Hello-Scraping
Last updated on 2024-11-04 | Edit this page
Overview
Questions
- What is behind a website and how can I extract its information?
- What is there to consider before I do web scraping?
Objectives
- Identify the structure and basic components of an HTML document.
- Use BeautifulSoup to locate elements, tags, attributes and text in an HTML document.
- Understand the situations in which web scraping is not suitable for obtaining the desired data.
Introduction
This is part two of an Introduction to Web Scraping workshop we
offered on February 2024. You can refer to those workshop
materials to have a more gentle introduction to scraping using XPath
and the Scraper Chrome extension.
We’ll refresh some of the concepts covered there to have a practical
understanding of how content/data is structured in a website. For that
purpose, we’ll see what Hypertext Markup Language (HTML) is and how it
structures and formats the content using tags. From there,
we’ll use the BeautifulSoup library to parse the HTML content so we can
easily search and access elements of the website we are interested in.
Starting from basic examples, we’ll move to scrape more complex,
real-life websites.
HTML quick overview
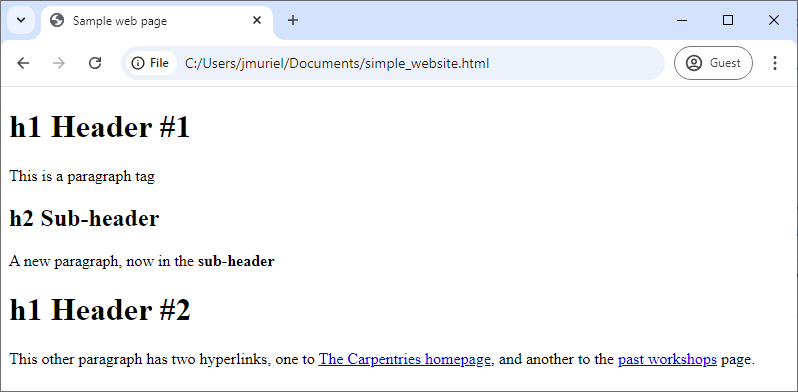
All websites have a Hypertext Markup Language (HTML) document behind them. The following text is HTML for a very simple website, with only three sentences. If you look at it, can you imagine how that website looks?
HTML
<!DOCTYPE html>
<html>
<head>
<title>Sample web page</title>
</head>
<body>
<h1>h1 Header #1</h1>
<p>This is a paragraph tag</p>
<h2>h2 Sub-header</h2>
<p>A new paragraph, now in the <b>sub-header</b></p>
<h1>h1 Header #2</h1>
<p>
This other paragraph has two hyperlinks,
one to <a href="https://carpentries.org/">The Carpentries homepage</a>,
and another to the
<a href="https://carpentries.org/past_workshops/">past workshops</a> page.
</p>
</body>
</html>Well, if you put that text in a file with a .html extension, the job of your web browser when opening the file will be to interpret that (markup) language and display a nicely formatted website.
An HTML document is composed of elements, which can
be identified by tags written inside angle brackets
(< and >). For example, the HTML root
element, which delimits the beginning and end of an HTML document, is
identified by the <html> tag.
Most elements have both a opening and a closing tag, determining the
span of the element. In the previous simple website, we see a head
element that goes from the opening tag <head> up to
the closing tag </head>. Given than an element can be
inside another element, an HTML document has a tree structure, where
every element is a node that can contain child nodes, like the following
image shows.

Finally, we can define or modify the behavior, appeareance, or
functionality of an element by using attributes.
Attributes are inside the opening tag, and consist of a name and a
value, formatted as name="value". For example, in the
previous simple website, we added a hyperlink with the
<a>...</a> tags, but to set the destination URL
we used the href attribute by writing in the opening tag
a href="https://carpentries.org/past_workshops/".
Here is a non-exhaustive list of elements you’ll find in HTML and their purpose:
-
<hmtl>...</html>The root element, which contains the entirety of the document. -
<head>...</head>Contains metadata, for example, the title that the web browser displays. -
<body>...</body>The content that is going to be displayed. -
<h1>...</h1>, <h2>...</h2>, <h3>...</h3>Defines headers of level 1, 2, 3, etc. -
<p>...</p>A paragraph. -
<a href="">...</a>Creates a hyperlink, and we provide the destination URL with thehrefattribute. -
<img src="" alt="">Embedds an image, giving a source to the image with thesrcattribute and specifying alternate text withalt. -
<table>...</table>, <th>...</th>, <tr>...</tr>, <td>...</td>Defines a table, that as children will have a header (defined insideth), rows (defined insidetr), and a cell inside a row (astd). -
<div>...</div>Is used to group sections of HTML content. -
<script>...</script>Embeds or references JavaScript code.
In the previous list we’ve described some attributes specific for the
hyperlink elements (<a>) and the image elements
(<img>), but there are a few other global attributes
that most HTML elements can have and are useful to identify specific
elements when doing web scraping:
-
id=""Assigns a unique identifier to an element, which cannot be repeated in the entire HTML document -
title=""Provides extra information, displayed as a tooltip when the user hovers over the element. -
class=""Is used to apply a similar styling to multiple elements at once.
To summarize, an element is identified by tags, and we can assign properties to an element by using attributes. Knowing this about HTML will make our lifes easier when trying to get some specific data from a website.
Parsing HTML with BeautifulSoup
Now that we know how a website is structured, we can start extracting information from it. The BeautifulSoup package is our main tool for that task, as it will parse the HTML so we can search and access the elements of interest in a programmatic way.
To see how this package works, we’ll use the simple website example we showed before. As our first step, we will load the BeautifulSoup package, along with Pandas.
Let’s get the HTML content inside a string variable called
example_html
PYTHON
example_html = """
<!DOCTYPE html>
<html>
<head>
<title>Sample web page</title>
</head>
<body>
<h1>h1 Header #1</h1>
<p>This is a paragraph tag</p>
<h2>h2 Sub-header</h2>
<p>A new paragraph, now in the <b>sub-header</b></p>
<h1>h1 Header #2</h1>
<p>
This other paragraph has two hyperlinks,
one to <a href="https://carpentries.org/">The Carpentries homepage</a>,
and another to the
<a href="https://carpentries.org/past_workshops/">past workshops</a> page.
</p>
</body>
</html>
"""We parse this HTML using the BeautifulSoup() function we
imported, specifying that we want to use the html.parser.
This object will represent the document as a nested data structure,
similar to a tree as we mentioned before. If we use the
.prettify() method on this object, we can see the nested
structure, as inner elements will be indented to the right.
OUTPUT
<!DOCTYPE html>
<html>
<head>
<title>
Sample web page
</title>
</head>
<body>
<h1>
h1 Header #1
</h1>
<p>
This is a paragraph tag
</p>
<h2>
h2 Sub-header
</h2>
<p>
A new paragraph, now in the
<b>
sub-header
</b>
</p>
<h1>
h1 Header #2
</h1>
<p>
This other paragraph has two hyperlinks, one to
<a href="https://carpentries.org/">
The Carpentries homepage
</a>
, and another to the
<a href="https://carpentries.org/past_workshops/">
past workshops
</a>
.
</p>
</body>
</html>Now that our soup variable holds the parsed document, we
can use the .find() and .find_all() methods.
.find() will search the tag that we specify, and return the
entire element, including the starting and closing tags. If there are
multiple elements with the same tag, .find() will only
return the first one. If you want to return all the elements that match
your search, you’d want to use .find_all() instead, which
will return them in a list. Additionally, to return the text contained
in a given element and all its children, you’d use
.get_text(). Below you can see how all these commands play
out in our simple website example.
PYTHON
print("1.", soup.find('title'))
print("2.", soup.find('title').get_text())
print("3.", soup.find('h1').get_text())
print("4.", soup.find_all('h1'))
print("5.", soup.find_all('a'))
print("6.", soup.get_text())OUTPUT
1. <title>Sample web page</title>
2. Sample web page
3. h1 Header #1
4. [<h1>h1 Header #1</h1>, <h1>h1 Header #2</h1>]
5. [<a href="https://carpentries.org/">The Carpentries homepage</a>, <a href="https://carpentries.org/past_workshops/">past workshops</a>]
6.
Sample web page
h1 Header #1
This is a paragraph tag
h2 Sub-header
A new paragraph, now in the sub-header
h1 Header #2
This other paragraph has two hyperlinks, one to The Carpentries homepage, and another to the past workshops.
How would you extract all hyperlinks identified with
<a> tags? In our example, we see that there are only
two hyperlinks, and we could extract them in a list using the
.find_all('a') method.
OUTPUT
Number of hyperlinks found: 2
[<a href="https://carpentries.org/">The Carpentries homepage</a>, <a href="https://carpentries.org/past_workshops/">past workshops</a>]To access the value of a given attribute in an element, for example
the value of the href attribute in
<a href="">, we would use square brackets and the
name of the attribute (['href']), just like how in a Python
dictionary we would access the value using the respective key. Let’s
make a loop that prints only the URL for each hyperlink we have in our
example.
OUTPUT
https://carpentries.org/
https://carpentries.org/past_workshops/Challenge
Create a Python dictionary that has the following three items, containing information about the first hyperlink in the HTML of our example.
One way of completing the exercise is as follows.
PYTHON
first_link = {
'element': str(soup.find('a')),
'url': soup.find('a')['href'],
'text': soup.find('a').get_text()
}An alternate but similar way is to store the tag found for not
calling multiple times soup.find('a'), and also creating
first an empty dictionary and append to it the keys and values we want,
as this will be useful when we do this multiple times in a for loop.
To finish this introduction on HTML and BeautifulSoup, let’s create
code for extracting in a structured way all the hyperlink elements,
their destination URL and the text displayed for link. For that, let’s
use the links variable that we created before as
links = soup.find_all('a'). We’ll loop over each hyperlink
element found, storing for each the three pieces of information we want
in a dictionary, and finally appending that dictionary to a list called
list_of_dicts. At the end we will have a list with two
elements, that we can transform to a Pandas dataframe.
PYTHON
links = soup.find_all('a')
list_of_dicts = []
for item in links:
dict_a = {}
dict_a['element'] = str(item)
dict_a['url'] = item['href']
dict_a['text'] = item.get_text()
list_of_dicts.append(dict_a)
links_df = pd.DataFrame(list_of_dicts)
print(links_df)OUTPUT
element \
0 <a href="https://carpentries.org/">The Carpent...
1 <a href="https://carpentries.org/past_workshop...
url text
0 https://carpentries.org/ The Carpentries homepage
1 https://carpentries.org/past_workshops/ past workshops You’ll find more useful information about the BeautifulSoup package and how to use all its methods in the Beautiful Soup Documentation website.
The rights, wrongs, and legal barriers to scraping
The internet is no longer what it used to be. Once an open and boundless source of information, the web has become an invaluable pool of data, widely used by companies to train machine learning and generative AI models. Now, social media platforms and other website owners have either recognized the potential for profit and licensed their data or have become overwhelmed by bots crawling their sites and straining their server resources.
For this reason, it’s now more common to see that a website’s Terms of Service (TOS) explicitly prohibits web scraping. If we want to avoid getting into trouble, we need to carefully check the TOS of your website of interest as well as its ‘robots.txt’ file. You should be able to find both using your preferred search engine, but you may directly go to the latter by appending ‘/robots.txt’ at the root URL of the website (e.g. for Facebook you’ll find it in ‘https://facebook.com/robots.txt’, not in any other URL like ‘https://facebook.com/user/robots.txt’).
Challenge
Visit Facebook’s Terms of Service and its robots.txt file. What do they say about web scraping or collecting data using automated means? Compare it to Reddit’s TOS and Reddit’s robots.txt.
Besides checking the website’s policies, you should also be aware of the legislation applicable to your location regarding copyright and data privacy laws. If you plan to start harvesting a large amount of data for research or commercial purposes, you should probably seek legal advice first. If you work in a university, chances are it has a copyright office that will help you sort out the legal aspects of your project. The university library is often the best place to start looking for help on copyright.
To conclude, here is a brief code of conduct you should consider when doing web scraping:
- Ask nicely if you can access the data in another way. If your project requires data from a particular organisation, you can try asking them directly if they could provide you what you are looking for, or check if they have an API to access the data. With some luck, they will have the primary data that they used on their website in a structured format, saving you the trouble.
- Don’t download copies of documents that are clearly not public. For example, academic journal publishers often have very strict rules about what you can and what you cannot do with their databases. Mass downloading article PDFs is probably prohibited and can put you (or at the very least your friendly university librarian) in trouble. If your project requires local copies of documents (e.g. for text mining projects), special agreements can be reached with the publisher. The library is a good place to start investigating something like that.
- Check your local legislation. For example, certain countries have laws protecting personal information such as email addresses and phone numbers. Scraping such information, even from publicly avaialable web sites, can be illegal (e.g. in Australia).
- Don’t share downloaded content illegally. Scraping for personal purposes is usually OK, even if it is copyrighted information, as it could fall under the fair use provision of the intellectual property legislation. However, sharing data for which you don’t hold the right to share is illegal.
- Share what you can. If the data you scraped is in the public domain or you got permission to share it, then put it out there for other people to reuse it (e.g. on datahub.io). If you wrote a web scraper to access it, share its code (e.g. on GitHub) so that others can benefit from it.
- Publish your own data in a reusable way. Don’t force others to write their own scrapers to get at your data. Use open and software-agnostic formats (e.g. JSON, XML), provide metadata (data about your data: where it came from, what it represents, how to use it, etc.) and make sure it can be indexed by search engines so that people can find it.
- Don’t break the Internet. Not all web sites are designed to withstand thousands of requests per second. If you are writing a recursive scraper (i.e. that follows hyperlinks), test it on a smaller dataset first to make sure it does what it is supposed to do. Adjust the settings of your scraper to allow for a delay between requests. More on this topic in the next episode.
Key Points
- Every website has an HTML document behind it that gives a structure to its content.
- An HTML is composed of elements, which usually have a opening
<tag>and a closing</tag>. - Elements can have different properties, assigned by attributes in
the form of
<tag attribute_name="value">. - We can parse any HTML document with
BeautifulSoup()and find elements using the.find()and.find_all()methods. - We can access the text of an element using the
.get_text()method and the attribute values as we do with Python dictionaries (element["attribute_name"]). - We must be careful to not tresspass the Terms of Service (TOS) of the website we are scraping.