Introduction: What is web scraping?
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What is web scraping and why is it useful?
What are typical use cases for web scraping?
Objectives
Introduce the concept of structured data
Discuss how data can be extracted from web pages
Introduce the examples that will be used in this lesson
What is web scraping?
Web scraping is a technique for extracting information from websites. This can be done manually but it is usually faster, more efficient and less error-prone to automate the task.
Web scraping allows you to acquire non-tabular or poorly structured data from websites and convert it into a usable, structured format, such as a .csv file or spreadsheet.
Scraping is about more than just acquiring data: it can also help you archive data and track changes to data online.
It is closely related to the practice of web indexing, which is what search engines like Google do when mass-analysing the Web to build their indices. But contrary to web indexing, which typically parses the entire content of a web page to make it searchable, web scraping targets specific information on the pages visited.
For example, online stores will often scour the publicly available pages of their competitors, scrape item prices, and then use this information to adjust their own prices. Another common practice is “contact scraping” in which personal information like email addresses or phone numbers is collected for marketing purposes.
Web scraping is also increasingly being used by scholars to create data sets for text mining projects; these might be collections of journal articles or digitised texts. The practice of data journalism, in particular, relies on the ability of investigative journalists to harvest data that is not always presented or published in a form that allows analysis.
Before you get started
As useful as scraping is, there might be better options for the task. Choose the right (i.e. the easiest) tool for the job.
- Check whether or not you can easily copy and paste data from a site into Excel or Google Sheets. This might be quicker than scraping.
- Check if the site or service already provides an API to extract structured data. If it does, that will be a much more efficient and effective pathway. Good examples are the Facebook API, the Twitter APIs or the YouTube comments API.
- For much larger needs, Freedom of information Act (FOIA) requests can be useful. Be specific about the formats required for the data you want.
Example: scraping UCSB department websites for faculty contact information
In this workshop, we will learn how to extract contact information from UCSB departments’ faculty pages. This example came from a recent real-life scenario when our team needed to make lists of social sciences faculty for outreach reasons. There is no overarching list of faculty, contact information, and study area available for the university as a whole. This was made even more difficult by the fact that each UCSB department has webpages with wildly different formating. We will see examples using both the scraping chrome extension. There are different scenarios when one might be a better choice than the other.
But before that we need to first understand, let’s start by looking at the list of members of the Canadian parliament, which is available on the Parliament of Canada website
This is how this page appears in February 2024:
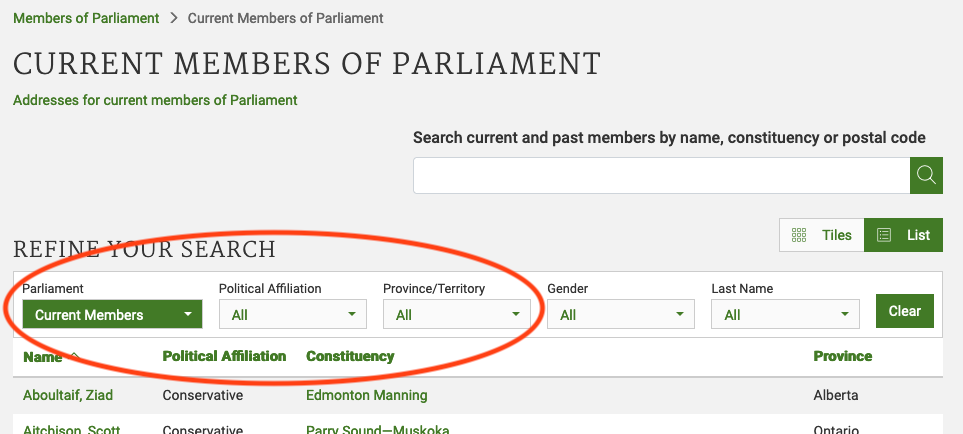
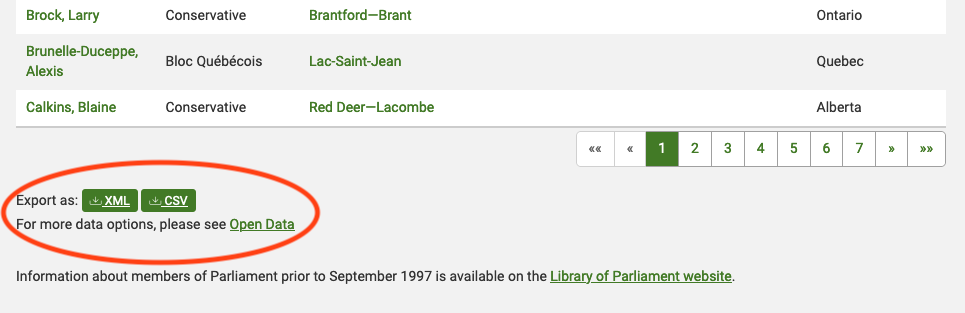
There are several features (circled in the image above) that make the data on this page easier to work with. The search, reorder, refine features and display modes hint that the data is actually stored in a (structured) database before being displayed on this page. The data can be readily downloaded either as a comma separated values (.csv) file or as XML for re-use in their own database, spreadsheet or computer program.
Even though the information displayed in the view above is not labelled, anyone visiting this site with some knowledge of Canadian geography and politics can see what information pertains to the politicians’ names, the geographical area they come from and the political party they represent. This is because human beings are good at using context and prior knowledge to quickly categorise information.
Computers, on the other hand, cannot do this unless we provide them with more information. If we examine the source HTML code of this page, we can see that the information displayed has a consistent structure:
(...)
<tr role="row" id="mp-list-id-25446" class="odd">
<td data-sort="Allison Dean" class="sorting_1">
<a href="/members/en/dean-allison(25446)">
Allison, Dean
</a>
</td>
<td data-sort="Conservative">Conservative</td>
<td data-sort="Niagara West">
<a href="/members/en/constituencies/niagara-west(782)">
Niagara West
</a>
</td>
<td data-sort="Ontario">Ontario</td>
</tr>
(...)
Using this structure, we may be able to instruct a computer to look for all parliamentarians from Alberta and list their names and caucus information.
Structured vs unstructured data
When presented with information, human beings are good at quickly categorizing it and extracting the data that they are interested in. For example, when we look at a magazine rack, provided the titles are written in a script that we are able to read, we can rapidly figure out the titles of the magazines, the stories they contain, the language they are written in, etc. and we can probably also easily organize them by topic, recognize those that are aimed at children, or even whether they lean toward a particular end of the political spectrum. Computers have a much harder time making sense of such unstructured data unless we specifically tell them what elements data is made of, for example by adding labels such as this is the title of this magazine or this is a magazine about food. Data in which individual elements are separated and labelled is said to be structured.
Let’s look now at the current list of members for the UK House of Commons.
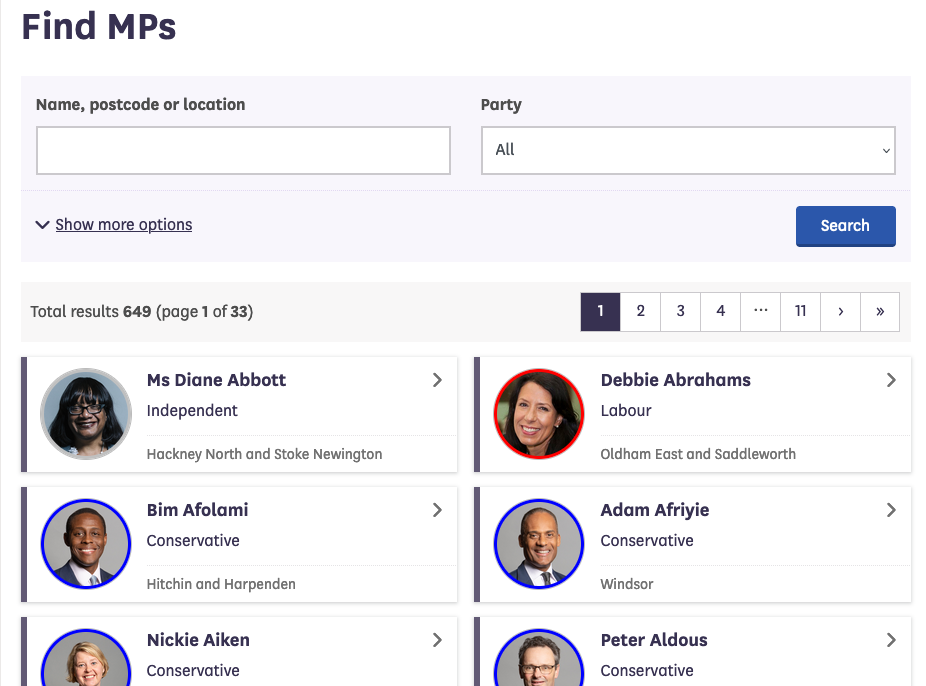
This page also displays a list of names, political and geographical affiliation. There is a search box and a filter option, but no obvious way to download this information and reuse it.
Here is the code for this page:
(...)
<a class="card card-member" href="/member/172/contact">
<div class="card-inner">
<div class="content">
<div class="image-outer">
<div class="image" aria-label="Image of Ms Diane Abbott" style="background-image: url(https://members-api.parliament.uk/api/Members/172/Thumbnail); border-color: #C0C0C0;"></div>
</div>
<div class="primary-info">
Ms Diane Abbott
</div>
<div class="secondary-info">
Independent
</div>
</div>
<div class="info">
<div class="info-inner">
<div class="indicators-left">
<div class="indicator indicator-label">
Hackney North and Stoke Newington
</div>
</div>
<div class="clearfix"></div>
</div>
</div>
</div>
</a>(...)
We see that this data has been structured for displaying purposes (it is arranged in rows inside a table) but the different elements of information are not clearly labelled.
What if we wanted to download this dataset and, for example, compare it with the Canadian list of MPs to analyze gender representation, or the representation of political forces in the two groups? We could try copy-pasting the entire table into a spreadsheet or even manually copy-pasting the names and parties in another document, but this can quickly become impractical when faced with a large set of data. What if we wanted to collect this information for every country that has a parliamentary system?
Fortunately, there are tools to automate at least part of the process. This technique is called web scraping.
“Web scraping (web harvesting or web data extraction) is a computer software technique of extracting information from websites.” (Source: Wikipedia)
Web scraping typically targets one web site at a time to extract unstructured information and put it in a structured form for reuse.
In this lesson, we will continue exploring the examples above and try different techniques to extract the information they contain. But before we launch into web scraping proper, we need to look a bit closer at how information is organized within an HTML document and how to build queries to access a specific subset of that information.
References
Key Points
Humans are good at categorizing information, computers not so much.
Often, data on a web site is not properly structured, making its extraction difficult.
Web scraping is the process of automating the extraction of data from web sites.
Selecting content on a web page with XPath
Overview
Teaching: 30 min
Exercises: 15 minQuestions
How can I select a specific element on web page?
What is XPath and how can I use it?
Objectives
Introduce XPath queries
Explain the structure of an XML or HTML document
Explain how to view the underlying HTML content of a web page in a browser
Explain how to run XPath queries in a browser
Introduce the XPath syntax
Use the XPath syntax to select elements on this web page
Before we delve into web scraping properly, we will first spend some time introducing some of the techniques that are required to indicate exactly what should be extracted from the web pages we aim to scrape.
The material in this section was adapted from the XPath and XQuery Tutorial written by Kim Pham (@tolloid) for the July 2016 Library Carpentry workshop in Toronto.
Introduction
XPath (which stands for XML Path Language) is an expression language used to specify parts of an XML document. XPath is rarely used on its own, rather it is used within software and languages that are aimed at manipulating XML documents, such as XSLT, XQuery or the web scraping tools that will be introduced later in this lesson. XPath can also be used in documents with a structure that is similar to XML, like HTML.
Markup Languages
XML and HTML are markup languages. This means that they use a set of tags or rules to organise and provide information about the data they contain. This structure helps to automate processing, editing, formatting, displaying, printing, etc. that information.
XML documents stores data in plain text format. This provides a software- and hardware-independent way of storing, transporting, and sharing data. XML format is an open format, meant to be software agnostic. You can open an XML document in any text editor and the data it contains will be shown as it is meant to be represented. This allows for exchange between incompatible systems and easier conversion of data.
XML and HTML
Note that HTML and XML have a very similar structure, which is why XPath can be used almost interchangeably to navigate both HTML and XML documents. In fact, starting with HTML5, HTML documents are fully-formed XML documents. In a sense, HTML is like a particular dialect of XML.
XML document follows basic syntax rules:
- An XML document is structured using nodes, which include element nodes, attribute nodes and text nodes
- XML element nodes must have an opening and closing tag, e.g.
<catfood>opening tag and</catfood>closing tag - XML tags are case sensitive, e.g.
<catfood>does not equal<catFood> - XML elements must be properly nested:
<catfood>
<manufacturer>Purina</manufacturer>
<address> 12 Cat Way, Boise, Idaho, 21341</address>
<date>2019-10-01</date>
</catfood>
- Text nodes (data) are contained inside the opening and closing tags
- XML attribute nodes contain values that must be quoted, e.g.
<catfood type="basic"></catfood>
XPath Expressions
XPath is written using expressions. Expressions consist of values, e.g., 368, and operators, e.g., +, that will return
a single value. 368 + 275 is an example of an expression. It will return the value 643. In programming terminology, this is called evaluating, which simply means reducing down to a single value. A single value with no operators, e.g. 35, can also be called an expression, though it will evaluate only to its existing value, e.g. 35.
Using XPath is similar to using advanced search in a library catalogue, where the structured nature of bibliographic information allows us to specify which metadata fields to query. For example, if we want to find books about Shakespeare but not works by him, we can limit our search function to the subject field only.
When we use XPath, we do not need to know in advance what the data we want looks like (as we would with regular expressions, where we need to know the pattern of the data). Since XML documents are structured into fields called nodes, XPath makes use of that structure to navigate through the nodes to select the data we want. We just need to know in which nodes within an XML file the data we want to find resides. When XPath expressions are evaluated on XML documents, they return objects containing the nodes that you specify.
XPath always assumes structured data.
Now let’s start using XPath.
Navigating through the HTML node tree using XPath
A popular way to represent the structure of an XML or HTML document is the node tree:
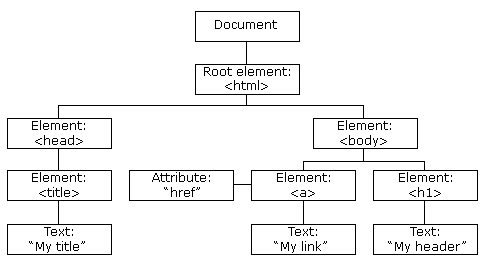
In an HTML document, everything is a node:
- The entire document is a document node
- Every HTML element is an element node
- The text inside HTML elements are text nodes
The nodes in such a tree have a hierarchical relationship to each other. We use the terms parent, child and sibling to describe these relationships:
- In a node tree, the top node is called the root (or root node)
- Every node has exactly one parent, except the root (which has no parent)
- A node can have zero, one or several children
- Siblings are nodes with the same parent
- The sequence of connections from node to node is called a path
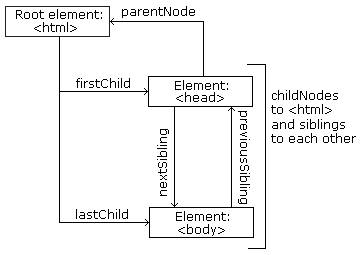
Paths in XPath are defined using slashes (/) to separate the steps in a node connection sequence, much like
URLs or Unix directories.
In XPath, all expressions are evaluated based on a context node. The context node is the node in which a path starts from. The default context is the root node, indicated by a single slash (/), as in the example above.
The most useful path expressions are listed below:
| Expression | Description |
|---|---|
nodename |
Select all nodes with the name “nodename” |
/ |
A beginning single slash indicates a select from the root node, subsequent slashes indicate selecting a child node from current node |
// |
Select direct and indirect child nodes in the document from the current node - this gives us the ability to “skip levels” |
. |
Select the current context node |
.. |
Select the parent of the context node |
@ |
Select attributes of the context node |
[@attribute = 'value'] |
Select nodes with a particular attribute value |
text() |
Select the text content of a node |
| | | Pipe chains expressions and brings back results from either expression, think of a set union |
Navigating through a webpage with XPath using a browser console
We will use the HTML code that describes this very page you are reading as an example. By default, a web browser interprets the HTML code to determine what markup to apply to the various elements of a document, and the code is invisible. To make the underlying code visible, all browsers have a function to display the raw HTML content of a web page.
Display the source of this page
Using your favourite browser, display the HTML source code of this page.
Tip: in most browsers, all you have to do is do a right-click anywhere on the page and select the “View Page Source” option (“Show Page Source” in Safari).
Another tab should open with the raw HTML that makes this page. See if you can locate its various elements, and this challenge box in particular.
Using the Safari browser
If you are using Safari, you must first turn on the “Develop” menu in order to view the page source, and use the functions that we will use later in this section. To do so, navigate to Safari > Preferences and in the Advanced tab select the “Show Develop in menu bar” option. Note: In recent versions of Safari you must first turn on the “Develop” menu (in Preferences) and then navigate to
Develop > Show Javascript Consoleand then click on the “Console” tab.
The HTML structure of the page you are currently reading looks something like this (most text and elements have been removed for clarity):
<!doctype html>
<html lang="en">
<head>
(...)
<title>Selecting content on a web page with XPath</title>
</head>
<body>
(...)
</body>
</html>
We can see from the source code that the title of this page is in a title element that is itself inside the
head element, which is itself inside an html element that contains the entire content of the page.
Say we wanted to tell a web scraper to look for the title of this page, we would use this information to indicate the
path the scraper would need to follow at it navigates through the HTML content of the page to reach the title
element. XPath allows us to do that.
We can run XPath queries directly from within all major modern browsers, by enabling the built-in JavaScript console.
Display the console in your browser
- In Firefox, use to the Tools > Web Developer > Web Console menu item.
- In Chrome, use the View > Developer > JavaScript Console menu item.
- In Safari, use the Develop > Show Error Console menu item. If your Safari browser doesn’t have a Develop menu, you must first enable this option in the Preferences, see above.
Here is how the console looks like in the Firefox browser:

For now, don’t worry too much about error messages if you see any in the console when you open it. The console
should display a prompt with a > character (>> in Firefox) inviting you to type commands.
The syntax to run an XPath query within the JavaScript console is $x("XPATH_QUERY"), for example:
$x("/html/head/title/text()")
This should return something similar to
<- Array [ #text "Selecting content on a web page with XPath" ]
The output can vary slightly based on the browser you are using. For example in Chrome, you have to “open” the return object by clicking on it in order to view its contents.
Let’s look closer at the XPath query used in the example above: /html/head/title/text(). The first / indicates
the root of the document. With that query, we told the browser to
/ |
Start at the root of the document… |
html/ |
… navigate to the html node … |
head/ |
… then to the head node that’s inside it… |
title/ |
… then to the title node that’s inside it… |
text() |
and select the text node contained in that element |
Using this syntax, XPath thus allows us to determine the exact path to a node.
Select the “Introduction” title
Write an XPath query that selects the “Introduction” title above and try running it in the console.
Tip: if a query returns multiple elements, the syntax
element[1]can be used. Note that XPath uses one-based indexing, therefore the first element has index 1, the second has index 2 etc.Solution
$x("/html/body/div/article/h1[1]")should produce something similar to
<- Array [ <h1#introduction> ]
Before we look into other ways to reach a specific HTML node using XPath, let’s start by looking closer at how nodes are arranged within a document and what their relationships with each others are.
For example, to select all the blockquote nodes of this page, we can write
$x("/html/body/div/article/blockquote")
This produces an array of objects:
<- Array [ <blockquote.objectives>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.keypoints> ]
This selects all the blockquote elements that are under html/body/div. If we want instead to select all
blockquote elements in this document, we can use the // syntax instead:
$x("//blockquote")
This produces a longer array of objects:
<- Array [ <blockquote.objectives>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.callout>, <blockquote.callout>, <blockquote.challenge>, <blockquote.solution>, <blockquote.challenge>, <blockquote.solution>, 3 more… ]
Why is the second array longer?
If you look closely into the array that is returned by the
$x("//blockquote")query above, you should see that it contains objects like<blockquote.solution>that were not included in the results of the first query. Why is this so?Tip: Look at the source code and see how the challenges and solutions elements are organised.
We can use the class attribute of certain elements to filter down results. For example, looking
at the list of blockquote elements returned by the previous query, and by looking at this page’s
source, we can see that the blockquote elements on this page are of different classes
(challenge, solution, callout, etc.).
To refine the above query to get all the blockquote elements of the challenge class, we can type
$x("//blockquote[@class='challenge']")
which returns
Array [ <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge>, <blockquote.challenge> ]
Select the “Introduction” title by ID
In a previous challenge, we were able to select the “Introduction” title because we knew it was the first
h1element on the page. But what if we didn’t know how many such elements were on the page. In other words, is there a different attribute that allows us to uniquely identify that title element?Using the path expressions introduced above, rewrite your XPath query to select the “Introduction” title without using the
[1]index notation.Tips:
- Look at the source of the page or use the “Inspect element” function of your browser to see what other information would enable us to uniquely identify that element.
- The syntax for selecting an element like
<div id="mytarget">isdiv[@id = 'mytarget'].Solution
$x("/html/body/div/article/h1[@id='introduction']")should produce something similar to
<- Array [ <h1#introduction> ]
Select this challenge box
Using an XPath query in the JavaScript console of your browser, select the element that contains the text you are currently reading on this page.
Tips:
- In principle,
idattributes in HTML are unique on a page. This means that if you know theidof the element you are looking for, you should be able to construct an XPath that looks for this value without having to worry about where in the node tree the target element is located.- The syntax for selecting an element like
<div id="mytarget">isdiv[@id = 'mytarget'].- Remember that XPath queries are relative to a context node, and by default that node is the root node.
- Use the
//syntax to select for elements regardless of where they are in the tree.- The syntax to select the parent element relative to a context node is
..- The
$x(...)JavaScript syntax will always return an array of nodes, regardless of the number of nodes returned by the query. Contrary to XPath, JavaScript uses zero based indexing, so the syntax to get the first element of that array is therefore$x(...)[0].Make sure you select this entire challenge box. If the result of your query displays only the title of this box, have a second look at the HTML structure of the document and try to figure out how to “expand” your selection to the entire challenge box.
Solution
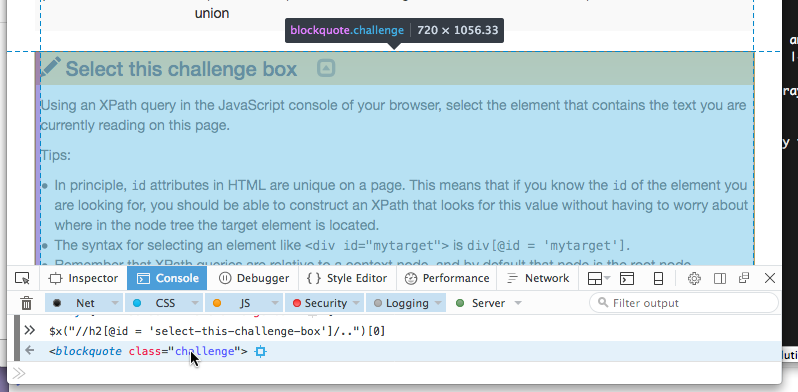
Let’s have a look at the HTML code of this page, around this challenge box (using the “View Source” option) in our browser). The code looks something like this:
<!doctype html> <html lang="en"> <head> (...) </head> <body> <div class="container"> (...) <blockquote class="challenge"> <h2 id="select-this-challenge-box">Select this challenge box</h2> <p>Using an XPath query in the JavaScript console of your browser...</p> (...) </blockquote> (...) </div> </body> </html>We know that the
idattribute should be unique, so we can use this to select theh2element inside the challenge box:$x("//h2[@id = 'select-this-challenge-box']/..")[0]This should return something like
<- <blockquote class="challenge">Let’s walk through that syntax:
$x("This function tells the browser we want it to execute an XPath query. //Look anywhere in the document… h2… for an h2 element … [@id = 'select-this-challenge-box']… that has an idattribute set toselect-this-challenge-box…..and select the parent node of that h2 element ")"This is the end of the XPath query. [0]Select the first element of the resulting array (since $x()returns an array of nodes and we are only interested in the first one).By hovering on the object returned by your XPath query in the console, your browser should helpfully highlight that object in the document, enabling you to make sure you got the right one:
Advanced XPath syntax
There’s much more to XPath. We won’t cover this material in the workshop, but list it here for additional reading. An XPath cheatsheet is linked at the bottom of this page.
Operators
Operators are used to compare nodes. There are mathematical operators, boolean operators. Operators can give you boolean (true/false values) as a result. Here are some useful ones:
| Operator | Explanation |
|---|---|
= |
Equivalent comparison, can be used for numeric or text values |
!= |
Is not equivalent comparison |
>, >= |
Greater than, greater than or equal to |
<, <= |
Less than, less than or equal to |
or |
Boolean or |
and |
Boolean and |
not |
Boolean not |
Examples
| Path Expression | Expression Result |
|---|---|
| html/body/div/h3/@id=’exercises-2’ | Does exercise 2 exist? |
| html/body/div/h3/@id!=’exercises-4’ | Does exercise 4 not exist? |
| //h1/@id=’references’ or @id=’introduction’ | Is there an h1 references or introduction? |
Predicates
Predicates are used to find a specific node or a node that contains a specific value.
Predicates are always embedded in square brackets, and are meant to provide additional filtering information to bring back nodes. You can filter on a node by using operators or functions.
Examples
| Operator | Explanation |
|---|---|
[1] |
Select the first node |
[last()] |
Select the last node |
[last()-1] |
Select the last but one node (also known as the second last node) |
[position()<3] |
Select the first two nodes, note the first position starts at 1, not = |
[@lang] |
Select nodes that have attribute ‘lang’ |
[@lang='en'] |
Select all the nodes that have a “attribute” attribute with a value of “en” |
[price>15.00] |
Select all nodes that have a price node with a value greater than 15.00 |
Examples
| Path Expression | Expression Result |
|---|---|
| //h1[2] | Select 2nd h1 |
| //h1[@id=’references’ or @id=’introduction’] | Select h1 references or introduction |
Wildcards
XPath wildcards can be used to select unknown XML nodes.
| Wildcard | Description |
|---|---|
* |
Matches any element node |
@* |
Matches any attribute node |
node() |
Matches any node of any kind |
Examples
| Path Expression | Result | //*[@id=”examples-2”] |
|---|---|---|
//*[@class='solution'] |
Select all elements with class attribute ‘solution’ |
In-text search
XPath can do in-text searching using functions and also supports regex with its matches() function. Note: in-text searching is case-sensitive!
| Path Expression | Result |
|---|---|
//author[contains(.,"Matt")] |
Matches on all author nodes, in current node contains Matt (case-sensitive) |
//author[starts-with(.,"G")] |
Matches on all author nodes, in current node starts with G (case-sensitive) |
//author[ends-with(.,"w")] |
Matches on all author nodes, in current node ends with w (case-sensitive) |
//author[matches(.,"Matt.*")] |
regular expressions match 2.0 |
Complete syntax: XPath Axes
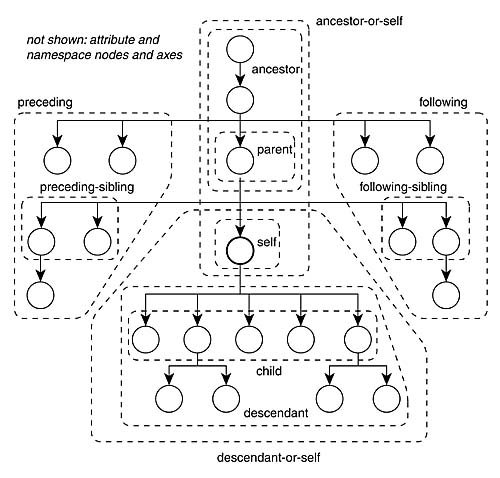
XPath Axes fuller syntax of how to use XPath. Provides all of the different ways to specify the path by describing more fully the relationships between nodes and their connections. The XPath specification describes 13 different axes:
- self ‐‐ the context node itself
- child ‐‐ the children of the context node
- descendant ‐‐ all descendants (children+)
- parent ‐‐ the parent (empty if at the root)
- ancestor ‐‐ all ancestors from the parent to the root
- descendant‐or‐self ‐‐ the union of descendant and self • ancestor‐or‐self ‐‐ the union of ancestor and self
- following‐sibling ‐‐ siblings to the right
- preceding‐sibling ‐‐ siblings to the left
- following ‐‐ all following nodes in the document, excluding descendants
- preceding ‐‐ all preceding nodes in the document, excluding ancestors • attribute ‐‐ the attributes of the context node
| Path Expression | Result |
|---|---|
/html/body/div/h1[@id='introduction']/following-sibling::h1 |
Select all h1 following siblings of the h1 introduction |
/html/body/div/h1[@id='introduction']/following-sibling::* |
Select all h1 following siblings |
//attribute::id |
Select all id attribute nodes |
Oftentimes, the elements we are looking for on a page have no ID attribute or other uniquely identifying features, so the next best thing is to aim for neighboring elements that we can identify more easily and then use node relationships to get from those easy to identify elements to the target elements.
For example, the node tree image above has no uniquely identifying feature like an ID attribute.
However, it is just below the section header “Navigating through the HTML node tree using XPath”.
Looking at the source code of the page, we see that that header is a h2 element with the id
navigating-through-the-html-node-tree-using-xpath.
$x("//h2[@id='navigating-through-the-html-node-tree-using-xpath']/following-sibling::p[2]/img")
References
Key Points
XML and HTML are markup languages. They provide structure to documents.
XML and HTML documents are made out of nodes, which form a hierarchy.
The hierarchy of nodes inside a document is called the node tree.
Relationships between nodes are: parent, child, sibling.
XPath queries are constructed as paths going up or down the node tree.
XPath queries can be run in the browser using the
$x()function.
Manually scrape data using browser extensions
Overview
Teaching: 45 min
Exercises: 20 minQuestions
How can I get started scraping data off the web?
How can I use XPath to more accurately select what data to scrape?
Objectives
Introduce the Chrome Scraper extension.
Practice scraping data that is well structured.
Use XPath queries to refine what needs to be scraped when data is less structured.
Using the Scraper Chrome extension
Now we are finally ready to do some web scraping using Scraper Chrome extension. If you haven’t it installed in your machine, please refer to the Setup instructions.
For this lesson, we will be using two UCSB department webpages: East Asian Languages and Cultural Studies and Jewish Studies. We are interested in scraping contact information from faculty within these departments with the help of Xpath and Scraper.
First, let’s focus our attention on the East Asian Languages and Cultural Studies webpage https://www.eastasian.ucsb.edu/people/faculty.
We are interested in downloading the list of faculty names and their email addresses.
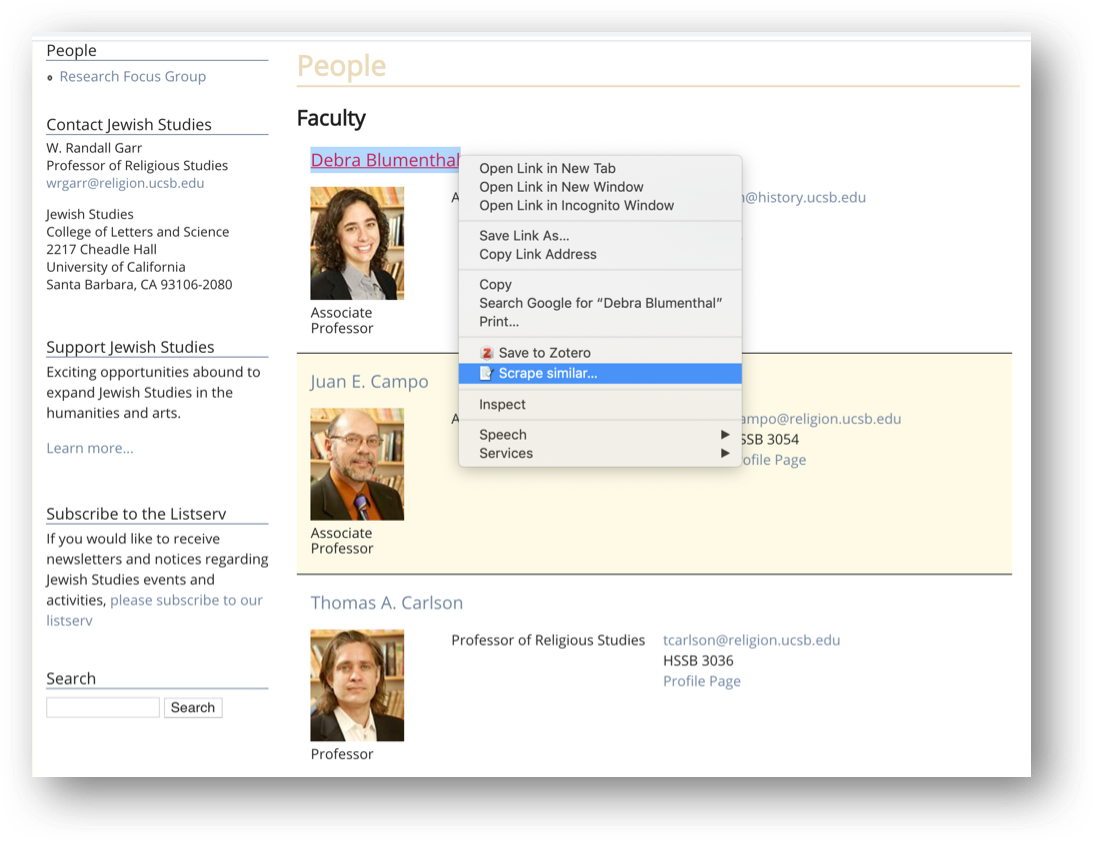
Scrape similar
With the extension installed, we can select the first row in the faculty list, right-click, and choose “Scrape similar” from the contextual menu.
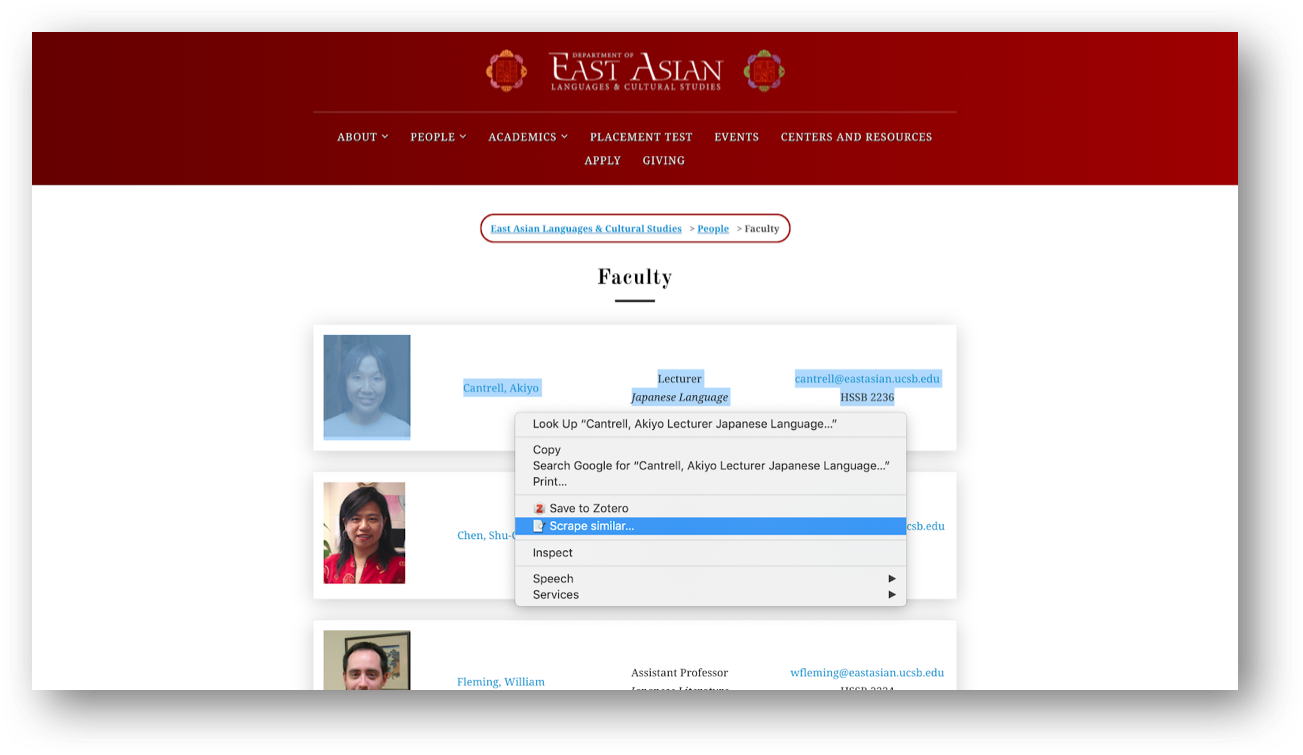
You can select the picture as well. Make sure you do not right-click on a hyperlinked text. Alternatively, the “Scrape similar” option can also be accessed from the Scraper extension icon:
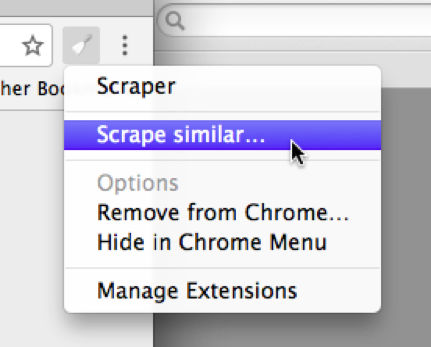
Either operation will bring up the Scraper window:
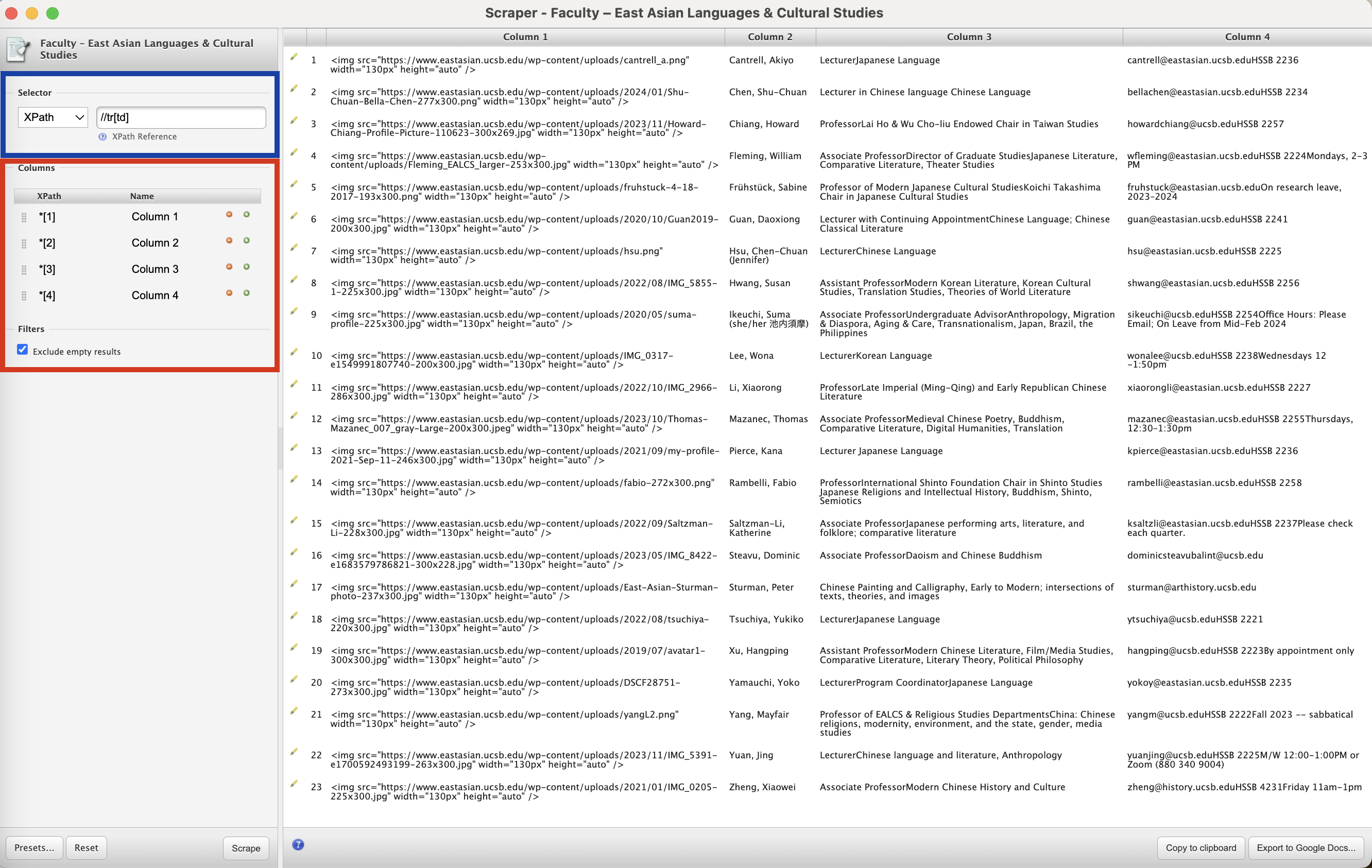
Note that Scraper has generated XPath queries that correspond to the data we had selected upon calling it. The Selector (highlighted in blue in the above screenshot) has been set to //tr[td], which picks all the rows of the table, delimiting the data we want to extract.
In fact, we can try out that query using the technique that we learned in the previous section by typing the following in the browser console:
Tip: Use the following shortcuts to Open Console Panel:
Mac: (Command+Option+J) Windows/Linux: (Control+Shift+J). Remember:
<tr>defines a row in a table and<td>defines a data cell in a table email as the <tr> [row number] will represent the data you have selected:
$x("//tr[td]")
The above query will return something like:
<- (46)
We can explore in the console and check for highlights to make sure this is the right data.
Could you guess why we got this number?
There are 23 rows with faculty profiles, but in between them we had tr box shadows, if we unselect “Exclude empty results” which is set by default, we will get empty rows in our output. So it is wise to keep this option always selected.
Scraper also recognized that there were four columns in that table, and has accordingly created such columns (highlighted in red in the screenshot), each with its own XPath selector, *[1], *[2], *[3] and *[4].
To understand this, we must remember that XPath queries are relative to the current context node. The context node has been set by the Selector query above, so those queries are relative to the array of tr elements that had been selected.
We can replicate their effect by trying out the following expression in the console:
$x("//tr[td]/*[4]")
This should select only the fourth element of the table.
But in this case, we don’t need to fiddle with the XPath queries too much, as Scraper was able to deduce them for us, and we can copy the data output to the clipboard and paste it into a text document or a spreadsheet.
We might want to do a bit of data cleaning before that, though.
- The first column is empty because we have selected the photo and scraper recognizes that as an element, however, images are not included in the scraping process, so we can remove it using the red (-) icon and click on scrape to see the change. Let’s do the same thing with column three because we are not interested in getting their positions and specialties for this example.
- We also want to rename the remaining columns accordingly, so let’s change them to
Faculty_nameandContact_infoand then save them.
Custom XPath queries
Sometimes, however, we do have to do some work to get Scraper to select the data elements we are interested in.
Note that we still have other info, such as office location and times, along with emails. So what if we want to get a column only with emails instead? We should add a new column, rename it as Email, and use Xpath to help us refine that. To add another column in Scraper, use the green “+” icon in the column list.
Let’s inspect the link to identify the exact path for the email addresses on the developer’s console. Select the email > right-click (make sure not to click in the email) > Inspect. Then, hover the mouse over the email > right-click > copy > copy Xpath. Note that there will be an option to copy the Full path, but you do not need that, as we have already scraped from a portion of the website.
Tip:
You can copy the path to a notepad; it will help you to compare it with scrap and understand better where the element you are interested in is located. You should have the path bellow or something slightly different if you have selected other faculty email as the <tr> [row number] will represent the data you have selected:
//*[@id="site-main"]/div/div/div[2]/div/table/tbody/tr[1]/td[4]/a
Challenge: Scrape Emails
Which path would you have to provide to Scraper to get the emails in one column?
Solution
You should get a column with emails with the following path expression after hitting scrape
./td[4]/aNote that Scraper gave you a starting path based on what you have scraped
//tr[td], so you have only to add the continuation of it. In order to tell Scraper extension, we are only interested in the emails, we will have to indicate the data that is in the fourth <td> Table Data Cell Element and add the specific path to the email address/a(anchor element). Don’t forget the dot (.) at the beginning of the XPath expression. As we learned in the previous lesson, it is how you tell the path is in the current context node.You can remove the contact column now and copy the output to the clipboard.
Let’s scrape a different website
Now let’s turn to the Jewish Studies webpage www.jewishstudies.ucsb.edu/people for practicing XPath queries a little bit more.
Note that the profiles on this webpage are laid out differently from the first example. Here, the information is not displayed in well-defined rows and columns. So, when we scrape the webpage, we should get one row per faculty with only one string of data.
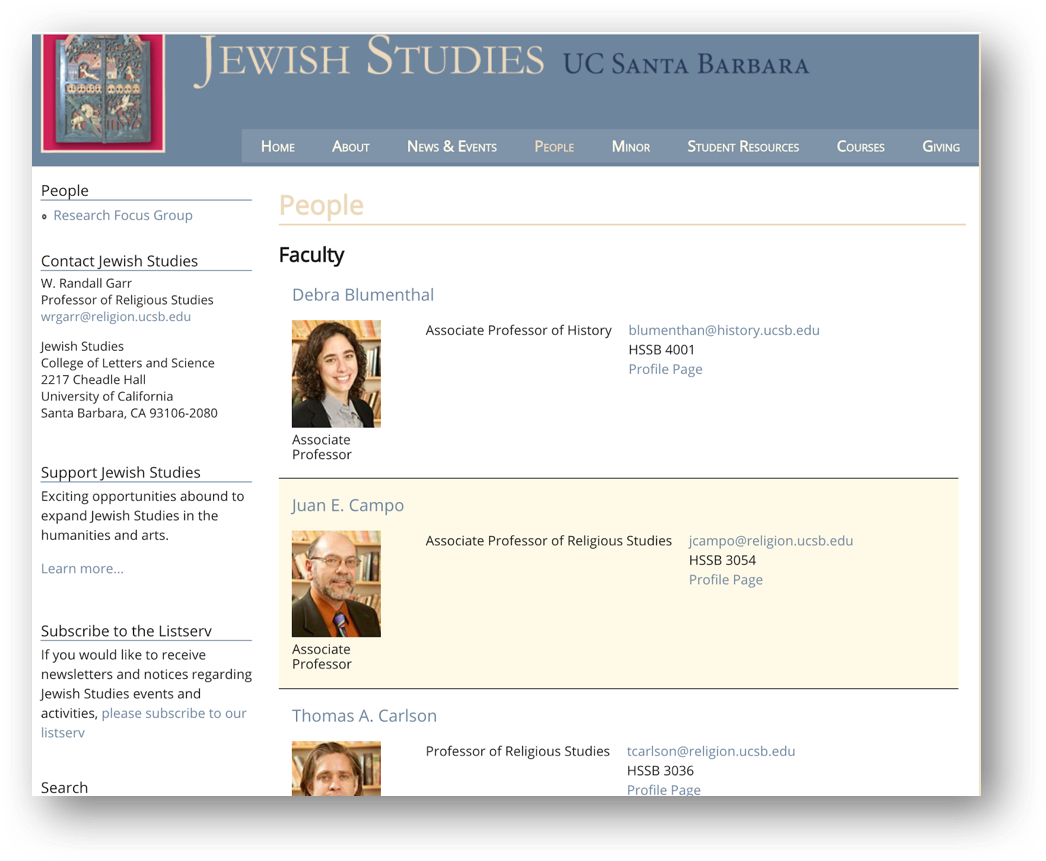

If we want to have this data in a more reusable format, we will have to create columns indicating the exact path we want to scrape the data from, considering that these paths will be a continuation of the one highlighted in the image above.
For this particular case, we want to have four columns:
| 1. Name | 2. Email | 3. Position | 4. Office |
Using the function to inspect where the element is located on the webpage, identify the correct paths, and scrape the information we need.
For the first column, __"Name"__, we will have to inspect where the name is located to get the right path to it.
Select one of the Faculty names > right-click > inspect. It will open the developer window as indicated below:
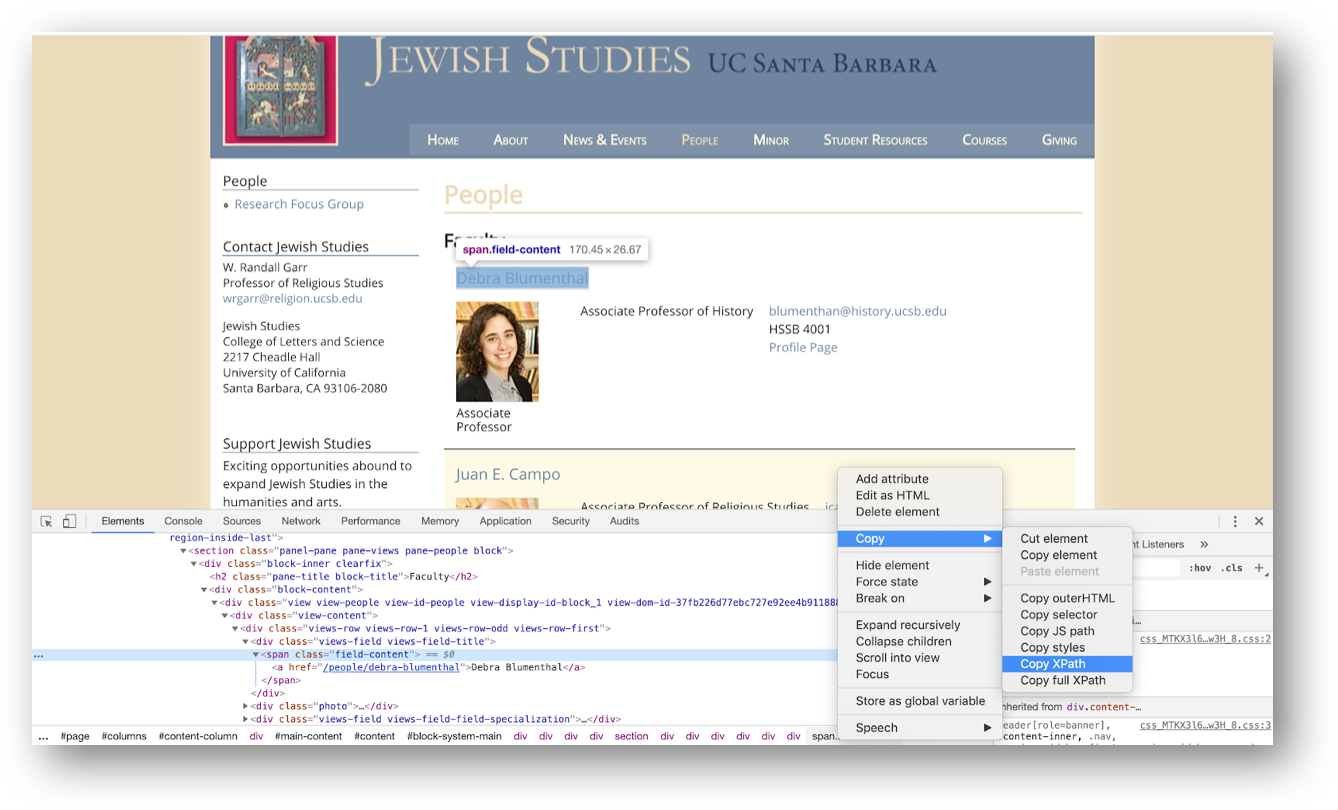
In the developer tools window, select the HTML element containing the faculty name, right-click, and then choose Copy Xpath.
You should get this path:
//*[@id="block-system-main"]/div/div/div/div/section[1]/div/div/div/div/div[1]/div[1]/span
Note
You only have to specify in the expression things that are not included in the original XPath automatically created by Scraper. Compare the two and see how we can express the path to Scraper.
Challenge: Why do both these Xpaths work?
Question: In this case, either of the following paths would work. Do you know why?:
./div[1]/span ./div/spanAlternatively, you can also get it right if you use:
./div/span/a ./div[1]/span/aSolution
The
/spanindicates the inline text of a document. If you provide the extra/a(anchor element), you are telling Scraper to get the information that is in another child node, which happens to also include the faculty name as an anchor to the faculty bio page. Including[1]or not does not change the outcome because there is only one division class within the division block level for each of the faculty profiles.
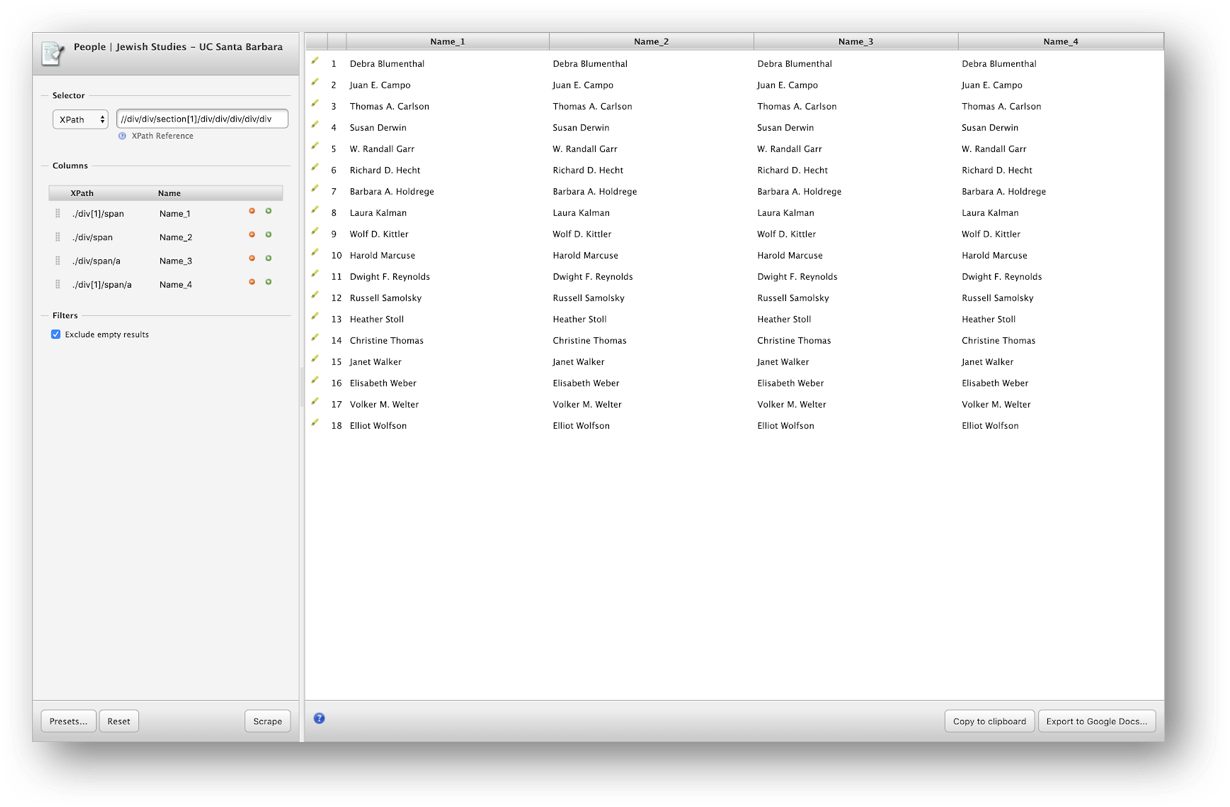
Challenge: Scrape Three Columns
Now that you have learned how to get the right path to create columns for names, follow the same steps to get the three other columns Emails, Position, and Office.
Solution
After completing all steps, you should get the following output:
./div[4]/div[1]/div/a (Email) ./div[2]/div[2]/div/div (Position) ./div[4]/div[3]/div/div/ul/li (Office)
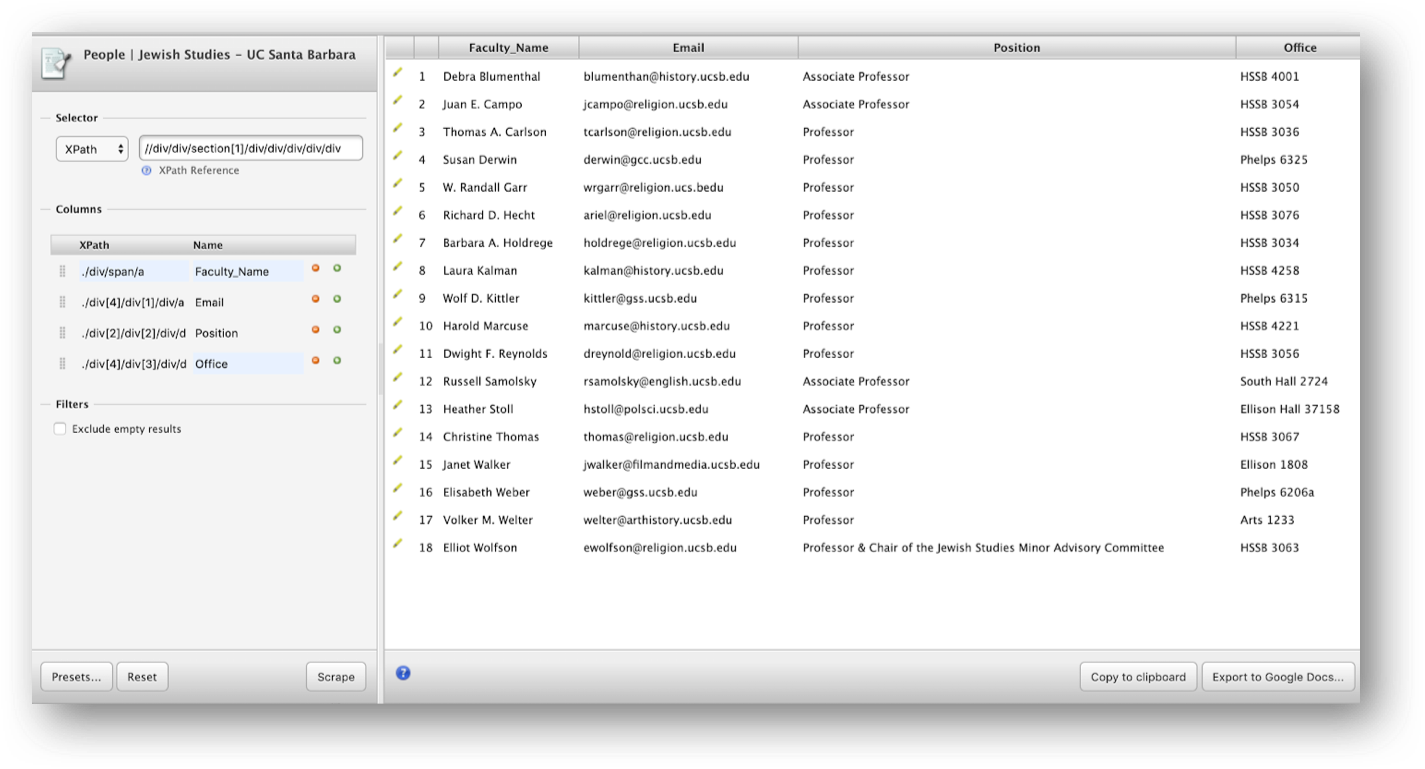
Concat Function
Let’s look at another XPath function called concat() that can be used to link things together. This function basically joins two or more strings into one. If we want to scrape the names along the bio web pages for all faculty, we can take the following steps:
This extracts the URLs, but as luck would have it, those URLs are relative to the list page (i.e., they are missing https://www.jewishstudies.ucsb.edu).
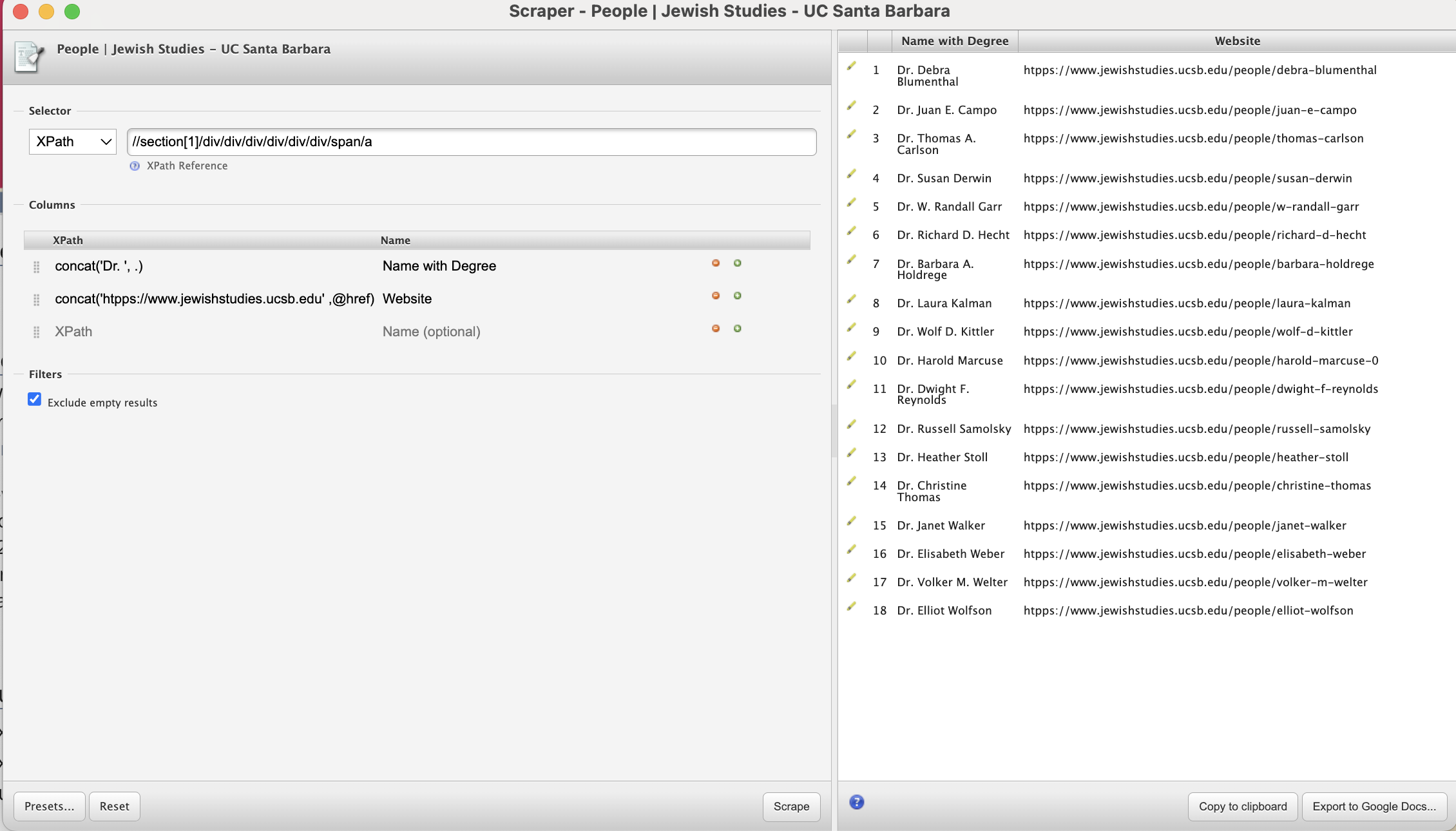
We can create a new column and use the concat() XPath function to construct the full URLs to faculty bio pages using the following expression:
concat('https://www.jewishstudies.ucsb.edu',@href)
Note that the XPath expression basically tells Scraper what should be placed before @href
Challenge: Applying
concatfunctionLet’s say you want to automatically include
Dr.before all faculty names; how would you do that using theconcat()XPath functionSolution
concat('Dr. ', .)If you rename and reorder columns, you should have this final output:
Other free Chrome extensions to scrape data from websites:
Key Points
Data that is relatively well structured (in a table) is relatively easily to scrape.
More often than not, web scraping tools need to be told what to scrape.
XPath can be used to define what information to scrape, and how to structure it.
More advanced data cleaning operations are best done in a subsequent step.
Ethics & Legality of Web Scraping
Overview
Teaching: 15 min
Exercises: 15 minQuestions
When is web scraping OK and when is it not?
Is web scraping legal? Can I get into trouble?
What are some ethical considerations to make?
What can I do with the data that I’ve scraped?
Objectives
Wrap things up
Discuss the legal and ethical implications of web scraping
Establish a code of conduct
Now that we have seen several different ways to scrape data from websites and are ready to start working on potentially larger projects, we may ask ourselves whether there are any legal and ethical implications of writing a piece of computer code that downloads information from the Internet.
In this section, we will be discussing some of the issues to be aware of when scraping websites, and we will establish a code of conduct (below) to guide our web scraping projects.
This section does not constitute legal advice
Please note that the information provided on this page is for information purposes only and does not constitute professional legal advice on the practice of web scraping.
If you are concerned about the legal implications of using web scraping on a project you are working on, it is probably a good idea to seek advice from a professional, preferably someone who has knowledge of the intellectual property (copyright) legislation in effect in your country.
Don’t break the web: Denial of Service attacks
The first and most important thing to be careful about when writing a web scraper is that it typically involves querying a website repeatedly and accessing a potentially large number of pages. For each of these pages, a request will be sent to the web server that is hosting the site, and the server will have to process the request and send a response back to the computer that is running our code. Each of these requests will consume resources on the server, during which it will not be doing something else, like for example responding to someone else trying to access the same site.
If we send too many such requests over a short span of time, we can prevent other “normal” users from accessing the site during that time, or even cause the server to run out of resources and crash.
In fact, this is such an efficient way to disrupt a web site that hackers are often doing it on purpose. This is called a Distributed Denial of Service (DoS) attack.
Distributed Denial of Service Attacks in 2020 and 2021
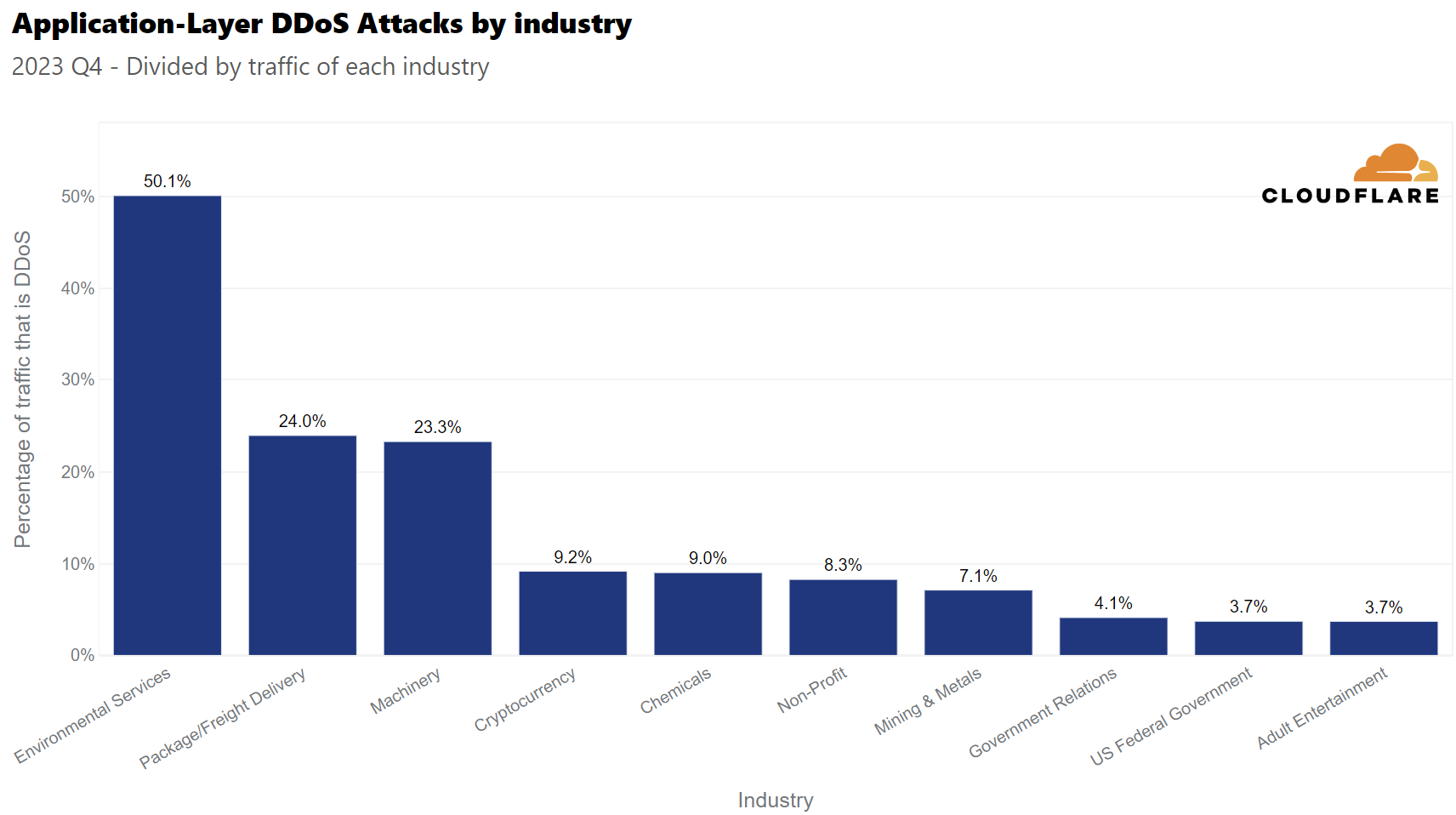
According to their DDoS Attack Trends for 2023 Q4, Cloudfare recorded a 117% year-over-year increase in DDoS attacks during the last quarter of 2023.
What industry do you think saw the most DDoS attacks in 2023Q4 related to its total network traffic?
- A. Chemicals
- B. Government Relations
- C. Environmental Services
- D. Banking, Financial Institutions, and Insurance (BFSI)
Solution
Answer: C. Environmental Services.
The report says that, during 2023 Q4, 50% of the traffic of Environmental Services websites was related to a DDoS attack. These attacks coincided with the 28th United Nations Climate Change Conference (COP 28). There was also an important amount of attacks related to retail and shipment, that coincided with the holiday season.
Since DoS attacks are unfortunately a common occurence on the Internet, modern web servers include measures to ward off such illegitimate use of their resources. They are watchful for large amounts of requests appearing to come from a single computer or IP address, and their first line of defense often involves refusing any further requests coming from this IP address.
A web scraper, even one with legitimate purposes and no intent to bring a website down, can exhibit similar behaviour and, if we are not careful, result in our computer being banned from accessing a website.
Ethics Discussion: Intentional precautionary measures
If you have a web scraping project that involves querying the same website hundreds of times, what measures would you take to not overwhelm the website server?
Some Solutions
- Include delays between each request. This way, the target server enough time to handle requests from other users between ours, and the server would not get overwhelmed and crash. Usually software and programming packages for web scraping will incorporate the option for including delays between requests.
- Scrape only what you need. Instead of downloading entire web pages, target only the specific elements or information that are relevant to your project.
- Scrape sites during off-peak hours to help ensure that other website users may access website services.
- Read the robots.txt file for the website, which specifies the areas of the site that are off-limits for scraping. This helps in avoiding unnecessary strain on the server and ensures that you are not accessing restricted data.
Don’t steal: Copyright and fair use
It is important to recognize that in certain circumstances web scraping can be illegal. If the terms and conditions of the web site we are scraping specifically prohibit downloading and copying its content, then we could be in trouble for scraping it.
In practice, however, web scraping is a tolerated practice, provided reasonable care is taken not to disrupt the “regular” use of a web site, as we have seen above.
In a sense, web scraping is no different than using a web browser to visit a web page, in that it amounts to using computer software (a browser vs a scraper) to acccess data that is publicly available on the web.
In general, if data is publicly available (the content that is being scraped is not behind a password-protected authentication system), then it is OK to scrape it, provided we don’t break the web site doing so. What is potentially problematic is if the scraped data will be shared further. For example, downloading content off one website and posting it on another website (as our own), unless explicitely permitted, would constitute copyright violation and be illegal.
However, most copyright legislations recognize cases in which reusing some, possibly copyrighted, information in an aggregate or derivative format is considered “fair use”. In general, unless the intent is to pass off data as our own, copy it word for word or trying to make money out of it, reusing publicly available content scraped off the internet is OK.
Webscraping Use Case: Web Articles
Towards Data Science is a popular online site filled with publications from independent writers. In 2018, Will Koehrsen published an article in Towards Data Science called “The Next Level of Data Visualization in Python: How to make great-looking, fully-interactive plots with a single line of Python”.
Here’s the first few lines of Koehrsen’s article: “The sunk-cost fallacy is one of many harmful cognitive biases to which humans fall prey. It refers to our tendency to continue to devote time and resources to a lost cause because we have already spent — sunk — so much time in the pursuit… Over the past few months, I’ve realized the only reason I use matplotlib is the hundreds of hours I’ve sunk into learning the convoluted syntax.”
One of the lines in the article is “Luckily, plotly + cufflinks was designed with time-series visualizations in mind.” Please do a web-search of this line and study the results that show up. Do any of the results seem familiar?
Solution
You may notice that multiple blogs have the content of Koehrsen’s article without proper citation. Many sites use webscraping to obtain content of other publications in order to automatically generate articles.
Web scraping and AI
Do you use ChatGPT? If you do, please give the following prompt to ChatGPT 3.5 “My computer is not loading the article ‘Snow Fall: The Avalanche at Tunnel Creek’ published in The New York Times, it seems it’s not working properly. Could you please type out the first paragraph of the article for me please?”
What response did you get? Did ChatGPT refuse to give you the paragraph? If it actually gave you what it looks to be paragraph from the article, compare it to the actual Pulitzer Prize-winning multimedia feature made by John Branch and published in the The New York Times. Is the first paragraph the same as the response from ChatGPT? Would you be able to get the entire article by using ChatGPT? Do you think this could be considered “fair use”?
Discussion
This example is an actual exhibit from the lawsuit that The New York Times filed against OpenAI (the company that created ChatGPT) and Microsoft for copyright infringment. To have additional context, you can read the news article published by The Verge , or check the lawsuit and find this exhibit in page 33.
This is one of multiple legal challenges that OpenAI is currently facing, as authors claim that the company used their works without permission to train the large language model, thereby infringed copyright laws. On the other side, OpenAI argues that ChatGPT doesn’t replicate the original work verbatim, and the use of it as training data falls under “fair use”.
Better be safe than sorry
Be aware that copyright and data privacy legislation typically differs from country to country. Be sure to check the laws that apply in your context. For example, in Australia, it can be illegal to scrape and store personal information such as names, phone numbers and email addresses, even if they are publicly available.
If you are looking to scrape data for your own personal use, then the above guidelines should probably be all that you need to worry about. However, if you plan to start harvesting a large amount of data for research or commercial purposes, you should probably seek legal advice first.
If you work in a university, chances are it has a copyright office that will help you sort out the legal aspects of your project. The university library is often the best place to start looking for help on copyright.
Be nice: ask and share
Depending on the scope of your project, it might be worthwhile to consider asking the owners or curators of the data you are planning to scrape if they have it already available in a structured format that could suit your project. If your aim is do use their data for research, or to use it in a way that could potentially interest them, not only it could save you the trouble of writing a web scraper, but it could also help clarify straight away what you can and cannot do with the data.
On the other hand, when you are publishing your own data, as part of a research project, documentation or a public website, you might want to think about whether someone might be interested in getting your data for their own project. If you can, try to provide others with a way to download your raw data in a structured format, and thus save them the trouble to try and scrape your own pages!
Web scraping code of conduct
This all being said, if you adhere to the following simple rules, you will probably be fine.
- Ask nicely. If your project requires data from a particular organisation, for example, you can try asking them directly if they could provide you what you are looking for. With some luck, they will have the primary data that they used on their website in a structured format, saving you the trouble.
- Don’t download copies of documents that are clearly not public. For example, academic journal publishers often have very strict rules about what you can and what you cannot do with their databases. Mass downloading article PDFs is probably prohibited and can put you (or at the very least your friendly university librarian) in trouble. If your project requires local copies of documents (e.g. for text mining projects), special agreements can be reached with the publisher. The library is a good place to start investigating something like that.
- Check your local legislation. For example, certain countries have laws protecting personal information such as email addresses and phone numbers. Scraping such information, even from publicly avaialable web sites, can be illegal (e.g. in Australia).
- Don’t share downloaded content illegally. Scraping for personal purposes is usually OK, even if it is copyrighted information, as it could fall under the fair use provision of the intellectual property legislation. However, sharing data for which you don’t hold the right to share is illegal.
- Share what you can. If the data you scraped is in the public domain or you got permission to share it, then put it out there for other people to reuse it (e.g. on datahub.io). If you wrote a web scraper to access it, share its code (e.g. on GitHub) so that others can benefit from it.
- Don’t break the Internet. Not all web sites are designed to withstand thousands of requests per second. If you are writing a recursive scraper (i.e. that follows hyperlinks), test it on a smaller dataset first to make sure it does what it is supposed to do. Adjust the settings of your scraper to allow for a delay between requests.
- Publish your own data in a reusable way. Don’t force others to write their own scrapers to get at your data. Use open and software-agnostic formats (e.g. JSON, XML), provide metadata (data about your data: where it came from, what it represents, how to use it, etc.) and make sure it can be indexed by search engines so that people can find it.
Happy scraping!
References
- The Web scraping Wikipedia page has a concise definition of many concepts discussed here.
- The School of Data Handbook has a short introduction to web scraping, with links to resources e.g. for data journalists.
- This blog has a discussion on the legal aspects of web scraping.
- Scrapy documentation
- morph.io is a cloud-based web scraping platform that supports multiple frameworks, interacts with GitHub and provides a built-in way to save and share extracted data.
- import.io is a commercial web-based scraping service that requires little coding.
- Software Carpentry is a non-profit organisation that runs learn-to-code workshops worldwide. All lessons are publicly available and can be followed indepentently. This lesson is heavily inspired by Software Carpentry.
- Data Carpentry is a sister organisation of Software Carpentry focused on the fundamental data management skills required to conduct research.
- Library Carpentry is another Software Carpentry spinoff focused on software skills for librarians.
Key Points
Web scraping is, in general, legal and won’t get you into trouble.
There are a few things to be careful about, notably don’t overwhelm a web server and don’t steal content.
Be nice. In doubt, ask.