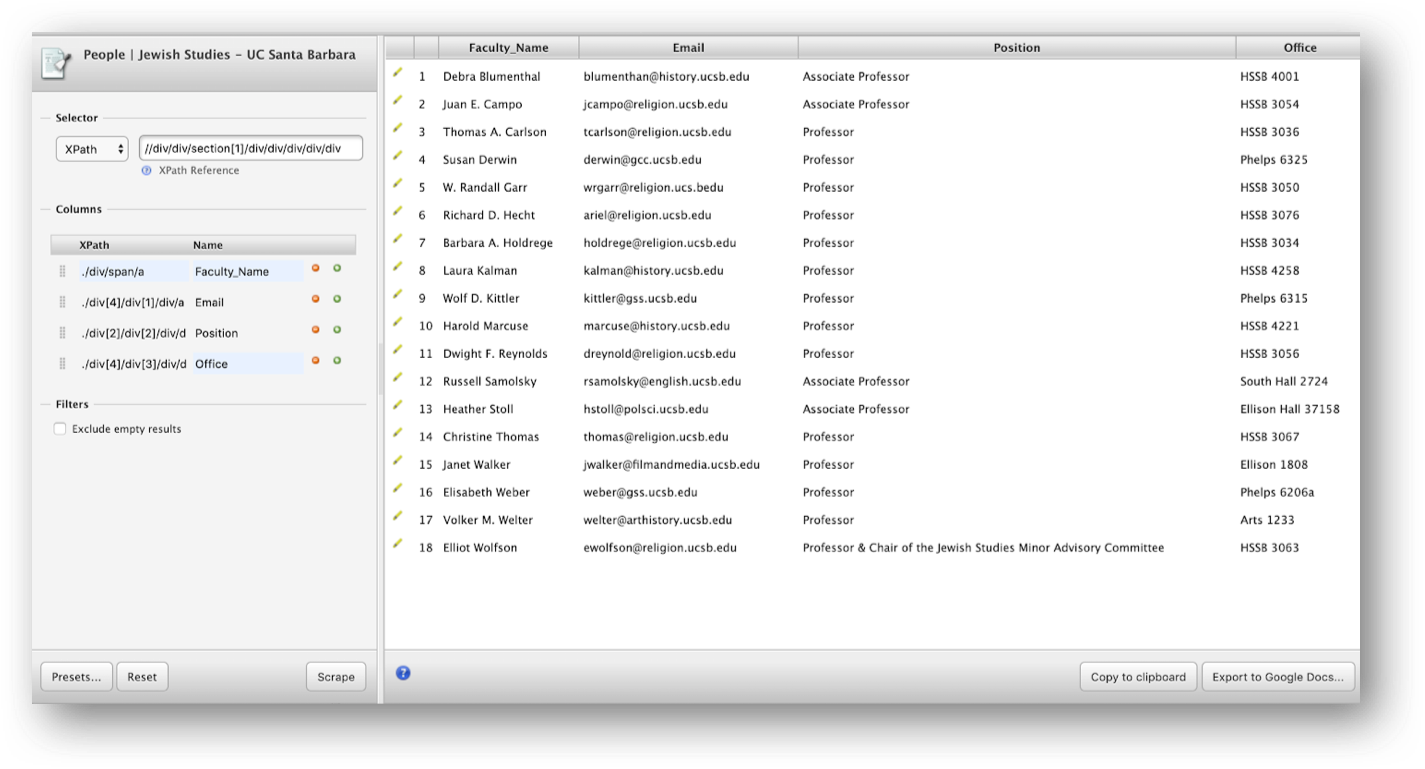
After completing all steps you should have one of the following results rendering to correct scraping outputs:
Email: ./div/span/a or ./div[4]/div[1]/div/a Position ./div[2]/div[2]/div/div/ul/li or ./div[2]/div[2]/div/div or ./div/div/div/div/ul/li or ./div/div/p (If you selected position and specialization) Office: ./div/div[3]/div/div/ul/li or ./div[4]/div[3]/div/div/ul/li
Concat Function
Let’s look at another XPath function called concat() that can be used to concatenate things. This function basically joins two or more strings into one. If we want to scrape the names along the bio web pages for all faculty we can take the following steps:
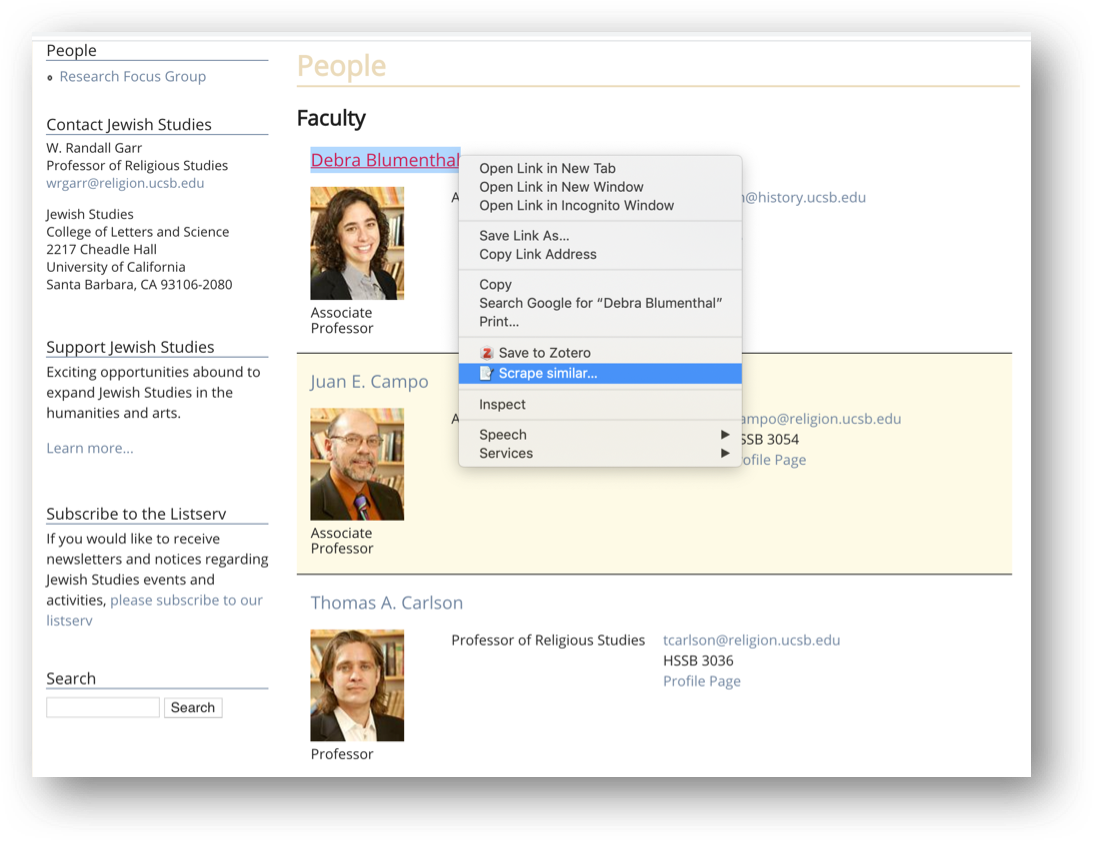
This extracts the URLs, but as luck would have it, those URLs are relative to the list page (i.e. they are missing https://www.jewishstudies.ucsb.edu).
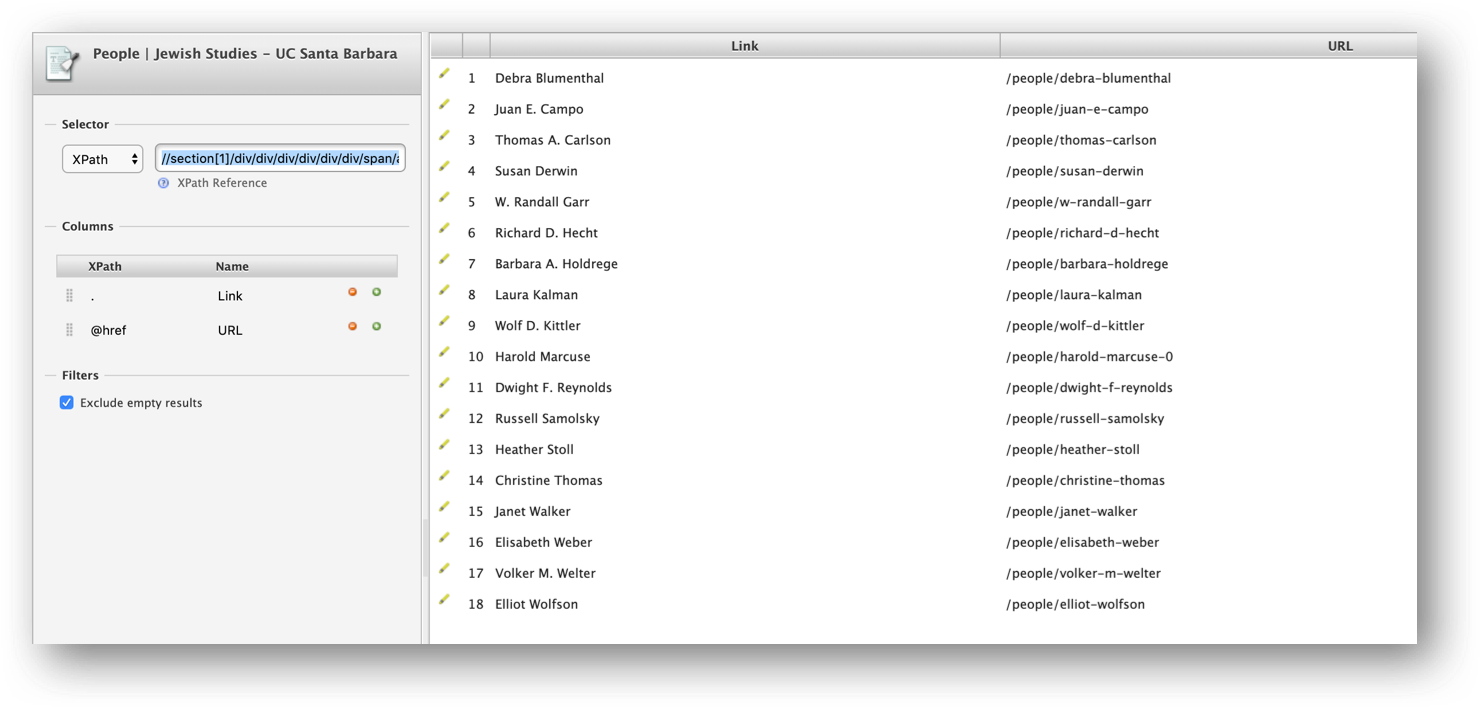
We can create a new column and use the concat() XPath function to construct the full URLs to faculty bio pages, using the following expression:
concat('https://www.jewishstudies.ucsb.edu',@href)
Note that the XPath expression basically tells Scraper what should be placed before @href
Challenge 3.4: Applying
concatfunctionLet’s say you want to add automatically include
Dr.before all faculty names, how would you do that using theconcat()XPath functionSolution
concat('Dr. ', .)If you rename and reorder columns you should have this final output
Other free Chrome extensions to scrape data from websites:
Key Points
Data that is relatively well structured (in a table) is relatively easily to scrape.
More often than not, web scraping tools need to be told what to scrape.
XPath can be used to define what information to scrape, and how to structure it.
More advanced data cleaning operations are best done in a subsequent step.