Content from Hello-Scraping
Last updated on 2024-11-04 | Edit this page
Overview
Questions
- What is behind a website and how can I extract its information?
- What is there to consider before I do web scraping?
Objectives
- Identify the structure and basic components of an HTML document.
- Use BeautifulSoup to locate elements, tags, attributes and text in an HTML document.
- Understand the situations in which web scraping is not suitable for obtaining the desired data.
Introduction
This is part two of an Introduction to Web Scraping workshop we
offered on February 2024. You can refer to those workshop
materials to have a more gentle introduction to scraping using XPath
and the Scraper Chrome extension.
We’ll refresh some of the concepts covered there to have a practical
understanding of how content/data is structured in a website. For that
purpose, we’ll see what Hypertext Markup Language (HTML) is and how it
structures and formats the content using tags. From there,
we’ll use the BeautifulSoup library to parse the HTML content so we can
easily search and access elements of the website we are interested in.
Starting from basic examples, we’ll move to scrape more complex,
real-life websites.
HTML quick overview
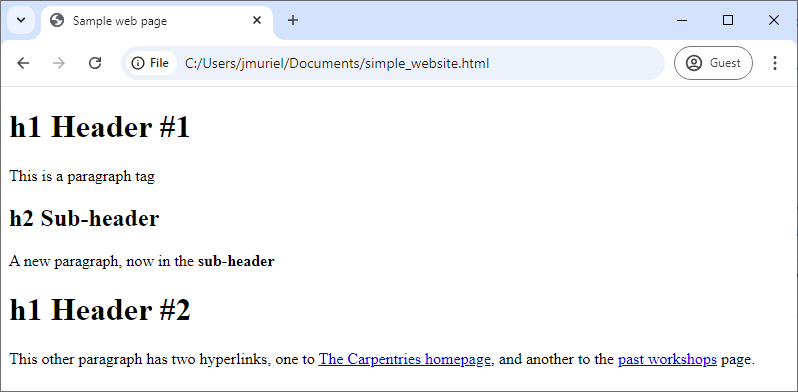
All websites have a Hypertext Markup Language (HTML) document behind them. The following text is HTML for a very simple website, with only three sentences. If you look at it, can you imagine how that website looks?
HTML
<!DOCTYPE html>
<html>
<head>
<title>Sample web page</title>
</head>
<body>
<h1>h1 Header #1</h1>
<p>This is a paragraph tag</p>
<h2>h2 Sub-header</h2>
<p>A new paragraph, now in the <b>sub-header</b></p>
<h1>h1 Header #2</h1>
<p>
This other paragraph has two hyperlinks,
one to <a href="https://carpentries.org/">The Carpentries homepage</a>,
and another to the
<a href="https://carpentries.org/past_workshops/">past workshops</a> page.
</p>
</body>
</html>Well, if you put that text in a file with a .html extension, the job of your web browser when opening the file will be to interpret that (markup) language and display a nicely formatted website.
An HTML document is composed of elements, which can
be identified by tags written inside angle brackets
(< and >). For example, the HTML root
element, which delimits the beginning and end of an HTML document, is
identified by the <html> tag.
Most elements have both a opening and a closing tag, determining the
span of the element. In the previous simple website, we see a head
element that goes from the opening tag <head> up to
the closing tag </head>. Given than an element can be
inside another element, an HTML document has a tree structure, where
every element is a node that can contain child nodes, like the following
image shows.

Finally, we can define or modify the behavior, appeareance, or
functionality of an element by using attributes.
Attributes are inside the opening tag, and consist of a name and a
value, formatted as name="value". For example, in the
previous simple website, we added a hyperlink with the
<a>...</a> tags, but to set the destination URL
we used the href attribute by writing in the opening tag
a href="https://carpentries.org/past_workshops/".
Here is a non-exhaustive list of elements you’ll find in HTML and their purpose:
-
<hmtl>...</html>The root element, which contains the entirety of the document. -
<head>...</head>Contains metadata, for example, the title that the web browser displays. -
<body>...</body>The content that is going to be displayed. -
<h1>...</h1>, <h2>...</h2>, <h3>...</h3>Defines headers of level 1, 2, 3, etc. -
<p>...</p>A paragraph. -
<a href="">...</a>Creates a hyperlink, and we provide the destination URL with thehrefattribute. -
<img src="" alt="">Embedds an image, giving a source to the image with thesrcattribute and specifying alternate text withalt. -
<table>...</table>, <th>...</th>, <tr>...</tr>, <td>...</td>Defines a table, that as children will have a header (defined insideth), rows (defined insidetr), and a cell inside a row (astd). -
<div>...</div>Is used to group sections of HTML content. -
<script>...</script>Embeds or references JavaScript code.
In the previous list we’ve described some attributes specific for the
hyperlink elements (<a>) and the image elements
(<img>), but there are a few other global attributes
that most HTML elements can have and are useful to identify specific
elements when doing web scraping:
-
id=""Assigns a unique identifier to an element, which cannot be repeated in the entire HTML document -
title=""Provides extra information, displayed as a tooltip when the user hovers over the element. -
class=""Is used to apply a similar styling to multiple elements at once.
To summarize, an element is identified by tags, and we can assign properties to an element by using attributes. Knowing this about HTML will make our lifes easier when trying to get some specific data from a website.
Parsing HTML with BeautifulSoup
Now that we know how a website is structured, we can start extracting information from it. The BeautifulSoup package is our main tool for that task, as it will parse the HTML so we can search and access the elements of interest in a programmatic way.
To see how this package works, we’ll use the simple website example we showed before. As our first step, we will load the BeautifulSoup package, along with Pandas.
Let’s get the HTML content inside a string variable called
example_html
PYTHON
example_html = """
<!DOCTYPE html>
<html>
<head>
<title>Sample web page</title>
</head>
<body>
<h1>h1 Header #1</h1>
<p>This is a paragraph tag</p>
<h2>h2 Sub-header</h2>
<p>A new paragraph, now in the <b>sub-header</b></p>
<h1>h1 Header #2</h1>
<p>
This other paragraph has two hyperlinks,
one to <a href="https://carpentries.org/">The Carpentries homepage</a>,
and another to the
<a href="https://carpentries.org/past_workshops/">past workshops</a> page.
</p>
</body>
</html>
"""We parse this HTML using the BeautifulSoup() function we
imported, specifying that we want to use the html.parser.
This object will represent the document as a nested data structure,
similar to a tree as we mentioned before. If we use the
.prettify() method on this object, we can see the nested
structure, as inner elements will be indented to the right.
OUTPUT
<!DOCTYPE html>
<html>
<head>
<title>
Sample web page
</title>
</head>
<body>
<h1>
h1 Header #1
</h1>
<p>
This is a paragraph tag
</p>
<h2>
h2 Sub-header
</h2>
<p>
A new paragraph, now in the
<b>
sub-header
</b>
</p>
<h1>
h1 Header #2
</h1>
<p>
This other paragraph has two hyperlinks, one to
<a href="https://carpentries.org/">
The Carpentries homepage
</a>
, and another to the
<a href="https://carpentries.org/past_workshops/">
past workshops
</a>
.
</p>
</body>
</html>Now that our soup variable holds the parsed document, we
can use the .find() and .find_all() methods.
.find() will search the tag that we specify, and return the
entire element, including the starting and closing tags. If there are
multiple elements with the same tag, .find() will only
return the first one. If you want to return all the elements that match
your search, you’d want to use .find_all() instead, which
will return them in a list. Additionally, to return the text contained
in a given element and all its children, you’d use
.get_text(). Below you can see how all these commands play
out in our simple website example.
PYTHON
print("1.", soup.find('title'))
print("2.", soup.find('title').get_text())
print("3.", soup.find('h1').get_text())
print("4.", soup.find_all('h1'))
print("5.", soup.find_all('a'))
print("6.", soup.get_text())OUTPUT
1. <title>Sample web page</title>
2. Sample web page
3. h1 Header #1
4. [<h1>h1 Header #1</h1>, <h1>h1 Header #2</h1>]
5. [<a href="https://carpentries.org/">The Carpentries homepage</a>, <a href="https://carpentries.org/past_workshops/">past workshops</a>]
6.
Sample web page
h1 Header #1
This is a paragraph tag
h2 Sub-header
A new paragraph, now in the sub-header
h1 Header #2
This other paragraph has two hyperlinks, one to The Carpentries homepage, and another to the past workshops.
How would you extract all hyperlinks identified with
<a> tags? In our example, we see that there are only
two hyperlinks, and we could extract them in a list using the
.find_all('a') method.
OUTPUT
Number of hyperlinks found: 2
[<a href="https://carpentries.org/">The Carpentries homepage</a>, <a href="https://carpentries.org/past_workshops/">past workshops</a>]To access the value of a given attribute in an element, for example
the value of the href attribute in
<a href="">, we would use square brackets and the
name of the attribute (['href']), just like how in a Python
dictionary we would access the value using the respective key. Let’s
make a loop that prints only the URL for each hyperlink we have in our
example.
OUTPUT
https://carpentries.org/
https://carpentries.org/past_workshops/Challenge
Create a Python dictionary that has the following three items, containing information about the first hyperlink in the HTML of our example.
One way of completing the exercise is as follows.
PYTHON
first_link = {
'element': str(soup.find('a')),
'url': soup.find('a')['href'],
'text': soup.find('a').get_text()
}An alternate but similar way is to store the tag found for not
calling multiple times soup.find('a'), and also creating
first an empty dictionary and append to it the keys and values we want,
as this will be useful when we do this multiple times in a for loop.
To finish this introduction on HTML and BeautifulSoup, let’s create
code for extracting in a structured way all the hyperlink elements,
their destination URL and the text displayed for link. For that, let’s
use the links variable that we created before as
links = soup.find_all('a'). We’ll loop over each hyperlink
element found, storing for each the three pieces of information we want
in a dictionary, and finally appending that dictionary to a list called
list_of_dicts. At the end we will have a list with two
elements, that we can transform to a Pandas dataframe.
PYTHON
links = soup.find_all('a')
list_of_dicts = []
for item in links:
dict_a = {}
dict_a['element'] = str(item)
dict_a['url'] = item['href']
dict_a['text'] = item.get_text()
list_of_dicts.append(dict_a)
links_df = pd.DataFrame(list_of_dicts)
print(links_df)OUTPUT
element \
0 <a href="https://carpentries.org/">The Carpent...
1 <a href="https://carpentries.org/past_workshop...
url text
0 https://carpentries.org/ The Carpentries homepage
1 https://carpentries.org/past_workshops/ past workshops You’ll find more useful information about the BeautifulSoup package and how to use all its methods in the Beautiful Soup Documentation website.
The rights, wrongs, and legal barriers to scraping
The internet is no longer what it used to be. Once an open and boundless source of information, the web has become an invaluable pool of data, widely used by companies to train machine learning and generative AI models. Now, social media platforms and other website owners have either recognized the potential for profit and licensed their data or have become overwhelmed by bots crawling their sites and straining their server resources.
For this reason, it’s now more common to see that a website’s Terms of Service (TOS) explicitly prohibits web scraping. If we want to avoid getting into trouble, we need to carefully check the TOS of your website of interest as well as its ‘robots.txt’ file. You should be able to find both using your preferred search engine, but you may directly go to the latter by appending ‘/robots.txt’ at the root URL of the website (e.g. for Facebook you’ll find it in ‘https://facebook.com/robots.txt’, not in any other URL like ‘https://facebook.com/user/robots.txt’).
Challenge
Visit Facebook’s Terms of Service and its robots.txt file. What do they say about web scraping or collecting data using automated means? Compare it to Reddit’s TOS and Reddit’s robots.txt.
Besides checking the website’s policies, you should also be aware of the legislation applicable to your location regarding copyright and data privacy laws. If you plan to start harvesting a large amount of data for research or commercial purposes, you should probably seek legal advice first. If you work in a university, chances are it has a copyright office that will help you sort out the legal aspects of your project. The university library is often the best place to start looking for help on copyright.
To conclude, here is a brief code of conduct you should consider when doing web scraping:
- Ask nicely if you can access the data in another way. If your project requires data from a particular organisation, you can try asking them directly if they could provide you what you are looking for, or check if they have an API to access the data. With some luck, they will have the primary data that they used on their website in a structured format, saving you the trouble.
- Don’t download copies of documents that are clearly not public. For example, academic journal publishers often have very strict rules about what you can and what you cannot do with their databases. Mass downloading article PDFs is probably prohibited and can put you (or at the very least your friendly university librarian) in trouble. If your project requires local copies of documents (e.g. for text mining projects), special agreements can be reached with the publisher. The library is a good place to start investigating something like that.
- Check your local legislation. For example, certain countries have laws protecting personal information such as email addresses and phone numbers. Scraping such information, even from publicly avaialable web sites, can be illegal (e.g. in Australia).
- Don’t share downloaded content illegally. Scraping for personal purposes is usually OK, even if it is copyrighted information, as it could fall under the fair use provision of the intellectual property legislation. However, sharing data for which you don’t hold the right to share is illegal.
- Share what you can. If the data you scraped is in the public domain or you got permission to share it, then put it out there for other people to reuse it (e.g. on datahub.io). If you wrote a web scraper to access it, share its code (e.g. on GitHub) so that others can benefit from it.
- Publish your own data in a reusable way. Don’t force others to write their own scrapers to get at your data. Use open and software-agnostic formats (e.g. JSON, XML), provide metadata (data about your data: where it came from, what it represents, how to use it, etc.) and make sure it can be indexed by search engines so that people can find it.
- Don’t break the Internet. Not all web sites are designed to withstand thousands of requests per second. If you are writing a recursive scraper (i.e. that follows hyperlinks), test it on a smaller dataset first to make sure it does what it is supposed to do. Adjust the settings of your scraper to allow for a delay between requests. More on this topic in the next episode.
Key Points
- Every website has an HTML document behind it that gives a structure to its content.
- An HTML is composed of elements, which usually have a opening
<tag>and a closing</tag>. - Elements can have different properties, assigned by attributes in
the form of
<tag attribute_name="value">. - We can parse any HTML document with
BeautifulSoup()and find elements using the.find()and.find_all()methods. - We can access the text of an element using the
.get_text()method and the attribute values as we do with Python dictionaries (element["attribute_name"]). - We must be careful to not tresspass the Terms of Service (TOS) of the website we are scraping.
Content from Scraping a real website
Last updated on 2024-11-04 | Edit this page
Overview
Questions
- How can I get the data and information from a real website?
- How can I start automating my web scraping tasks?
Objectives
- Use the
requestspackage to get the HTML document behind a website. - Navigate the tree structure behind an HTML document to extract the information we need.
- Know how to avoid being blocked by sending too much requests to a website.
“Requests” the website HTML
In the previous episode we used a simple HTML document, not an actual
website. Now that we move to more real, complex escenario, we need to
add another package to our toolbox, the requests package.
For the purpose of this web scraping lesson, we will only use
requests to get the HTML behind a website. However, there’s
a lot of extra functionality that we are not covering but you can find
in the Requests
package documentation.
We’ll be scraping The Carpentries website, https://carpentries.org/, and
specifically, the list of upcoming and past workshop you can find at the
bottom. For that, first we’ll load the requests package and
then use the code .get().text to store the HTML document of
the website. Furthermore, to simplify our navigation through the HTML
document, we will use the Regular
Expressions re module to remove all new line characters
(“”) and their surrounding whitespaces. You can think of removing new
lines as a preprocessing or cleaning step, but in this lesson we won’t
be explaining the intricacies of regular expressions. For that, you can
refer to this introductory explanation on the Library
Carpentry.
PYTHON
import requests
import re
url = 'https://carpentries.org/'
req = requests.get(url).text
cleaned_req = re.sub(r'\s*\n\s*', '', req).strip()
print(cleaned_req[0:1000])OUTPUT
<!doctype html><html class="no-js" lang="en"><head><meta charset="utf-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>The Carpentries</title><link rel="stylesheet" type="text/css" href="https://carpentries.org/assets/css/styles_feeling_responsive.css"><script src="https://carpentries.org/assets/js/modernizr.min.js"></script><!-- matomo --><script src="https://carpentries.org/assets/js/matomo-analytics.js"></script><link href="https://fonts.googleapis.com/css?family=Lato:400,400i,700,700i|Roboto:400,400i,700,700i&display=swap" rel="stylesheet"><!-- Search Engine Optimization --><meta name="description" content="The Carpentries is a fiscally sponsored project of Community Initiatives, a registered 501(c)3 non-profit organisation based in California, USA. We are a global community teaching foundational computational and data science skills to researchers in academia, industry and government."><link rel="canonical" href="https://carpentries.org/index.html"><We truncated to print only the first 1000 characters of the document,
as it is too long, but we can see it is HTML and has some elements we
didn’t see in the example of the previous episode, like those identified
with the <meta>, <link> and
<script> tags.
There’s another way to see the HTML document behind a website, directly from your web browser. Using Google Chrome, you can right-click in any part of the website (on a Mac, press and hold the Control key in your keyboard while you click), and from the pop-up menu, click ‘View page source’, as the next image shows. If the ‘View page source’ option didn’t appear for you, try clicking in another part of the website. A new tab will open with the HTML document for the website you were in.

In the HTML page source on your browser you can scroll down and look
for the second-level header (<h2>) with the text
“Upcoming Carpentries Workshops”. Or more easily, you can use the Find
Bar (Ctrl + F on Windows and Command + F on Mac) to search for “Upcoming
Carpentries Workshops”. Just right down of that header we have the table
element we are interested in, which starts with the opening tag
<table class="table table-striped" style="width: 100%;">.
Inside that element we see nested different elements familiar for a
table, the rows (<tr>) and the cells for each row
(<td>), and additionally the image
(<img>) and hyperlink (<a>)
elements.
Finding the information we want
Now, going back to our coding, we left off on getting the HTML behind
the website using requests, and stored it on the variable
called req. From here we can proceed with BeautifulSoup as
we learned in the previous episode, using the
BeautifulSoup() function to parse our HTML, as the
following code block shows. With the parsed document, we can use the
.find() or find_all() methods to find the
table element.
PYTHON
soup = BeautifulSoup(cleaned_req, 'html.parser')
tables_by_tag = soup.find_all('table')
print("Number of table elements found: ", len(tables_by_tag))
print("Printing only the first 1000 characters of the table element: \n", str(tables_by_tag[0])[0:1000])OUTPUT
Number of table elements found: 1
Printing only the first 1000 characters of the table element:
<table class="table table-striped" style="width: 100%;"><tr><td><img alt="swc logo" class="flags" height="24" src="https://carpentries.org/assets/img/logos/swc.svg" title="swc workshop" width="24"/></td><td><img alt="mx" class="flags" src="https://carpentries.org/assets/img/flags/24/mx.png" title="MX"><img alt="globe image" class="flags" src="https://carpentries.org/assets/img/flags/24/w3.png" title="Online"><a href="https://galn3x.github.io/-2024-10-28-Metagenomics-online/">Nodo Nacional de Bioinformática UNAM</a><br><b>Instructors:</b> César Aguilar, Diana Oaxaca, Nelly Selem-Mojica<br><b>Helpers:</b> Andreas Chavez, José Manuel Villalobos Escobedo, Aaron Espinosa Jaime, Andrés Arredondo, Mirna Vázquez Rosas-Landa, David Alberto GarcÃa-Estrada</br></br></img></img></td><td>Oct 28 - Oct 31, 2024</td></tr><tr><td><img alt="dc logo" class="flags" height="24" src="https://carpentries.org/assets/img/logos/dc.svg" title="dc workshop" width="24"/></td><td><img alt="de" class="flags" sFrom our output we see that there was only one table element in the entire HTML, which corresponds to the table we are looking for. The output you see in the previous code block will be different from what you have in your computer, as the data in the upcoming workshops table is continously updated.
Besides searching elements using tags, sometimes it will be useful to
search using attributes, like id or class. For
example, we can see the table element has a class attribute with two
values “table table-striped”, which identifies all possible elements
with similar styling. Therefore, we could have the same result than
before using the class_ argument on the
.find_all() method as follows.
Now that we know there is only one table element, we can start
working with it directly by storing the first and only item in the
tables_by_tag result set into another variable, which we
will call just workshops. We can see that we moved from
working with a “ResultSet” object to a “Tag” object, which we can start
working with to extract information from each row and cell.
PYTHON
print("Before: ", type(tables_by_tag))
workshops_table = tables_by_tag[0]
print("After:", type(workshops_table))
print("Element type:", workshops_table.name)OUTPUT
Before: <class 'bs4.element.ResultSet'>
After: <class 'bs4.element.Tag'>
Element type: tableNavigating the tree
If we use the prettify() method on the
workshops_table variable, we see that this table element
has a nested tree structure. On the first level is the
<table> tag. Inside that, we have rows
<tr>, and inside rows we have table data cells
<td>. We can start to identify certain information we
may be interested in, for example:
- What type of workshop was it (‘swc’ for Software Carpentry, ‘dc’ for
Data Carpentry, ‘lc’ for Library Carpentry, and ‘cp’ for workshops based
on The Carpentries curriculum). We find this in the first
<td>tag, or said in a different way, in the first cell of the row. - In what country was the workshop held. We can see the two-letter country code in the second cell of the row.
- The URL to the workshop website, which will contain additional
information. It is also contained in the second cell of the row, as the
hrefattribute of the<a>tag. - The institution that is hosting the workshop. Also in the second
<td>, in the text of the hyperlink<a>tag. - The name of instructors and helpers involved in the workshop.
- The dates of the workshop, on the third and final cell.
OUTPUT
<table class="table table-striped" style="width: 100%;">
<tr>
<td>
<img alt="swc logo" class="flags" height="24" src="https://carpentries.org/assets/img/logos/swc.svg" title="swc workshop" width="24"/>
</td>
<td>
<img alt="mx" class="flags" src="https://carpentries.org/assets/img/flags/24/mx.png" title="MX">
<img alt="globe image" class="flags" src="https://carpentries.org/assets/img/flags/24/w3.png" title="Online">
<a href="https://galn3x.github.io/-2024-10-28-Metagenomics-online/">
Nodo Nacional de Bioinformática UNAM
</a>
<br>
<b>
Instructors:
</b>
César Aguilar, Diana Oaxaca, Nelly Selem-Mojica
<br>
<b>
Helpers:
</b>
Andreas Chavez, José Manuel Villalobos Escobedo, Aaron Espinosa Jaime, Andrés Arredondo, Mirna Vázquez Rosas-Landa, David Alberto GarcÃa-Estrada
</br>
</br>
</img>
</img>
</td>
<td>
Oct 28 - Oct 31, 2024
</td>
</tr>
<tr>
<td>
...
</td>
</tr>
</table>To navigate in this HTML document tree we can use the following
properties of the “bs4.element.Tag” object: .contents (to
access direct children nodes), .parent (to access the
parent node), .next_sibling, and
.previous_sibling (to access the siblings of a node)
methods. For example, if we want to access the second row of the table,
which is the second child of the table element we could use the
following code.
If you go back to the ‘View page source’ of the website, you’ll
notice that the table element is nested inside a
<div class="medium-12 columns"> element, which means
this <div> is the parent of our
<table>. If we needed to, we could access this parent
by using workshops_table.parent.
Now imagine we had selected the second data cell of our fifth row
using workshops_table.contents[4].contents[1], we could
access the third data cell using .next_sibling() or the
first data cell with .previous_sibling().
PYTHON
# Access the fifth row, and from there, the second data cell
row5_cell2 = workshops_table.contents[4].contents[1]
# Access the third cell of the fifth row
row5_cell3 = row5_cell2.next_sibling
# Access the first cell of the fifth row
row5_cell1 = row5_cell2.previous_siblingWhy do we bother to learn all this methods? Depending on you web scraping use case, they might result useful in complex websites. Let’s apply them to extract the information we want about the workshops, for example, to see how many upcoming workshops there are, which corresponds with the number of children the table element has
PYTHON
num_workshops = len(workshops_table.contents)
print("Number of upcoming workshops listed: ", num_workshops)Let’s work to extract data from only the first row, and later we can use a loop to iterate over all the rows of the table.
PYTHON
# Empty dictionary to hold the data
dict_w = {}
# First row of data
first_row = workshops_table.contents[0]
# To get to the first cell
first_cell = first_row.contents[0]
second_cell = first_cell.next_sibling
third_cell = second_cell.next_sibling
# From the first cell, find the <image> tag and get the 'title' attribute, which contains the type of workshop
dict_w['type'] = first_cell.find('img')['title']
# In the second cell, get the country from the 'title' attribute of the <image> tag
dict_w['country'] = second_cell.find('img')['title']
# Now the link to the workshop website is in the 'href' attribute of the <a> tag
dict_w['link'] = second_cell.find('a')['href']
# The institution that hosts the workshop is the text inside that <a> tag
dict_w['link'] = second_cell.find('a').get_text()
# Get all the text from the second cell
dict_w['all_text'] = second_cell.get_text(strip=True)
# Get the dates from the third cell
dict_w['date'] = third_cell.get_text(strip=True)
print(dict_w)OUTPUT
{'type': 'swc workshop',
'country': 'MX',
'link': 'https://galn3x.github.io/-2024-10-28-Metagenomics-online/',
'host': 'Nodo Nacional de Bioinformática UNAM',
'all_text': 'Nodo Nacional de Bioinformática UNAMInstructors:César Aguilar, Diana Oaxaca, Nelly Selem-MojicaHelpers:Andreas Chavez, José Manuel Villalobos Escobedo, Aaron Espinosa Jaime, Andrés Arredondo, Mirna Vázquez Rosas-Landa, David Alberto GarcÃ\xada-Estrada',
'date': 'Oct 28 - Oct 31, 2024'}This was just for one row, but we can iterate over all the rows in the table adding a for loop and appending each dictionary to a list. That list will be transformed to a Pandas dataframe so we can see the results nicely.
PYTHON
list_of_workshops = []
for row in range(num_workshops):
n_row = workshops_table.contents[row]
first_cell = n_row.contents[0]
second_cell = first_cell.next_sibling
third_cell = second_cell.next_sibling
dict_w = {}
dict_w['type'] = first_cell.find('img')['title']
dict_w['country'] = second_cell.find('img')['title']
dict_w['link'] = second_cell.find('a')['href']
dict_w['host'] = second_cell.find('a').get_text()
dict_w['all_text'] = second_cell.get_text(strip=True)
dict_w['date'] = third_cell.get_text(strip=True)
list_of_workshops.append(dict_w)
result_df = pd.DataFrame(list_of_workshops)Great! We’ve finished our first scraping task on a real website.
Please be aware that there are multiple ways of achieving the same
result. For example, instead of using the .contents()
method to access the different rows of the table, we could have used
.find_all('tr') to scan the table and loop through the row
elements. Similarly, instead of moving to the siblings of the first data
cell, we could have used .find_all('td'). Code using that
other approach would look like this. Remember, the results are the
same!
PYTHON
list_of_workshops = []
for row in workshops_table.find_all('tr'):
cells = row.find_all('td')
first_cell = cells[0]
second_cell = cells[1]
third_cell = cells[2]
dict_w = {}
dict_w['type'] = first_cell.find('img')['title']
dict_w['country'] = second_cell.find('img')['title']
dict_w['link'] = second_cell.find('a')['href']
dict_w['host'] = second_cell.find('a').get_text()
dict_w['all_text'] = second_cell.get_text(strip=True)
dict_w['date'] = third_cell.get_text(strip=True)
list_of_workshops.append(dict_w)
upcomingworkshops_df = pd.DataFrame(list_of_workshops)A key takeaway from this exercise is that, when we want to scrape data in a structured way, we have to spend some time getting to know how the website is structured and how we can identify and extract only the elements we are interested in.
Challenge
Extract the same information as in the previous exercise, but this time from the Past Workshops Page at https://carpentries.org/past_workshops/. Which 5 countries have held the most workshops, and how many has each held?
We can reuse directly the code we wrote before, changing only the URL we got the HTML from.
PYTHON
url = 'https://carpentries.org/past_workshops/'
req = requests.get(url).text
cleaned_req = re.sub(r'\s*\n\s*', '', req).strip()
soup = BeautifulSoup(cleaned_req, 'html.parser')
workshops_table = soup.find('table')
list_of_workshops = []
for row in workshops_table.find_all('tr'):
cells = row.find_all('td')
first_cell = cells[0]
second_cell = cells[1]
third_cell = cells[2]
dict_w = {}
dict_w['type'] = first_cell.find('img')['title']
dict_w['country'] = second_cell.find('img')['title']
dict_w['link'] = second_cell.find('a')['href']
dict_w['host'] = second_cell.find('a').get_text()
dict_w['all_text'] = second_cell.get_text(strip=True)
dict_w['date'] = third_cell.get_text(strip=True)
list_of_workshops.append(dict_w)
pastworkshops_df = pd.DataFrame(list_of_workshops)
print('Total number of workshops in the table: ', len(pastworkshops_df))
print('Top 5 of countries by number of workshops held: \n',
pastworkshops_df['location'].value_counts().head())OUTPUT
Total number of workshops in the table: 3830
Top 5 of countries by number of workshops held:
country
US 1837
GB 468
AU 334
CA 225
DE 172
Name: count, dtype: int64Challenge
For a more challenging exercise, try to add to our output dataframe if the workshop was held online or not.
You’ll notice from the website that the online workshops have a world icon next between the country flag and the name of the institution that hosts the workshop.
To start, we can see in the HTML document that the world icon is in
the second data cell of a row. Additionally, for those workshops that
are online, there is an additional image element with these attributes
<img title="Online" alt="globe image" class="flags"/>.
So we could search if the second data cell has an element with an
attribute of title="Online". If it doesn’t, the
.find() method would return nothing, what in Python is
called a “NoneType” data type. So if .find() returns None,
we should fill the respective cell in our dataframe with a “No”, meaning
that the workshop not held online, and in the opposite case fill it with
a “Yes”. Here is a possible code solution, which you would add to the
previous code where we extracted the other data and created the
dataframe.
Automating data collection
Until now we’ve only scraped one website at a time. But there may be
situations where the information you need will be split in different
pages, or where you have to follow a trace of hyperlinks. With the tools
we’ve learned until now, this new task is straightforward. We would have
to add a loop that goes to those other pages, gets the HTML document
using the requests package, and parses the HTML with
BeautifulSoup to extract the required information.
The additional and important step to consider in this task is to add a wait time between each request to the website, so we don’t overload the web server that is providing us the information we need. If we send too many requests in a short period of time, we can prevent other “normal” users from accessing the site during that time, or even cause the server to run out of resources and crash. If the provider of the website detects an excessive use, it could block our computer from accessing that website, or even take legal action in extreme cases.
To make sure we don’t crash the server, we can add a wait time
between each step of our loop with the built-in Python module
time and its sleep() function. With this
function, Python will wait for the specified number of seconds before
continuing to execute the next line of code. For example, when you run
the following code, Python will wait 10 seconds between each print
execution.
Let’s incorporate this important principle for extracting additional
information from each of our workshop websites in the upcoming list. We
already have our upcomingworkshops_df dataframe, and in
there, a link column with the URL to the website for each
individual workshop. For example, let’s make a request for the HTML of
the first workshop in the dataframe, and take a look.
PYTHON
first_url = upcomingworkshops_df.loc[0, 'link']
print("URL we are visiting: ", first_url)
req = requests.get(first_url).text
cleaned_req = re.sub(r'\s*\n\s*', '', req).strip()
soup = BeautifulSoup(cleaned_req, 'html.parser')
print(soup.prettify())If we explore the HTML this way, or using the ‘View page source’ in
the browser, we notice something interesting in the
<head> element. As this information is inside
<head> instead of the <body>
element, it won’t be displayed in our browser when we visit the page,
but the meta elements will provide metadata for search engines to better
understand, display, and index the page. Each of this
<meta> tags contain useful information for our table
of workshops, for example, a well formatted start and end date, the
exact location of the workshop with latitude and longitude (for those
not online), the language in which it will be taught, and a more
structured way of listing instructors and helpers. Each of these data
points can be identified by the the “name” attribute in the
<meta> tags, and the information we want to extract
is the value in the “content” attribute.
The following code automates the process of getting this data from
each website, for the first five workshops in our
upcomingworkshops_df dataframe. We will only do it for five
workshops to not send too many requests overwhelming the server, but we
could also do it for all the workshops.
PYTHON
# List of URLs in our dataframe
urls = list(upcomingworkshops_df.loc[:5, 'link'])
# Start an empty list to store the different dictionaries with our data
list_of_workshops = []
# Start a loop over each URL
for item in tqdm(urls):
# Get the HTML and parse it
req = requests.get(item).text
cleaned_req = re.sub(r'\s*\n\s*', '', req).strip()
soup = BeautifulSoup(cleaned_req, 'html.parser')
# Start an empty dictionary and fill it with the URL, which
# is our identifier with our other dataframe
dict_w = {}
dict_w['link'] = item
# Use the find function to search for the <meta> tag that
# has each specific 'name' attribute and get the value in the
# 'content' attribute
dict_w['startdate'] = soup.find('meta', attrs = {'name': 'startdate'})['content']
dict_w['enddate'] = soup.find('meta', attrs = {'name': 'enddate'})['content']
dict_w['language'] = soup.find('meta', attrs = {'name': 'language'})['content']
dict_w['latlng'] = soup.find('meta', attrs = {'name': 'latlng'})['content']
dict_w['instructor'] = soup.find('meta', attrs = {'name': 'instructor'})['content']
dict_w['helper'] = soup.find('meta', attrs = {'name': 'helper'})['content']
# Append to our list
list_of_workshops.append(dict_w)
# Be respectful, wait at least 3 seconds before a new request
sleep(3)
extradata_upcoming_df = pd.DataFrame(list_of_workshops)Challenge
It is possible that you received an error when executing the previous block code, and the most probable reason is that the URL your tried to visit didn’t exist. This is known as 404 code error, that indicates the requested page doesn’t exist, or more precisely, it cannot be found on the server. What would be your approach to work around this possible error?
A Pythonic crude way of working around any error for a given URL would be to use a try and except block, for which you would ignore any URL that throws an error and continue with the next one.
A more stylish way to deal when a web page doesn’t exist is to get
the actual response code when requests tries to reach the
page. If you receive a 200 code, it means the request was successful. In
any other case, you’d want to store the code and skip the scraping of
that page. The code you’d use to get the response code is:
Key Points
- We can get the HTML behind any website using the “requests” package
and the function
requests.get('website_url').text. - An HTML document is a nested tree of elements. Therefore, from a
given element, we can access its child, parent, or sibling, using
.contents,.parent,.next_sibling, andprevious_sibling. - It’s polite to not send too many requests to a website in a short
period of time. For that, we can use the
sleep()function of the built-in Python moduletime.
Content from Dynamic websites
Last updated on 2024-11-04 | Edit this page
Overview
Questions
- What are the differences between static and dynamic websites?
- Why is it important to understand these differences when doing web scraping?
- How can I start my own web scraping project?
Objectives
- Use the
Seleniumpackage to scrape dynamic websites. - Identify the elements of interest using the browser’s “Inspect” tool.
- Understand the usual pipeline of a web scraping project.
You see it but the HTML doesn’t have it!
Visit the following webpage created by Hartley Brody for the purpose of learning and practicing web scraping: https://www.scrapethissite.com/pages/ajax-javascript/ (read first the terms of use). Select “2015” to see that year’s Oscar winning films. Now look at the HTML behind it as we’ve learned, using the “View page source” tool on your browser or in Python using the requests and BeautifulSoup packages. Can you find in any place of the HTML the best picture winner “Spotlight”? Can you find any other of the movies or the data from the table? If you can’t, how could you scrape this page?
When you explore a page like this, you’ll notice that the movie data,
including the title “Spotlight,” isn’t actually in the initial HTML
source. This is because the website uses JavaScript to load the
information dynamically. JavaScript is a programming language that runs
in your browser, allowing websites to fetch, process, and display
content on the fly, often based on user actions like clicking a button.
When you select “2015”, the browser executes JavaScript (called by one
of the <script> elements you see in the HTML) to
retrieve the relevant movie information from the web server and build a
new HTML document with actual information in the table. This makes the
page feel more interactive, but it also means the initial HTML you see
doesn’t contain the movie data itself.
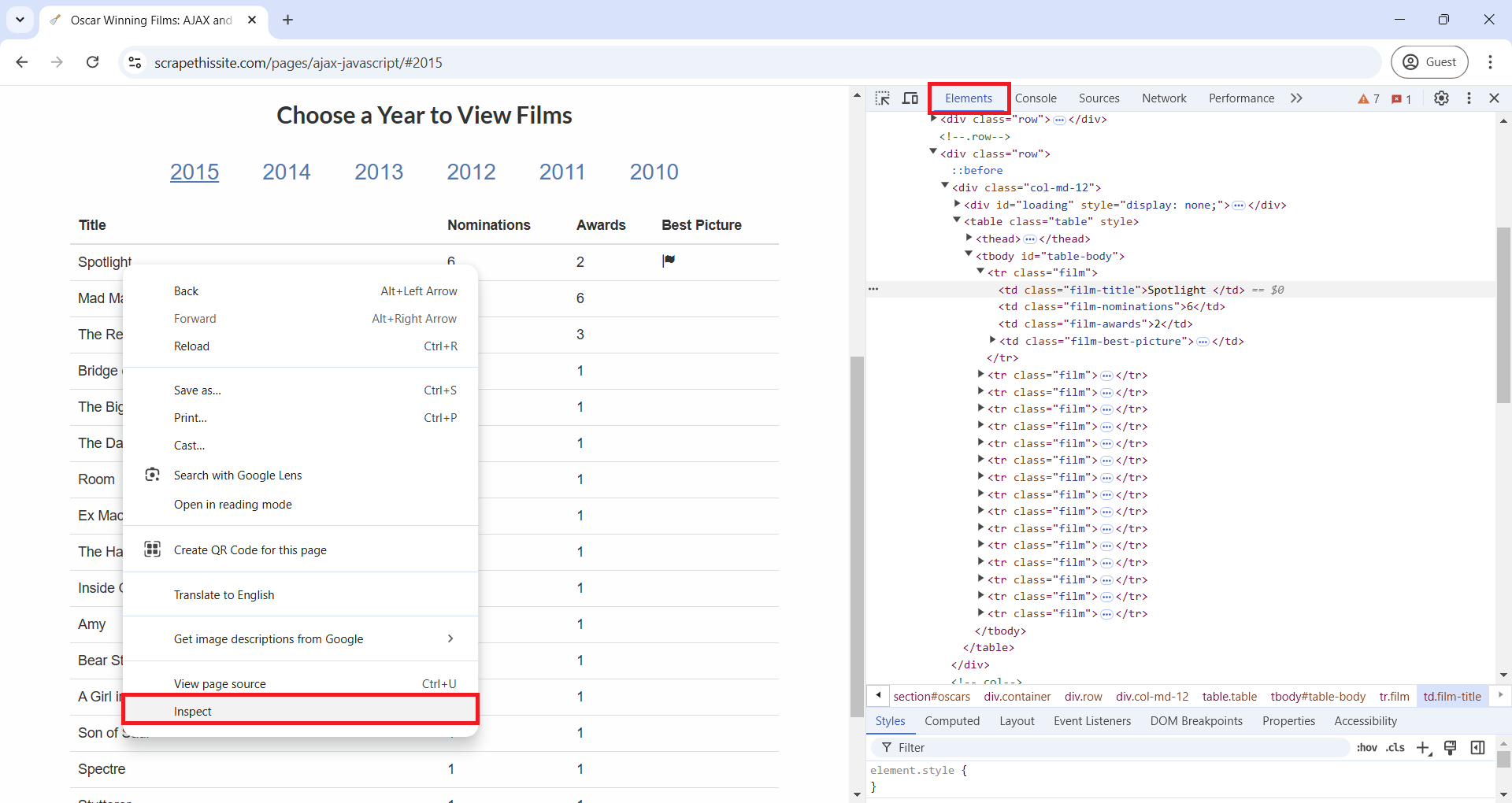
Let’s explore a new way to view HTML elements in your browser to better understand the differences in an HTML document before and after JavaScript is executed. On the Oscar winners page you just visited, right-click (or Control key + Click on Mac) and select “Inspect” from the pop-up menu, as shown in the image below. This opens DevTools on the side of your browser, offering a range of features for inspecting, debugging, and analyzing web pages in real-time. For this workshop, however, we’ll focus on just the “Elements” tab. In the “Elements” tab, you’ll see an HTML document that actually includes the table element, unlike what you saw in “View Page Source”. This difference is because “View Page Source” displays the original HTML, before any JavaScript is run, while “Inspect” reveals the HTML as it appears after JavaScript has executed.
As the requests package retrieves the source HTML, we
need a different approach to scrape these types of websites. For this,
we will use the Selenium package. But don’t forget about
the “Inspect” tool we just learned, it will be handy when scraping.
Using Selenium to scrape dynamic websites
Selenium is an open source project for web browser automation. It will be useful for our scraping tasks as it will act as a real user interacting with a webpage in a browser. This way, Selenium will render pages in a browser environment, allowing JavaScript to load dynamic content, and therefore giving us access to the website HTML after JavaScript has executed. Additionally, this package simulates real user interactions like filling in text boxes, clicking, scrolling, or selecting drop-down menus, which will be useful when we scrape dynamic websites.
To use it, we’ll load “webdriver” and “By” from the
selenium package. webdriver open or simulate a web browser,
interacting with it based on the instructions we give. By will allow us
to specify how we will select a given element in the HTML, by tag (using
“By.TAG_NAME”) or by attributes like class (“By.CLASS_NAME”), id
(“By.ID”), or name (“By.NAME”). We will also load the other packages we
used in the previous episode.
PYTHON
from bs4 import BeautifulSoup
import pandas as pd
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import BySelenium can simulate multiple multiple browsers like Chrome, Firefox, Safari, etc. For now, we’ll use Chrome. When you run the following line of code, you’ll notice that a Google Chrome window opens up. Don’t close it, as this is how Selenium interacts with the browser. Later we’ll see how to do headless browser interactions, headless meaning that browser interactions will happen in the background, without opening a new browser window or user interface.
Now, to tell the browser to visit our Oscar winners page, use the
.get() method on the driver object we just
created.
How can we direct Selenium to click the text “2015” for the table of
that year tho show up? First, we need to find that element, in a similar
way to how we find elements with BeautifulSoup. Just like we used
.find() in BeautifulSoup to find the first element that
matched the specified criteria, in Selenium we have
.find_element(). Likewise, as we used
.find_all() in BeautifulSoup to return a list of all
coincidences for our search criteria, we can use
.find_elements() in Selenium. But the syntax of how we
specify the search paramenters will be a little different.
If we wanted to search a table element that has the
<table> tag, we would run
driver.find_element(by=By.TAG_NAME, value="table"). If we
wanted to search an element with a specific value in the “class”
attribute, for example an element like
<tr class="film"> we would run
driver.find_element(by=By.CLASS_NAME, value="film"). To
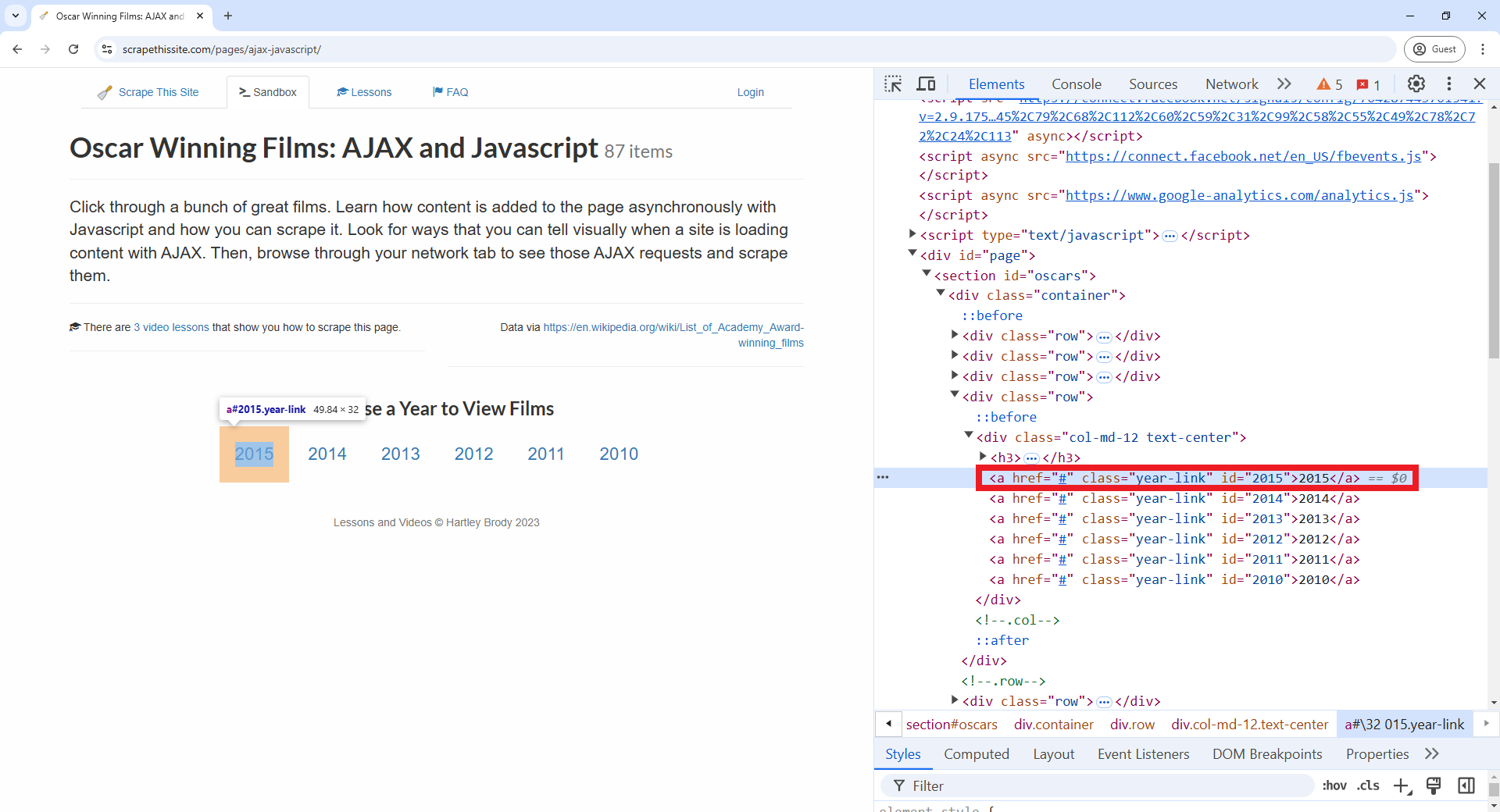
know what element we need to click to open “2015” table of Oscar winners
we can use the “Inspect” tool (remember you can do this in Google Chrome
by pointing your mouse over the “2015” value, make a right-click, and
select “Inspect” from the pop-up menu). In the DevTools window, you’ll
see element
<a href="#" class="year-link" id="2015">2015</a>.
As the ID attribute is unique for only one element in the HTML, we can
directly select the element by this attribute using the code you’ll find
after the following image.
We’ve located the hyperlink element we want to click to get the table
for that year, and on that element we will use the .click()
method to interact with it. As the table takes a couple of seconds to
load, we will also use the sleep() function from the “time”
module to wait will the JavaScript runs and the table loads. Then, we
use driver.page_source for Selenium to get the HTML
document from the website, and we store it in a variable called
html_2015. Finally, we close the web browser that Selenium
was using with driver.quit().
Importantly, the HTML document we stored in html_2015
is the HTML after the dynamic content loaded, so it
will contain the table values for 2015 that weren’t there originally and
that we wouldn’t be able to see if we had used the requests
package instead.
We could continue using Selenium and its .find_element()
and .find_elements() methods to to extract our data of
interest. But instead, we will use BeautifulSoup to parse the HTML and
find elements, as we already have some practice using it. If we search
for the first element with class attribute equal to “film-title” and
return the text inside it, we see that this HTML has the “Spotlight”
movie.
PYTHON
<tr class="film">
<td class="film-title">
Spotlight
</td>
<td class="film-nominations">
6
</td>
<td class="film-awards">
2
</td>
<td class="film-best-picture">
<i class="glyphicon glyphicon-flag">
</i>
</td>
</tr>The following code repeats the process of clicking and loading the
2015 data, but now using “headless” mode (i.e. without opening a browser
window). Then, it extracts data from the table one column at a time,
taking advantage that each column has a unique class attribute that
identifies it. Instead of using for loops to extract data from each
element that .find_all() finds, we use list comprehensions.
You can learn more about them reading Python’s
documentation for list comprehensions, or with this Programiz
short tutorial.
PYTHON
# Create the Selenium webdriver and make it headless
options = ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(options=options)
# Load the website. Find and click 2015. Get post JavaScript execution HTML. Close webdriver
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
button_2015 = driver.find_element(by=By.ID, value="2015")
button_2015.click()
sleep(3)
html_2015 = driver.page_source
driver.quit()
# Parse HTML using BeautifulSoup and extract each column as a list of values ising list comprehensions
soup = BeautifulSoup(html_2015, 'html.parser')
titles_lc = [elem.get_text() for elem in soup.find_all(class_="film-title")]
nominations_lc = [elem.get_text() for elem in soup.find_all(class_="film-nominations")]
awards_lc = [elem.get_text() for elem in soup.find_all(class_="film-awards")]
# For the best picture column, we can't use .get_text() as there is no text
# Rather, we want to see if there is an <i> tag
best_picture_lc = ["Yes" if elem.find("i") == None else "No" for elem in soup.find_all(class_="film-best-picture")]
# Create a dataframe based on the previous lists
movies_2015 = pd.DataFrame(
{'titles': titles_lc, 'nominations': nominations_lc, 'awards': awards_lc, 'best_picture': best_picture_lc}
)Challenge
Based on what we’ve learned in this episode, write code for getting the data of all the years from 2010 to 2015 of Hartley Brody’s website with information of Oscar Winning Films. Hint: You’ll use the same code, but add loop through each year.
Besides adding a loop for each year, the following solution is refactoring the code by creating two functions: one that finds and clicks a year returning the html after the data shows up, and another that gets the html and parses it to extract the data and create a dataframe.
So you can see the process of how Selenium opens the browser and clicks the years, we are not adding the “headless” option.
PYTHON
# Function to search year hyperlink and click it
def findyear_click_gethtml(year):
button = driver.find_element(by=By.ID, value=year)
button.click()
sleep(3)
html = driver.page_source
return html
# Function to parse html, extract table data, and assign year column
def parsehtml_extractdata(html, year):
soup = BeautifulSoup(html, 'html.parser')
titles_lc = [elem.get_text() for elem in soup.find_all(class_="film-title")]
nominations_lc = [elem.get_text() for elem in soup.find_all(class_="film-nominations")]
awards_lc = [elem.get_text() for elem in soup.find_all(class_="film-awards")]
best_picture_lc = ["No" if elem.find("i") == None else "Yes" for elem in soup.find_all(class_="film-best-picture")]
movies_df = pd.DataFrame(
{'titles': titles_lc, 'nominations': nominations_lc, 'awards': awards_lc, 'best_picture': best_picture_lc, 'year': year}
)
return movies_df
# Open Selenium webdriver and go to the page
driver = webdriver.Chrome()
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# Create empty dataframe where we will append/concatenate the dataframes we get for each year
result_df = pd.DataFrame()
for year in ["2010", "2011", "2012", "2013", "2014", "2015"]:
html_year = findyear_click_gethtml(year)
df_year = parsehtml_extractdata(html_year, year)
result_df = pd.concat([result_df, df_year])
# Close the browser that Selenium opened
driver.quit()Challenge
If you are tired of scraping table data like we’ve been doing for the last two episodes, here is another dynamic website exercise where you can practice what you’ve learned. Go to this product page created by scrapingcourse.com and extract all product names and prices, and also the hyperlink that each product card has to a detailed view page.
When you complete that, and if you are up to an additional challenge, scrape from the detailed view page of each product its SKU, Category and Description.
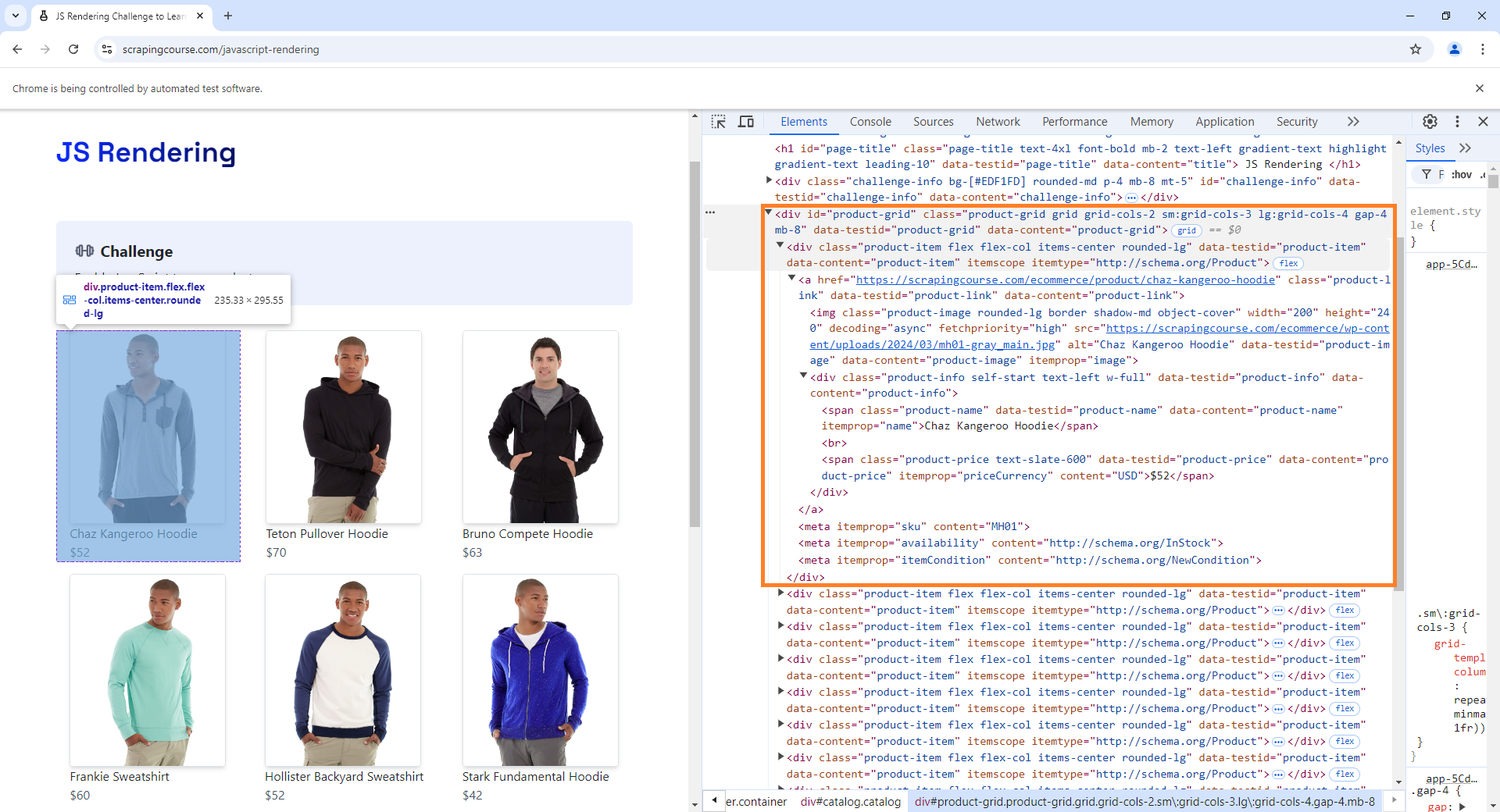
To identify what elements containt the data you need, you should use
the “Inspect” tool in your browser. The following image is a screenshot
of the website. In there we can see that each product card is a
<div> element with multiple attributes that we can
use to narrow down our search to the specific elements we want. For
example, we would use 'data-testid'='product-item'. After
we find all divs that satisfy that condition, we can extract
from each the hyperlink, the name, and the price. The hyperlink is the
‘href’ attribute of the <a> tag. The name and price
are inside <span> tags, and we could use multiple
attributes to get each of them. In the following code, we will use
'class'='product-name' to get the name and
'data-content'='product-price' to get the price.
PYTHON
# Open Selenium webdriver in headless mode and go to the desired page
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(options=options)
driver.get("https://www.scrapingcourse.com/javascript-rendering")
# As we don't have to click anything, just wait for the JavaScript to load, we can get the HTML right away
sleep(3)
html = driver.page_source
# Parste the HTML
soup = BeautifulSoup(html, 'html.parser')
# Find all <div> elements that have a 'data-testid' attribute with the value of 'product-item'
divs = soup.find_all("div", attrs = {'data-testid': 'product-item'})
# Loop through the <div> elements we found, and for each get the href,
# the name (inside a <span> element with attribute class="product-name")
# and the price (inside a <span> element with attribute data-content="product-price"
list_of_dicts = []
for div in divs:
# Create a dictionary to store the data we want for each product
item_dict = {
'link': div.find('a')['href'],
'name': div.find('span', attrs = {'class': 'product-name'}).get_text(),
'price': div.find('span', attrs = {'data-content': 'product-price'}).get_text()
}
list_of_dicts.append(item_dict)
all_products = pd.DataFrame(list_of_dicts)We could arrive to the same result if we replace the for loop with list comprehensions. So here is another possible solution with that approach.
PYTHON
links = [elem['href'] for elem in soup.find_all('a', attrs = {'class': 'product-link'})]
names = [elem.get_text() for elem in soup.find_all('span', attrs = {'class': 'product-name'})]
prices = [elem.get_text() for elem in soup.find_all('span', attrs = {'data-content': 'product-price'})]
all_products_v2 = pd.DataFrame(
{'link': links, 'name': names, 'price': prices}
)The scraping pipeline
By now, you’ve learned about the core tools for web scraping: requests, BeautifulSoup, and Selenium. These three tools form a versatile pipeline for almost any web scraping task. When starting a new scraping project, there are several important steps to follow that will help ensure you capture the data you need.
The first step is understanding the website structure. Every website is different and structures data in its own particular way. Spend some time exploring the site and identifying the HTML elements that contain the information you want. Next, determine if the content is static or dynamic. Static content can be directly accessed from the HTML source code using requests and BeautifulSoup, while dynamic content often requires Selenium to load JavaScript on the page before BeautifulSoup can parse it.
Once you know how the website presents its data, start
building your pipeline. If the content is static, make a
requests call to get the HTML document, and use
BeautifulSoup to locate and extract the necessary elements.
If the content is dynamic, use Selenium to load the page
fully, perform any interactions (like clicking or scrolling), and then
pass the rendered HTML to BeautifulSoup for parsing and
extracing the necessary elements. Finally, format and store the
data in a structured way that’s useful for your specific
project and that makes it easy to analyse later.
This scraping pipeline helps break down complex scraping tasks into manageable steps and allows you to adapt the tools based on the website’s unique features. With practice, you’ll be able to efficiently combine these tools to extract valuable data from almost any website.
Key Points
- Dynamic websites load content using JavaScript, which isn’t present in the initial or source HTML. It’s important to distinguish between static and dynamic content when planning your scraping approach.
- The
Seleniumpackage and itswebdrivermodule simulate a real user interacting with a browser, allowing it to execute JavaScript and clicking, scrolling or filling in text boxes. - Here are the commandand we learned when we use
Selenium:-
webdriver.Chrome()# Start the Google Chrome browser simulator -
.get("website_url")# Go to a given website -
.find_element(by, value)and.find_elements(by, value)# Get a given element -
.click()# Click the element selected -
.page_source# Get the HTML after JavaScript has executed, which can later be parsed with BeautifulSoup -
.quit()# Close the browser simulator
-
- The browser’s “Inspect” tool allows users to view the HTML document after dynamic content has loaded, revealing elements added by JavaScript. This tool helps identify the specific elements you are interested in scraping.
- A typical scraping pipeline involves understanding the website’s structure, determining content type (static or dynamic), using the appropriate tools (requests and BeautifulSoup for static, Selenium and BeautifulSoup for dynamic), and structuring the scraped data for analysis.