Web Scraping using Xpath and Chrome Extension: Scraping using the import.io service
questions:
- “How can use the results of one scraper (e.g. a list of URLs) as input for a second one?” objectives:
- “Introduce the import.io web service.”
- “Use import.io to chain scrapers.”
- “Schedule scrapers to run automatically” keypoints:
- “It is possible to use a list of URLs scraped from one page to scrape data on each of the URLs.”
- “Web-based scrapers such as import.io allow scrapes to be scheduled.”
FIXME - Finish write up of this section.
Going back to the Ontario MPP example.
So we have a list of MPPs, which each have an URL to a detail page. What if we want a spreadsheet that includes some of the information from that detail page.
We can write a first scraper to get the URLs (we did so before) Then a second one for the detailed information.
Scraper cannot do that. We need to use a bit more advanced tools.
import.io is a fairly powerful web-based scraping tool that has a nice graphical interface to define what elements to scrape from a page.
They have a number of plans, the free one allows users to scrape up to 500 URLs per month.
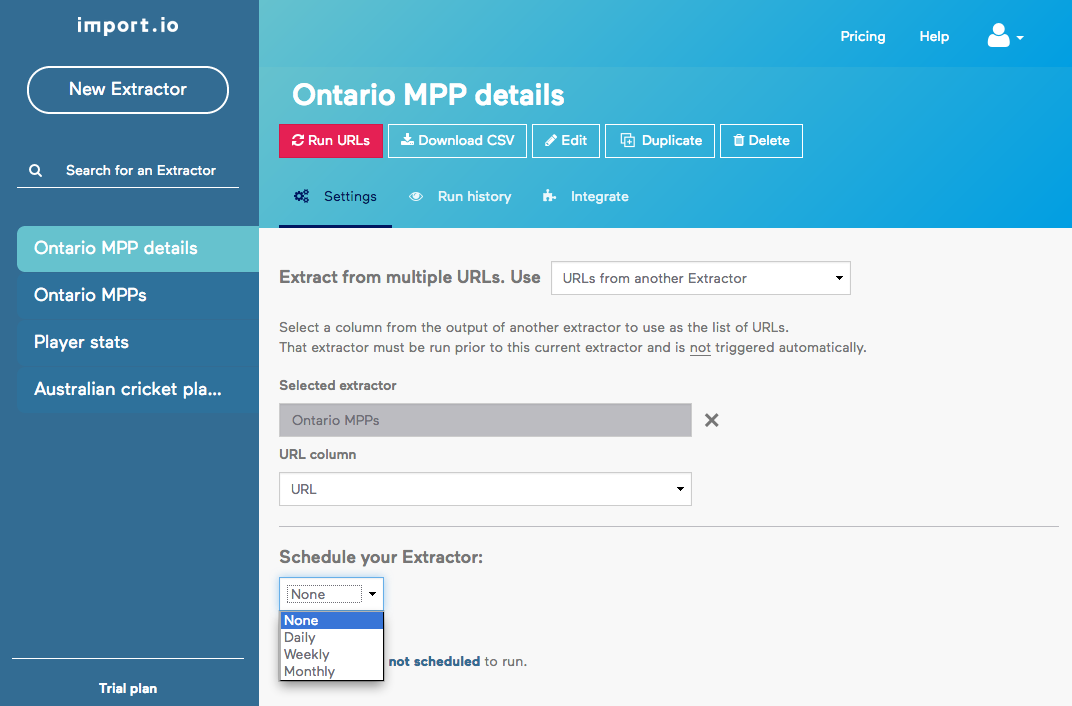
Step 1: Scrape a list of URLs
Once we have logged in to import.io, we can create a new scraper in minutes. Let’s add one on the Ontario MPPs list URL. After a short while, an interface pops with the data that import.io thinks we are interested in scraping. We can toggle from that list view to an overlay of the original web page that allows us to graphically select the data to scrape:
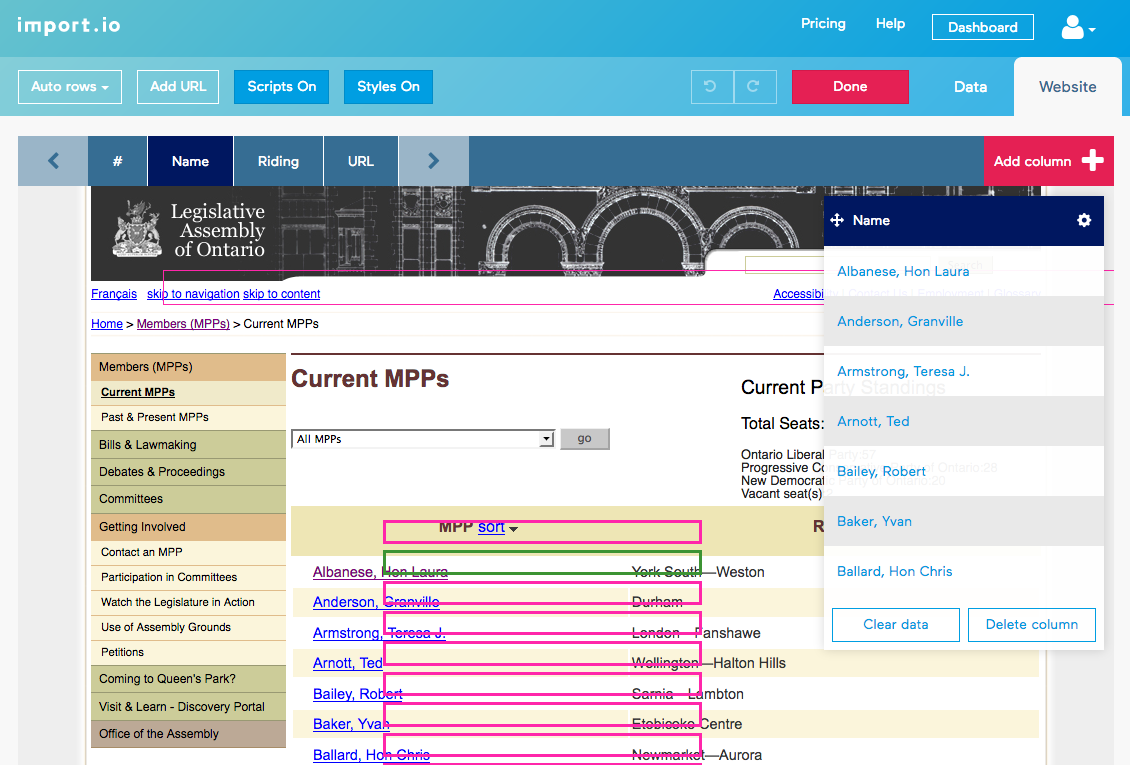
We can see that the MPP name has been captured, including the hyperlink to the detailed page. This is nice for on-screen display, but if we want to reuse that URL, we need it to be in its own column.
Let’s add another column and select the MPP name again, making sure to capture the underlying HTML (including the hyperlink). Then, in the “Data” tab, we can select the “Output HTML” for that new column to see the unformatted data that is being scraped. To further extract only the URL, we have to use a Regular Expression on that column:
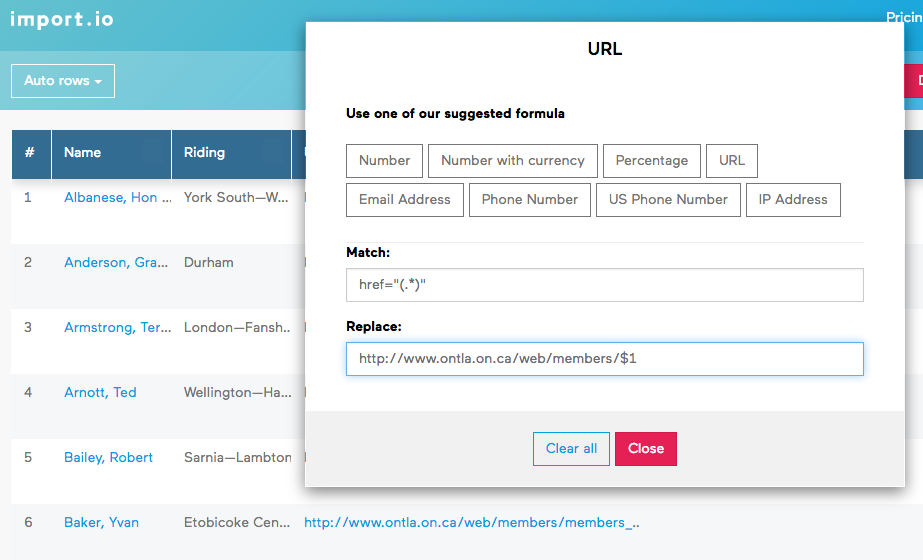
The expression
href="(.*)"
matches everything that is between the double quotes following the href keyword. It is
stored into a temporary variable called $1 which we can reuse on the next line to
output the desired data.
Remembering that the URLs on that page are relative to the list page, we further need to
concatenate http://www.ontla.on.ca/web/members/ in front of the scraped URLs to
get absolute URLs. The resulting expression is
http://www.ontla.on.ca/web/members/$1
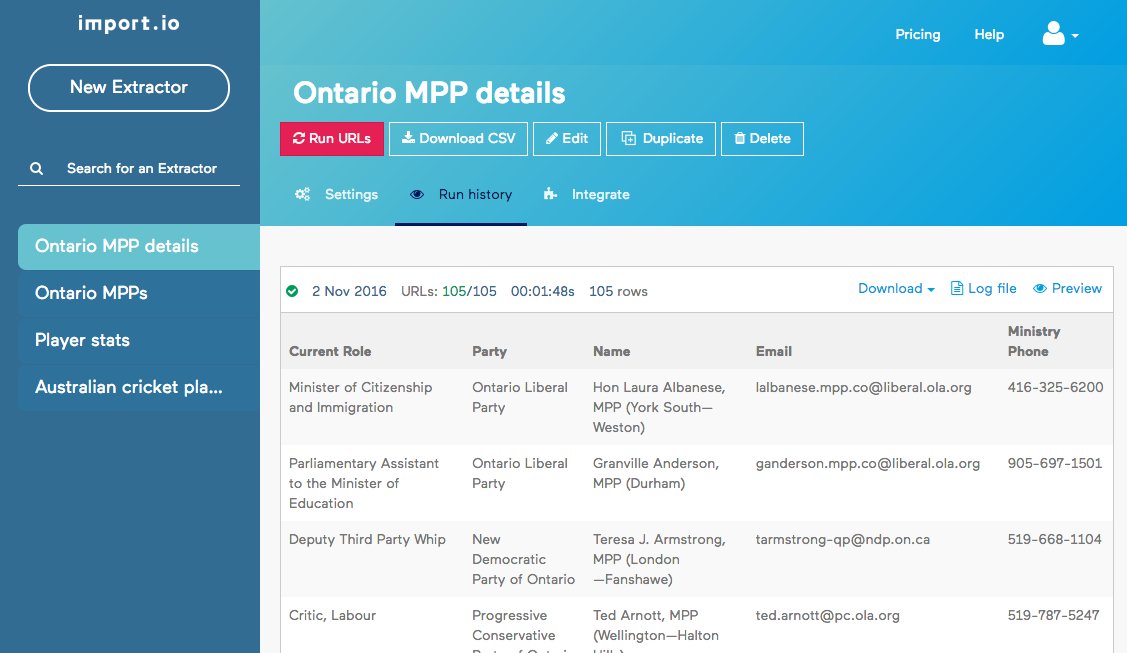
We are now ready to try out our scraper. This is done by clicking on the red “Run URLs” button. Once the scraper has run, we can preview the results directly in the browser:
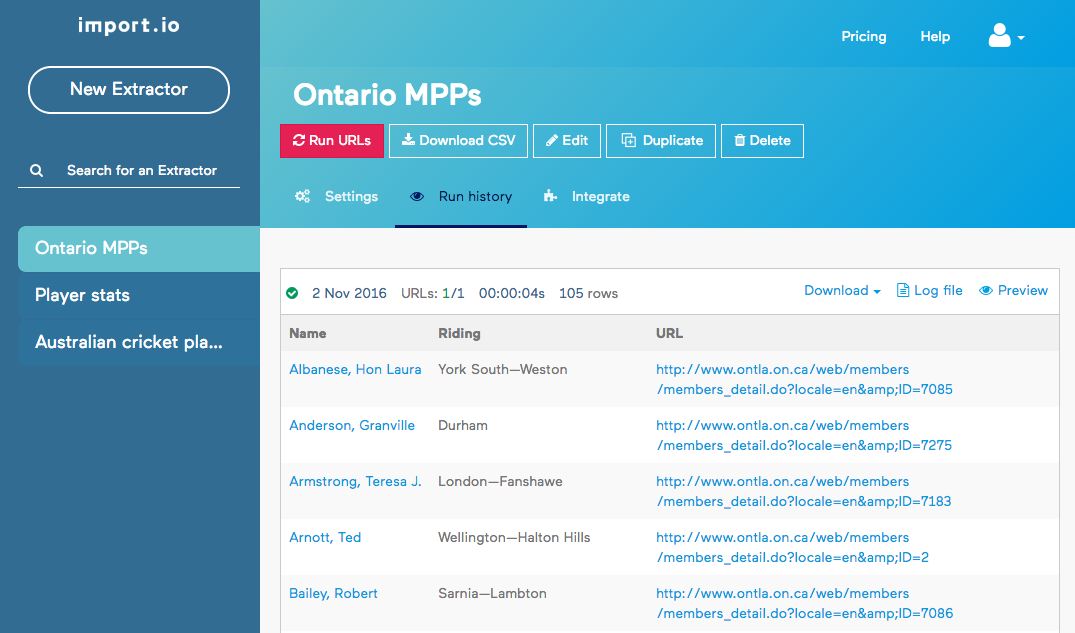
The data can also be downloaded in JSON or CSV format for reuse.
Step 2: Scrape data on the detail view pages
OK now for the 2nd step
We want to use those URLs to harvest data from pages like http://www.ontla.on.ca/web/members/members_detail.do?locale=en&ID=7085
Let’s create a second import.io scraper using that URL
Select the data we are interested in. Say, the email address, the current title, the political party.
Might work for one, what about others? Can we be sure the data is at the same place?
Let’s try it out. import.io allows us to run a scraper on multiple URLs. Let’s put 2-3 in that box.
Run, preview.
We see that some data has not been captured correctly.
Let’s investigate.
Show source / inspect. Use XPath to query elements
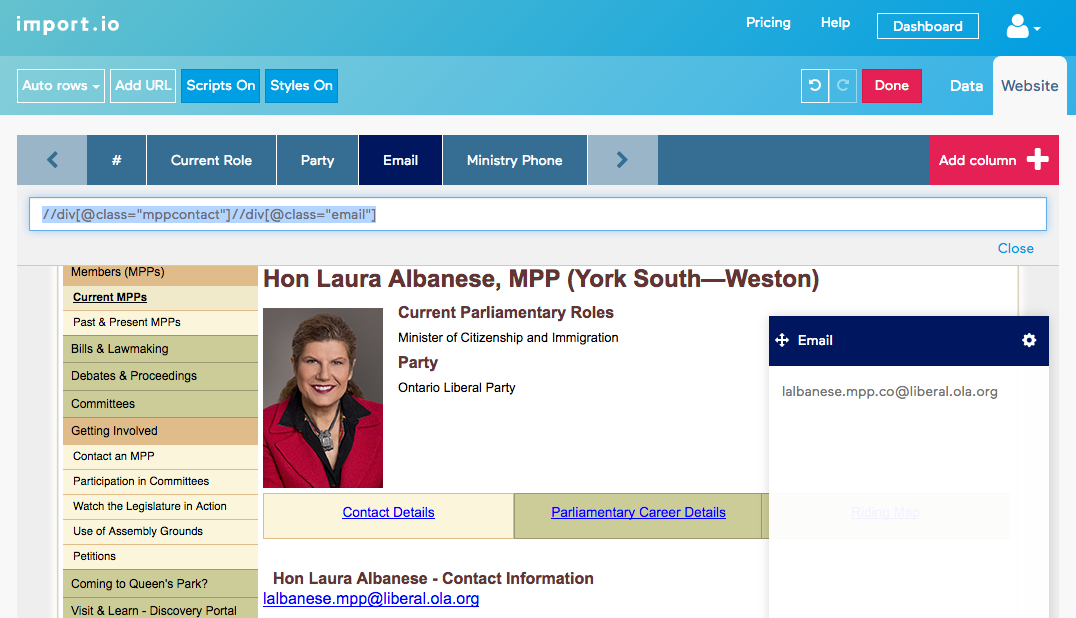
Email:
$x("//div[@class='mppcontact']//div[@class='email']")
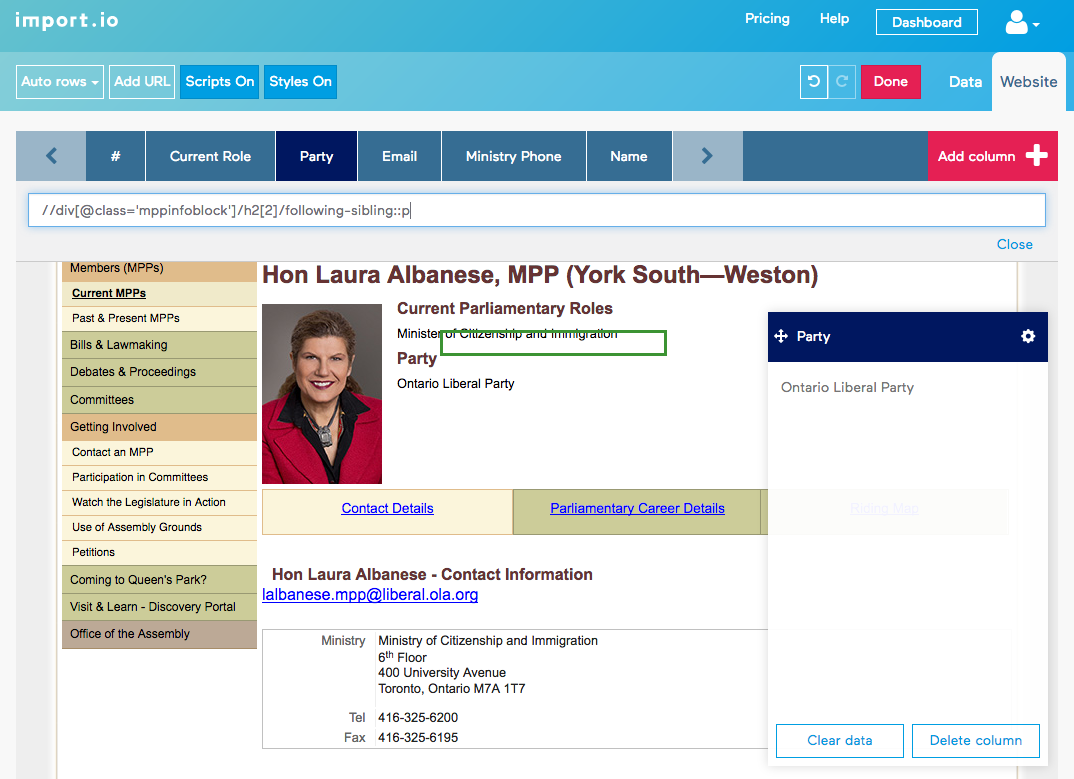
Party:
It’s actually after the second H2 element.
$x("//div[@class='mppinfoblock']/h2[2]/following-sibling::p")
Try it out on multiple URLs. Once we are confident, we can chain scrapers.
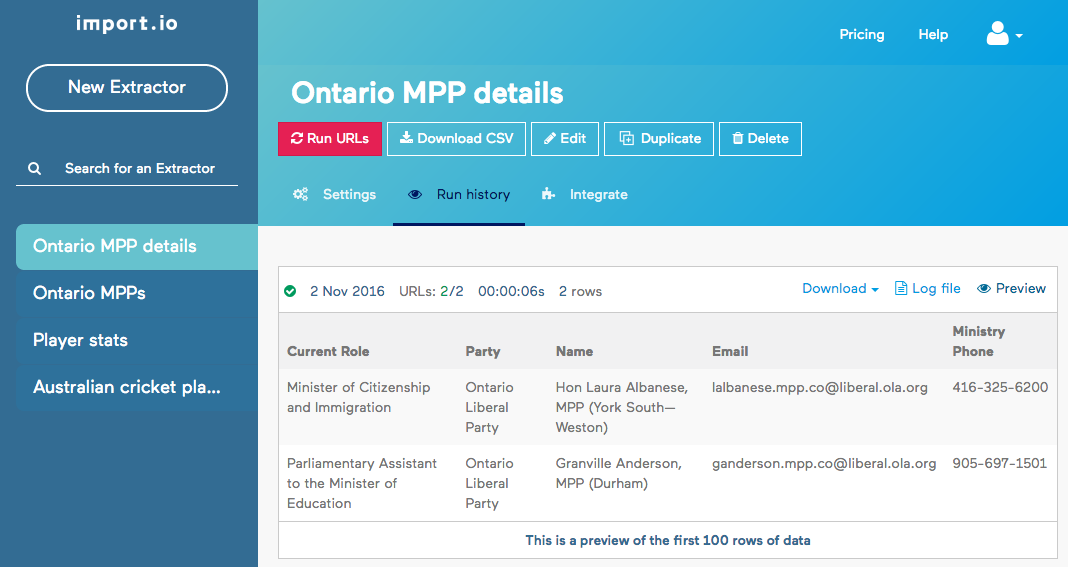
Use the output of one scraper to drive the other: