Content from Automated Version Control
Last updated on 2023-09-25 | Edit this page
Overview
Questions
- What is version control and why should I use it?
Objectives
- Understand the benefits of an automated version control system.
- Understand the basics of how automated version control systems work.
We’ll start by exploring how version control can be used to keep track of what one person did and when. Even if you aren’t collaborating with other people, automated version control is much better than this situation:

We’ve all been in this situation before: it seems unnecessary to have multiple nearly-identical versions of the same document. Some word processors let us deal with this a little better, such as Microsoft Word’s Track Changes, Google Docs’ version history, or LibreOffice’s Recording and Displaying Changes.
Version control systems start with a base version of the document and then record changes you make each step of the way. You can think of it as a recording of your progress: you can rewind to start at the base document and play back each change you made, eventually arriving at your more recent version.

Once you think of changes as separate from the document itself, you can then think about “playing back” different sets of changes on the base document, ultimately resulting in different versions of that document. For example, two users can make independent sets of changes on the same document.

Unless multiple users make changes to the same section of the document - a conflict - you can incorporate two sets of changes into the same base document.

A version control system is a tool that keeps track of these changes for us, effectively creating different versions of our files. It allows us to decide which changes will be made to the next version (each record of these changes is called a commit), and keeps useful metadata about them. The complete history of commits for a particular project and their metadata make up a repository. Repositories can be kept in sync across different computers, facilitating collaboration among different people.
The Long History of Version Control Systems
Automated version control systems are nothing new. Tools like RCS, CVS, or Subversion have been around since the early 1980s and are used by many large companies. However, many of these are now considered legacy systems (i.e., outdated) due to various limitations in their capabilities. More modern systems, such as Git and Mercurial, are distributed, meaning that they do not need a centralized server to host the repository. These modern systems also include powerful merging tools that make it possible for multiple authors to work on the same files concurrently.
Paper Writing
Imagine you drafted an excellent paragraph for a paper you are writing, but later ruin it. How would you retrieve the excellent version of your conclusion? Is it even possible?
Imagine you have 5 co-authors. How would you manage the changes and comments they make to your paper? If you use LibreOffice Writer or Microsoft Word, what happens if you accept changes made using the
Track Changesoption? Do you have a history of those changes?
Recovering the excellent version is only possible if you created a copy of the old version of the paper. The danger of losing good versions often leads to the problematic workflow illustrated in the PhD Comics cartoon at the top of this page.
Collaborative writing with traditional word processors is cumbersome. Either every collaborator has to work on a document sequentially (slowing down the process of writing), or you have to send out a version to all collaborators and manually merge their comments into your document. The ‘track changes’ or ‘record changes’ option can highlight changes for you and simplifies merging, but as soon as you accept changes you will lose their history. You will then no longer know who suggested that change, why it was suggested, or when it was merged into the rest of the document. Even online word processors like Google Docs or Microsoft Office Online do not fully resolve these problems.
Key Points
- Version control is like an unlimited ‘undo’.
- Version control also allows many people to work in parallel.
Content from Navigating Files and Directories
Last updated on 2023-10-10 | Edit this page
Overview
Questions
- How can I move around on my computer?
- How can I see what files and directories I have?
- How can I specify the location of a file or directory on my computer?
Objectives
- Explain the similarities and differences between a file and a directory.
- Translate an absolute path into a relative path and vice versa.
- Construct absolute and relative paths that identify specific files and directories.
- Use options and arguments to change the behaviour of a shell command.
- Demonstrate the use of tab completion and explain its advantages.
The part of the operating system responsible for managing files and directories is called the file system. It organizes our data into files, which hold information, and directories (also called ‘folders’), which hold files or other directories.
Several commands are frequently used to create, inspect, rename, and delete files and directories. To start exploring them, we’ll go to our open shell window.
First, let’s find out where we are by running a command called
pwd (which stands for ‘print working directory’).
Directories are like places — at any time while we are using
the shell, we are in exactly one place called our current
working directory. Commands mostly read and write files in the
current working directory, i.e. ‘here’, so knowing where you are before
running a command is important. pwd shows you where you
are:
OUTPUT
/Users/nelleHere, the computer’s response is /Users/nelle, which is
Nelle’s home directory:
Home Directory Variation
The home directory path will look different on different operating
systems. On Linux, it may look like /home/nelle, and on
Windows, it will be similar to
C:\Documents and Settings\nelle or
C:\Users\nelle. (Note that it may look slightly different
for different versions of Windows.) In future examples, we’ve used Mac
output as the default - Linux and Windows output may differ slightly but
should be generally similar.
We will also assume that your pwd command returns your
user’s home directory. If pwd returns something different,
you may need to navigate there using cd or some commands in
this lesson will not work as written. See Exploring Other Directories for
more details on the cd command.
To understand what a ‘home directory’ is, let’s have a look at how the file system as a whole is organized. For the sake of this example, we’ll be illustrating the filesystem on our scientist Nelle’s computer. After this illustration, you’ll be learning commands to explore your own filesystem, which will be constructed in a similar way, but not be exactly identical.
On Nelle’s computer, the filesystem looks like this:

The filesystem looks like an upside down tree. The topmost directory
is the root directory that holds everything else. We
refer to it using a slash character, /, on its own; this
character is the leading slash in /Users/nelle.
Inside that directory are several other directories: bin
(which is where some built-in programs are stored), data
(for miscellaneous data files), Users (where users’
personal directories are located), tmp (for temporary files
that don’t need to be stored long-term), and so on.
We know that our current working directory /Users/nelle
is stored inside /Users because /Users is the
first part of its name. Similarly, we know that /Users is
stored inside the root directory / because its name begins
with /.
Slashes
Notice that there are two meanings for the / character.
When it appears at the front of a file or directory name, it refers to
the root directory. When it appears inside a path, it’s just a
separator.
Underneath /Users, we find one directory for each user
with an account on Nelle’s machine, her colleagues imhotep and
larry.

The user imhotep’s files are stored in
/Users/imhotep, user larry’s in
/Users/larry, and Nelle’s in /Users/nelle.
Nelle is the user in our examples here; therefore, we get
/Users/nelle as our home directory. Typically, when you
open a new command prompt, you will be in your home directory to
start.
Now let’s learn the command that will let us see the contents of our
own filesystem. We can see what’s in our home directory by running
ls:
OUTPUT
Applications Documents Library Music Public
Desktop Downloads Movies Pictures(Again, your results may be slightly different depending on your operating system and how you have customized your filesystem.)
ls prints the names of the files and directories in the
current directory. We can make its output more comprehensible by using
the -F option which tells ls
to classify the output by adding a marker to file and directory names to
indicate what they are:
- a trailing
/indicates that this is a directory -
@indicates a link -
*indicates an executable
Depending on your shell’s default settings, the shell might also use colors to indicate whether each entry is a file or directory.
OUTPUT
Applications/ Documents/ Library/ Music/ Public/
Desktop/ Downloads/ Movies/ Pictures/Here, we can see that the home directory contains only sub-directories. Any names in the output that don’t have a classification symbol are files in the current working directory.
Clearing your terminal
If your screen gets too cluttered, you can clear your terminal using
the clear command. You can still access previous commands
using ↑ and ↓ to move line-by-line, or by
scrolling in your terminal.
Getting help
ls has lots of other options. There are
two common ways to find out how to use a command and what options it
accepts — depending on your environment, you might find that
only one of these ways works:
- We can pass a
--helpoption to any command (available on Linux and Git Bash), for example:
- We can read its manual with
man(available on Linux and macOS):
We’ll describe both ways next.
Help for built-in commands
Some commands are built in to the Bash shell, rather than existing as
separate programs on the filesystem. One example is the cd
(change directory) command. If you get a message like
No manual entry for cd, try help cd instead.
The help command is how you get usage information for Bash
built-ins.
The --help option
Most bash commands and programs that people have written to be run
from within bash, support a --help option that displays
more information on how to use the command or program.
OUTPUT
Usage: ls [OPTION]... [FILE]...
List information about the FILEs (the current directory by default).
Sort entries alphabetically if neither -cftuvSUX nor --sort is specified.
Mandatory arguments to long options are mandatory for short options, too.
-a, --all do not ignore entries starting with .
-A, --almost-all do not list implied . and ..
--author with -l, print the author of each file
-b, --escape print C-style escapes for nongraphic characters
--block-size=SIZE scale sizes by SIZE before printing them; e.g.,
'--block-size=M' prints sizes in units of
1,048,576 bytes; see SIZE format below
-B, --ignore-backups do not list implied entries ending with ~
-c with -lt: sort by, and show, ctime (time of last
modification of file status information);
with -l: show ctime and sort by name;
otherwise: sort by ctime, newest first
-C list entries by columns
--color[=WHEN] colorize the output; WHEN can be 'always' (default
if omitted), 'auto', or 'never'; more info below
-d, --directory list directories themselves, not their contents
-D, --dired generate output designed for Emacs' dired mode
-f do not sort, enable -aU, disable -ls --color
-F, --classify append indicator (one of */=>@|) to entries
... ... ...The man command
The other way to learn about ls is to type
This command will turn your terminal into a page with a description
of the ls command and its options.
To navigate through the man pages, you may use
↑ and ↓ to move line-by-line, or try B
and Spacebar to skip up and down by a full page. To search
for a character or word in the man pages, use /
followed by the character or word you are searching for. Sometimes a
search will result in multiple hits. If so, you can move between hits
using N (for moving forward) and
Shift+N (for moving backward).
To quit the man pages, press
Q.
Manual pages on the web
Of course, there is a third way to access help for commands:
searching the internet via your web browser. When using internet search,
including the phrase unix man page in your search query
will help to find relevant results.
GNU provides links to its manuals including the core GNU utilities, which covers many commands introduced within this lesson.
Exploring More ls Options
You can also use two options at the same time. What does the command
ls do when used with the -l option? What about
if you use both the -l and the -h option?
Some of its output is about properties that we do not cover in this lesson (such as file permissions and ownership), but the rest should be useful nevertheless.
The -l option makes ls use a
long listing format, showing not only the
file/directory names but also additional information, such as the file
size and the time of its last modification. If you use both the
-h option and the -l option, this makes the
file size ‘human readable’, i.e. displaying something
like 5.3K instead of 5369.
Listing in Reverse Chronological Order
By default, ls lists the contents of a directory in
alphabetical order by name. The command ls -t lists items
by time of last change instead of alphabetically. The command
ls -r lists the contents of a directory in reverse order.
Which file is displayed last when you combine the -t and
-r options? Hint: You may need to use the -l
option to see the last changed dates.
The most recently changed file is listed last when using
-rt. This can be very useful for finding your most recent
edits or checking to see if a new output file was written.
Exploring Other Directories
Not only can we use ls on the current working directory,
but we can use it to list the contents of a different directory. Let’s
take a look at our Desktop directory by running
ls -F Desktop, i.e., the command ls with the
-F option and the argument
Desktop. The argument Desktop tells
ls that we want a listing of something other than our
current working directory:
OUTPUT
shell-lesson-data/Note that if a directory named Desktop does not exist in
your current working directory, this command will return an error.
Typically, a Desktop directory exists in your home
directory, which we assume is the current working directory of your bash
shell.
Your output should be a list of all the files and sub-directories in
your Desktop directory, including the shell-lesson-data
directory you downloaded at the setup for this
lesson. (On most systems, the contents of the Desktop
directory in the shell will show up as icons in a graphical user
interface behind all the open windows. See if this is the case for
you.)
Organizing things hierarchically helps us keep track of our work. While it’s possible to put hundreds of files in our home directory just as it’s possible to pile hundreds of printed papers on our desk, it’s much easier to find things when they’ve been organized into sensibly-named subdirectories.
Now that we know the shell-lesson-data directory is
located in our Desktop directory, we can do two things.
First, using the same strategy as before, we can look at its contents
by passing a directory name to ls:
OUTPUT
exercise-data/ north-pacific-gyre/Second, we can actually change our location to a different directory, so we are no longer located in our home directory.
The command to change locations is cd followed by a
directory name to change our working directory. cd stands
for ‘change directory’, which is a bit misleading. The command doesn’t
change the directory; it changes the shell’s current working directory.
In other words it changes the shell’s settings for what directory we are
in. The cd command is akin to double-clicking a folder in a
graphical interface to get into that folder.
Let’s say we want to move into the exercise-data
directory we saw above. We can use the following series of commands to
get there:
These commands will move us from our home directory into our Desktop
directory, then into the shell-lesson-data directory, then
into the exercise-data directory. You will notice that
cd doesn’t print anything. This is normal. Many shell
commands will not output anything to the screen when successfully
executed. But if we run pwd after it, we can see that we
are now in
/Users/nelle/Desktop/shell-lesson-data/exercise-data.
If we run ls -F without arguments now, it lists the
contents of
/Users/nelle/Desktop/shell-lesson-data/exercise-data,
because that’s where we now are:
OUTPUT
/Users/nelle/Desktop/shell-lesson-data/exercise-dataOUTPUT
alkanes/ animal-counts/ creatures/ numbers.txt writing/We now know how to go down the directory tree (i.e. how to go into a subdirectory), but how do we go up (i.e. how do we leave a directory and go into its parent directory)? We might try the following:
ERROR
-bash: cd: shell-lesson-data: No such file or directoryBut we get an error! Why is this?
With our methods so far, cd can only see sub-directories
inside your current directory. There are different ways to see
directories above your current location; we’ll start with the
simplest.
There is a shortcut in the shell to move up one directory level. It works as follows:
.. is a special directory name meaning “the directory
containing this one”, or more succinctly, the parent of
the current directory. Sure enough, if we run pwd after
running cd .., we’re back in
/Users/nelle/Desktop/shell-lesson-data:
OUTPUT
/Users/nelle/Desktop/shell-lesson-dataThe special directory .. doesn’t usually show up when we
run ls. If we want to display it, we can add the
-a option to ls -F:
OUTPUT
./ ../ exercise-data/ north-pacific-gyre/-a stands for ‘show all’ (including hidden files); it
forces ls to show us file and directory names that begin
with ., such as .. (which, if we’re in
/Users/nelle, refers to the /Users directory).
As you can see, it also displays another special directory that’s just
called ., which means ‘the current working directory’. It
may seem redundant to have a name for it, but we’ll see some uses for it
soon.
Note that in most command line tools, multiple options can be
combined with a single - and no spaces between the options;
ls -F -a is equivalent to ls -Fa.
These three commands are the basic commands for navigating the
filesystem on your computer: pwd, ls, and
cd. Let’s explore some variations on those commands. What
happens if you type cd on its own, without giving a
directory?
How can you check what happened? pwd gives us the
answer!
OUTPUT
/Users/nelleIt turns out that cd without an argument will return you
to your home directory, which is great if you’ve got lost in your own
filesystem.
Let’s try returning to the exercise-data directory from
before. Last time, we used three commands, but we can actually string
together the list of directories to move to exercise-data
in one step:
Check that we’ve moved to the right place by running pwd
and ls -F.
If we want to move up one level from the data directory, we could use
cd ... But there is another way to move to any directory,
regardless of your current location.
So far, when specifying directory names, or even a directory path (as
above), we have been using relative paths. When you use
a relative path with a command like ls or cd,
it tries to find that location from where we are, rather than from the
root of the file system.
However, it is possible to specify the absolute path
to a directory by including its entire path from the root directory,
which is indicated by a leading slash. The leading / tells
the computer to follow the path from the root of the file system, so it
always refers to exactly one directory, no matter where we are when we
run the command.
This allows us to move to our shell-lesson-data
directory from anywhere on the filesystem (including from inside
exercise-data). To find the absolute path we’re looking
for, we can use pwd and then extract the piece we need to
move to shell-lesson-data.
OUTPUT
/Users/nelle/Desktop/shell-lesson-data/exercise-dataRun pwd and ls -F to ensure that we’re in
the directory we expect.
Two More Shortcuts
The shell interprets a tilde (~) character at the start
of a path to mean “the current user’s home directory”. For example, if
Nelle’s home directory is /Users/nelle, then
~/data is equivalent to /Users/nelle/data.
This only works if it is the first character in the path;
here/there/~/elsewhere is not
here/there/Users/nelle/elsewhere.
Another shortcut is the - (dash) character.
cd will translate - into the previous
directory I was in, which is faster than having to remember, then
type, the full path. This is a very efficient way of moving
back and forth between two directories – i.e. if you execute
cd - twice, you end up back in the starting directory.
The difference between cd .. and cd - is
that the former brings you up, while the latter brings you
back.
Try it! First navigate to ~/Desktop/shell-lesson-data
(you should already be there).
Then cd into the exercise-data/creatures
directory
Now if you run
you’ll see you’re back in ~/Desktop/shell-lesson-data.
Run cd - again and you’re back in
~/Desktop/shell-lesson-data/exercise-data/creatures
Absolute vs Relative Paths
Starting from /Users/nelle/data, which of the following
commands could Nelle use to navigate to her home directory, which is
/Users/nelle?
cd .cd /cd /home/nellecd ../..cd ~cd homecd ~/data/..cdcd ..
- No:
.stands for the current directory. - No:
/stands for the root directory. - No: Nelle’s home directory is
/Users/nelle. - No: this command goes up two levels, i.e. ends in
/Users. - Yes:
~stands for the user’s home directory, in this case/Users/nelle. - No: this command would navigate into a directory
homein the current directory if it exists. - Yes: unnecessarily complicated, but correct.
- Yes: shortcut to go back to the user’s home directory.
- Yes: goes up one level.
Relative Path Resolution
Using the filesystem diagram below, if pwd displays
/Users/thing, what will ls -F ../backup
display?
../backup: No such file or directory2012-12-01 2013-01-08 2013-01-272012-12-01/ 2013-01-08/ 2013-01-27/original/ pnas_final/ pnas_sub/

- No: there is a directory
backupin/Users. - No: this is the content of
Users/thing/backup, but with.., we asked for one level further up. - No: see previous explanation.
- Yes:
../backup/refers to/Users/backup/.
ls Reading Comprehension
Using the filesystem diagram below, if pwd displays
/Users/backup, and -r tells ls to
display things in reverse order, what command(s) will result in the
following output:
OUTPUT
pnas_sub/ pnas_final/ original/ls pwdls -r -Fls -r -F /Users/backup
- No:
pwdis not the name of a directory. - Yes:
lswithout directory argument lists files and directories in the current directory. - Yes: uses the absolute path explicitly.
General Syntax of a Shell Command
We have now encountered commands, options, and arguments, but it is perhaps useful to formalise some terminology.
Consider the command below as a general example of a command, which we will dissect into its component parts:

ls is the command, with an
option -F and an argument
/. We’ve already encountered options which either start
with a single dash (-), known as short
options, or two dashes (--), known as long
options. [Options] change the behavior of a command and Arguments
tell the command what to operate on (e.g. files and directories).
Sometimes options and arguments are referred to as
parameters. A command can be called with more than one
option and more than one argument, but a command doesn’t always require
an argument or an option.
You might sometimes see options being referred to as switches or flags, especially for options that take no argument. In this lesson we will stick with using the term option.
Each part is separated by spaces. If you omit the space between
ls and -F the shell will look for a command
called ls-F, which doesn’t exist. Also, capitalization can
be important. For example, ls -s will display the size of
files and directories alongside the names, while ls -S will
sort the files and directories by size, as shown below:
OUTPUT
total 28
4 animal-counts 4 creatures 12 numbers.txt 4 alkanes 4 writingNote that the sizes returned by ls -s are in
blocks. As these are defined differently for different
operating systems, you may not obtain the same figures as in the
example.
OUTPUT
animal-counts creatures alkanes writing numbers.txtPutting all that together, our command ls -F / above
gives us a listing of files and directories in the root directory
/. An example of the output you might get from the above
command is given below:
OUTPUT
Applications/ System/
Library/ Users/
Network/ Volumes/When to use short or long options
When options exist as both short and long options:
- Use the short option when typing commands directly into the shell to minimize keystrokes and get your task done faster.
- Use the long option in scripts to provide clarity. It will be read many times and typed once.
Nelle’s Pipeline: Organizing Files
Knowing this much about files and directories, Nelle is ready to organize the files that the protein assay machine will create.
She creates a directory called north-pacific-gyre (to
remind herself where the data came from), which will contain the data
files from the assay machine and her data processing scripts.
Each of her physical samples is labelled according to her lab’s
convention with a unique ten-character ID, such as ‘NENE01729A’. This ID
is what she used in her collection log to record the location, time,
depth, and other characteristics of the sample, so she decides to use it
within the filename of each data file. Since the output of the assay
machine is plain text, she will call her files
NENE01729A.txt, NENE01812A.txt, and so on. All
1520 files will go into the same directory.
Now in her current directory shell-lesson-data, Nelle
can see what files she has using the command:
This command is a lot to type, but she can let the shell do most of the work through what is called tab completion. If she types:
and then presses Tab (the tab key on her keyboard), the shell automatically completes the directory name for her:
Pressing Tab again does nothing, since there are multiple possibilities; pressing Tab twice brings up a list of all the files.
If Nelle then presses G and then presses Tab again, the shell will append ‘goo’ since all files that start with ‘g’ share the first three characters ‘goo’.
To see all of those files, she can press Tab twice more.
This is called tab completion, and we will see it in many other tools as we go on.
Key Points
- The file system is responsible for managing information on the disk.
- Information is stored in files, which are stored in directories (folders).
- Directories can also store other directories, which then form a directory tree.
-
pwdprints the user’s current working directory. -
ls [path]prints a listing of a specific file or directory;lson its own lists the current working directory. -
cd [path]changes the current working directory. - Most commands take options that begin with a single
-. - Directory names in a path are separated with
/on Unix, but\on Windows. -
/on its own is the root directory of the whole file system. - An absolute path specifies a location from the root of the file system.
- A relative path specifies a location starting from the current location.
-
.on its own means ‘the current directory’;..means ‘the directory above the current one’.
Content from Working With Files and Directories
Last updated on 2023-10-10 | Edit this page
Overview
Questions
- How can I create, copy, and delete files and directories?
- How can I edit files?
Objectives
- Create a directory hierarchy that matches a given diagram.
- Create files in that hierarchy using an editor or by copying and renaming existing files.
- Delete, copy and move specified files and/or directories.
Creating directories
We now know how to explore files and directories, but how do we create them in the first place?
In this episode we will learn about creating and moving files and
directories, using the exercise-data/writing directory as
an example.
Step one: see where we are and what we already have
We should still be in the shell-lesson-data directory on
the Desktop, which we can check using:
OUTPUT
/Users/nelle/Desktop/shell-lesson-dataNext we’ll move to the exercise-data/writing directory
and see what it contains:
OUTPUT
haiku.txt LittleWomen.txtCreate a directory
Let’s create a new directory called thesis using the
command mkdir thesis (which has no output):
As you might guess from its name, mkdir means ‘make
directory’. Since thesis is a relative path (i.e., does not
have a leading slash, like /what/ever/thesis), the new
directory is created in the current working directory:
OUTPUT
haiku.txt LittleWomen.txt thesis/Since we’ve just created the thesis directory, there’s
nothing in it yet:
Note that mkdir is not limited to creating single
directories one at a time. The -p option allows
mkdir to create a directory with nested subdirectories in a
single operation:
The -R option to the ls command will list
all nested subdirectories within a directory. Let’s use
ls -FR to recursively list the new directory hierarchy we
just created in the project directory:
OUTPUT
../project/:
data/ results/
../project/data:
../project/results:Two ways of doing the same thing
Using the shell to create a directory is no different than using a
file explorer. If you open the current directory using your operating
system’s graphical file explorer, the thesis directory will
appear there too. While the shell and the file explorer are two
different ways of interacting with the files, the files and directories
themselves are the same.
Good names for files and directories
Complicated names of files and directories can make your life painful when working on the command line. Here we provide a few useful tips for the names of your files and directories.
- Don’t use spaces.
Spaces can make a name more meaningful, but since spaces are used to
separate arguments on the command line it is better to avoid them in
names of files and directories. You can use - or
_ instead (e.g. north-pacific-gyre/ rather
than north pacific gyre/). To test this out, try typing
mkdir north pacific gyre and see what directory (or
directories!) are made when you check with ls -F.
- Don’t begin the name with
-(dash).
Commands treat names starting with - as options.
- Stick with letters, numbers,
.(period or ‘full stop’),-(dash) and_(underscore).
Many other characters have special meanings on the command line. We will learn about some of these during this lesson. There are special characters that can cause your command to not work as expected and can even result in data loss.
If you need to refer to names of files or directories that have
spaces or other special characters, you should surround the name in
quotes ("").
Create a text file
Let’s change our working directory to thesis using
cd, then run a text editor called Nano to create a file
called draft.txt:
Which Editor?
When we say, ‘nano is a text editor’ we really do mean
‘text’. It can only work with plain character data, not tables, images,
or any other human-friendly media. We use it in examples because it is
one of the least complex text editors. However, because of this trait,
it may not be powerful enough or flexible enough for the work you need
to do after this workshop. On Unix systems (such as Linux and macOS),
many programmers use Emacs or Vim (both of which require more time to
learn), or a graphical editor such as Gedit or VScode. On Windows, you may
wish to use Notepad++.
Windows also has a built-in editor called notepad that can
be run from the command line in the same way as nano for
the purposes of this lesson.
No matter what editor you use, you will need to know where it searches for and saves files. If you start it from the shell, it will (probably) use your current working directory as its default location. If you use your computer’s start menu, it may want to save files in your Desktop or Documents directory instead. You can change this by navigating to another directory the first time you ‘Save As…’
Let’s type in a few lines of text.
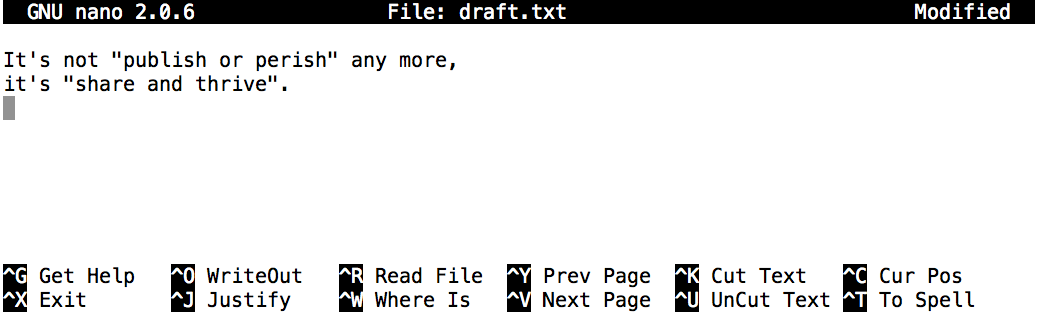
Once we’re happy with our text, we can press
Ctrl+O (press the Ctrl or
Control key and, while holding it down, press the
O key) to write our data to disk. We will be asked to provide
a name for the file that will contain our text. Press Return
to accept the suggested default of draft.txt.
Once our file is saved, we can use Ctrl+X to quit the editor and return to the shell.
Control, Ctrl, or ^ Key
The Control key is also called the ‘Ctrl’ key. There are various ways in which using the Control key may be described. For example, you may see an instruction to press the Control key and, while holding it down, press the X key, described as any of:
Control-XControl+XCtrl-XCtrl+X^XC-x
In nano, along the bottom of the screen you’ll see
^G Get Help ^O WriteOut. This means that you can use
Control-G to get help and Control-O to save
your file.
nano doesn’t leave any output on the screen after it
exits, but ls now shows that we have created a file called
draft.txt:
OUTPUT
draft.txtCreating Files a Different Way
We have seen how to create text files using the nano
editor. Now, try the following command:
What did the
touchcommand do? When you look at your current directory using the GUI file explorer, does the file show up?Use
ls -lto inspect the files. How large ismy_file.txt?When might you want to create a file this way?
The
touchcommand generates a new file calledmy_file.txtin your current directory. You can observe this newly generated file by typinglsat the command line prompt.my_file.txtcan also be viewed in your GUI file explorer.When you inspect the file with
ls -l, note that the size ofmy_file.txtis 0 bytes. In other words, it contains no data. If you openmy_file.txtusing your text editor it is blank.Some programs do not generate output files themselves, but instead require that empty files have already been generated. When the program is run, it searches for an existing file to populate with its output. The touch command allows you to efficiently generate a blank text file to be used by such programs.
What’s In A Name?
You may have noticed that all of Nelle’s files are named ‘something
dot something’, and in this part of the lesson, we always used the
extension .txt. This is just a convention; we can call a
file mythesis or almost anything else we want. However,
most people use two-part names most of the time to help them (and their
programs) tell different kinds of files apart. The second part of such a
name is called the filename extension and indicates
what type of data the file holds: .txt signals a plain text
file, .pdf indicates a PDF document, .cfg is a
configuration file full of parameters for some program or other,
.png is a PNG image, and so on.
This is just a convention, albeit an important one. Files merely contain bytes; it’s up to us and our programs to interpret those bytes according to the rules for plain text files, PDF documents, configuration files, images, and so on.
Naming a PNG image of a whale as whale.mp3 doesn’t
somehow magically turn it into a recording of whale song, though it
might cause the operating system to associate the file with a
music player program. In this case, if someone double-clicked
whale.mp3 in a file explorer program,the music player will
automatically (and erroneously) attempt to open the
whale.mp3 file.
Moving files and directories
Returning to the shell-lesson-data/exercise-data/writing
directory,
In our thesis directory we have a file
draft.txt which isn’t a particularly informative name, so
let’s change the file’s name using mv, which is short for
‘move’:
The first argument tells mv what we’re ‘moving’, while
the second is where it’s to go. In this case, we’re moving
thesis/draft.txt to thesis/quotes.txt, which
has the same effect as renaming the file. Sure enough, ls
shows us that thesis now contains one file called
quotes.txt:
OUTPUT
quotes.txtOne must be careful when specifying the target file name, since
mv will silently overwrite any existing file with the same
name, which could lead to data loss. By default, mv will
not ask for confirmation before overwriting files. However, an
additional option, mv -i (or
mv --interactive), will cause mv to request
such confirmation.
Note that mv also works on directories.
Let’s move quotes.txt into the current working
directory. We use mv once again, but this time we’ll use
just the name of a directory as the second argument to tell
mv that we want to keep the filename but put the file
somewhere new. (This is why the command is called ‘move’.) In this case,
the directory name we use is the special directory name .
that we mentioned earlier.
The effect is to move the file from the directory it was in to the
current working directory. ls now shows us that
thesis is empty:
OUTPUT
$Alternatively, we can confirm the file quotes.txt is no
longer present in the thesis directory by explicitly trying
to list it:
ERROR
ls: cannot access 'thesis/quotes.txt': No such file or directoryls with a filename or directory as an argument only
lists the requested file or directory. If the file given as the argument
doesn’t exist, the shell returns an error as we saw above. We can use
this to see that quotes.txt is now present in our current
directory:
OUTPUT
quotes.txtMoving Files to a new folder
After running the following commands, Jamie realizes that she put the
files sucrose.dat and maltose.dat into the
wrong folder. The files should have been placed in the raw
folder.
BASH
$ ls -F
analyzed/ raw/
$ ls -F analyzed
fructose.dat glucose.dat maltose.dat sucrose.dat
$ cd analyzedFill in the blanks to move these files to the raw/
folder (i.e. the one she forgot to put them in)
Copying files and directories
The cp command works very much like mv,
except it copies a file instead of moving it. We can check that it did
the right thing using ls with two paths as arguments — like
most Unix commands, ls can be given multiple paths at
once:
OUTPUT
quotes.txt thesis/quotations.txtWe can also copy a directory and all its contents by using the recursive option
-r, e.g. to back up a directory:
We can check the result by listing the contents of both the
thesis and thesis_backup directory:
OUTPUT
thesis:
quotations.txt
thesis_backup:
quotations.txtIt is important to include the -r flag. If you want to
copy a directory and you omit this option you will see a message that
the directory has been omitted because
-r not specified.
Renaming Files
Suppose that you created a plain-text file in your current directory
to contain a list of the statistical tests you will need to do to
analyze your data, and named it statstics.txt
After creating and saving this file you realize you misspelled the filename! You want to correct the mistake, which of the following commands could you use to do so?
cp statstics.txt statistics.txtmv statstics.txt statistics.txtmv statstics.txt .cp statstics.txt .
- No. While this would create a file with the correct name, the incorrectly named file still exists in the directory and would need to be deleted.
- Yes, this would work to rename the file.
- No, the period(.) indicates where to move the file, but does not provide a new file name; identical file names cannot be created.
- No, the period(.) indicates where to copy the file, but does not provide a new file name; identical file names cannot be created.
Moving and Copying
What is the output of the closing ls command in the
sequence shown below?
OUTPUT
/Users/jamie/dataOUTPUT
proteins.datBASH
$ mkdir recombined
$ mv proteins.dat recombined/
$ cp recombined/proteins.dat ../proteins-saved.dat
$ lsproteins-saved.dat recombinedrecombinedproteins.dat recombinedproteins-saved.dat
We start in the /Users/jamie/data directory, and create
a new folder called recombined. The second line moves
(mv) the file proteins.dat to the new folder
(recombined). The third line makes a copy of the file we
just moved. The tricky part here is where the file was copied to. Recall
that .. means ‘go up a level’, so the copied file is now in
/Users/jamie. Notice that .. is interpreted
with respect to the current working directory, not with
respect to the location of the file being copied. So, the only thing
that will show using ls (in /Users/jamie/data) is the
recombined folder.
- No, see explanation above.
proteins-saved.datis located at/Users/jamie - Yes
- No, see explanation above.
proteins.datis located at/Users/jamie/data/recombined - No, see explanation above.
proteins-saved.datis located at/Users/jamie
Removing files and directories
Returning to the shell-lesson-data/exercise-data/writing
directory, let’s tidy up this directory by removing the
quotes.txt file we created. The Unix command we’ll use for
this is rm (short for ‘remove’):
We can confirm the file has gone using ls:
ERROR
ls: cannot access 'quotes.txt': No such file or directoryDeleting Is Forever
The Unix shell doesn’t have a trash bin that we can recover deleted files from (though most graphical interfaces to Unix do). Instead, when we delete files, they are unlinked from the file system so that their storage space on disk can be recycled. Tools for finding and recovering deleted files do exist, but there’s no guarantee they’ll work in any particular situation, since the computer may recycle the file’s disk space right away.
Using rm Safely
What happens when we execute
rm -i thesis_backup/quotations.txt? Why would we want this
protection when using rm?
OUTPUT
rm: remove regular file 'thesis_backup/quotations.txt'? yThe -i option will prompt before (every) removal (use
Y to confirm deletion or N to keep the file). The
Unix shell doesn’t have a trash bin, so all the files removed will
disappear forever. By using the -i option, we have the
chance to check that we are deleting only the files that we want to
remove.
If we try to remove the thesis directory using
rm thesis, we get an error message:
ERROR
rm: cannot remove 'thesis': Is a directoryThis happens because rm by default only works on files,
not directories.
rm can remove a directory and all its contents
if we use the recursive option -r, and it will do so
without any confirmation prompts:
Given that there is no way to retrieve files deleted using the shell,
rm -r should be used with great caution (you might
consider adding the interactive option rm -r -i).
Operations with multiple files and directories
Oftentimes one needs to copy or move several files at once. This can be done by providing a list of individual filenames, or specifying a naming pattern using wildcards. Wildcards are special characters that can be used to represent unknown characters or sets of characters when navigating the Unix file system.
Copy with Multiple Filenames
For this exercise, you can test the commands in the
shell-lesson-data/exercise-data directory.
In the example below, what does cp do when given several
filenames and a directory name?
In the example below, what does cp do when given three
or more file names?
OUTPUT
basilisk.dat minotaur.dat unicorn.datIf given more than one file name followed by a directory name
(i.e. the destination directory must be the last argument),
cp copies the files to the named directory.
If given three file names, cp throws an error such as
the one below, because it is expecting a directory name as the last
argument.
ERROR
cp: target 'basilisk.dat' is not a directoryUsing wildcards for accessing multiple files at once
Wildcards
* is a wildcard, which represents zero
or more other characters. Let’s consider the
shell-lesson-data/exercise-data/alkanes directory:
*.pdb represents ethane.pdb,
propane.pdb, and every file that ends with ‘.pdb’. On the
other hand, p*.pdb only represents pentane.pdb
and propane.pdb, because the ‘p’ at the front can only
represent filenames that begin with the letter ‘p’.
? is also a wildcard, but it represents exactly one
character. So ?ethane.pdb could represent
methane.pdb whereas *ethane.pdb represents
both ethane.pdb and methane.pdb.
Wildcards can be used in combination with each other. For example,
???ane.pdb indicates three characters followed by
ane.pdb, giving
cubane.pdb ethane.pdb octane.pdb.
When the shell sees a wildcard, it expands the wildcard to create a
list of matching filenames before running the preceding
command. As an exception, if a wildcard expression does not match any
file, Bash will pass the expression as an argument to the command as it
is. For example, typing ls *.pdf in the
alkanes directory (which contains only files with names
ending with .pdb) results in an error message that there is
no file called *.pdf. However, generally commands like
wc and ls see the lists of file names matching
these expressions, but not the wildcards themselves. It is the shell,
not the other programs, that expands the wildcards.
List filenames matching a pattern
When run in the alkanes directory, which ls
command(s) will produce this output?
ethane.pdb methane.pdb
ls *t*ane.pdbls *t?ne.*ls *t??ne.pdbls ethane.*
The solution is 3.
1. shows all files whose names contain zero or more
characters (*) followed by the letter t, then
zero or more characters (*) followed by
ane.pdb. This gives
ethane.pdb methane.pdb octane.pdb pentane.pdb.
2. shows all files whose names start with zero or more
characters (*) followed by the letter t, then
a single character (?), then ne. followed by
zero or more characters (*). This will give us
octane.pdb and pentane.pdb but doesn’t match
anything which ends in thane.pdb.
3. fixes the problems of option 2 by matching two
characters (??) between t and ne.
This is the solution.
4. only shows files starting with
ethane..
More on Wildcards
Sam has a directory containing calibration data, datasets, and descriptions of the datasets:
BASH
.
├── 2015-10-23-calibration.txt
├── 2015-10-23-dataset1.txt
├── 2015-10-23-dataset2.txt
├── 2015-10-23-dataset_overview.txt
├── 2015-10-26-calibration.txt
├── 2015-10-26-dataset1.txt
├── 2015-10-26-dataset2.txt
├── 2015-10-26-dataset_overview.txt
├── 2015-11-23-calibration.txt
├── 2015-11-23-dataset1.txt
├── 2015-11-23-dataset2.txt
├── 2015-11-23-dataset_overview.txt
├── backup
│ ├── calibration
│ └── datasets
└── send_to_bob
├── all_datasets_created_on_a_23rd
└── all_november_filesBefore heading off to another field trip, she wants to back up her data and send some datasets to her colleague Bob. Sam uses the following commands to get the job done:
BASH
$ cp *dataset* backup/datasets
$ cp ____calibration____ backup/calibration
$ cp 2015-____-____ send_to_bob/all_november_files/
$ cp ____ send_to_bob/all_datasets_created_on_a_23rd/Help Sam by filling in the blanks.
The resulting directory structure should look like this
BASH
.
├── 2015-10-23-calibration.txt
├── 2015-10-23-dataset1.txt
├── 2015-10-23-dataset2.txt
├── 2015-10-23-dataset_overview.txt
├── 2015-10-26-calibration.txt
├── 2015-10-26-dataset1.txt
├── 2015-10-26-dataset2.txt
├── 2015-10-26-dataset_overview.txt
├── 2015-11-23-calibration.txt
├── 2015-11-23-dataset1.txt
├── 2015-11-23-dataset2.txt
├── 2015-11-23-dataset_overview.txt
├── backup
│ ├── calibration
│ │ ├── 2015-10-23-calibration.txt
│ │ ├── 2015-10-26-calibration.txt
│ │ └── 2015-11-23-calibration.txt
│ └── datasets
│ ├── 2015-10-23-dataset1.txt
│ ├── 2015-10-23-dataset2.txt
│ ├── 2015-10-23-dataset_overview.txt
│ ├── 2015-10-26-dataset1.txt
│ ├── 2015-10-26-dataset2.txt
│ ├── 2015-10-26-dataset_overview.txt
│ ├── 2015-11-23-dataset1.txt
│ ├── 2015-11-23-dataset2.txt
│ └── 2015-11-23-dataset_overview.txt
└── send_to_bob
├── all_datasets_created_on_a_23rd
│ ├── 2015-10-23-dataset1.txt
│ ├── 2015-10-23-dataset2.txt
│ ├── 2015-10-23-dataset_overview.txt
│ ├── 2015-11-23-dataset1.txt
│ ├── 2015-11-23-dataset2.txt
│ └── 2015-11-23-dataset_overview.txt
└── all_november_files
├── 2015-11-23-calibration.txt
├── 2015-11-23-dataset1.txt
├── 2015-11-23-dataset2.txt
└── 2015-11-23-dataset_overview.txtOrganizing Directories and Files
Jamie is working on a project, and she sees that her files aren’t very well organized:
OUTPUT
analyzed/ fructose.dat raw/ sucrose.datThe fructose.dat and sucrose.dat files
contain output from her data analysis. What command(s) covered in this
lesson does she need to run so that the commands below will produce the
output shown?
OUTPUT
analyzed/ raw/OUTPUT
fructose.dat sucrose.datReproduce a folder structure
You’re starting a new experiment and would like to duplicate the directory structure from your previous experiment so you can add new data.
Assume that the previous experiment is in a folder called
2016-05-18, which contains a data folder that
in turn contains folders named raw and
processed that contain data files. The goal is to copy the
folder structure of the 2016-05-18 folder into a folder
called 2016-05-20 so that your final directory structure
looks like this:
OUTPUT
2016-05-20/
└── data
├── processed
└── rawWhich of the following set of commands would achieve this objective? What would the other commands do?
The first two sets of commands achieve this objective. The first set uses relative paths to create the top-level directory before the subdirectories.
The third set of commands will give an error because the default
behavior of mkdir won’t create a subdirectory of a
non-existent directory: the intermediate level folders must be created
first.
The fourth set of commands achieve this objective. Remember, the
-p option, followed by a path of one or more directories,
will cause mkdir to create any intermediate subdirectories
as required.
The final set of commands generates the ‘raw’ and ‘processed’ directories at the same level as the ‘data’ directory.
Key Points
-
cp [old] [new]copies a file. -
mkdir [path]creates a new directory. -
mv [old] [new]moves (renames) a file or directory. -
rm [path]removes (deletes) a file. -
*matches zero or more characters in a filename, so*.txtmatches all files ending in.txt. -
?matches any single character in a filename, so?.txtmatchesa.txtbut notany.txt. - Use of the Control key may be described in many ways, including
Ctrl-X,Control-X, and^X. - The shell does not have a trash bin: once something is deleted, it’s really gone.
- Most files’ names are
something.extension. The extension isn’t required, and doesn’t guarantee anything, but is normally used to indicate the type of data in the file. - Depending on the type of work you do, you may need a more powerful text editor than Nano.
Content from Setting Up Git
Last updated on 2023-10-19 | Edit this page
Overview
Questions
- How do I get set up to use Git?
Objectives
- Configure
gitthe first time it is used on a computer. - Understand the meaning of the
--globalconfiguration flag.
When we use Git on a new computer for the first time, we need to configure a few things. Below are a few examples of configurations we will set as we get started with Git:
- our name and email address,
- what our preferred text editor is,
- and that we want to use these settings globally (i.e. for every project).
On a command line, Git commands are written as
git verb options, where verb is what we
actually want to do and options is additional optional
information which may be needed for the verb.
This user name and email will be associated with your subsequent Git activity, which means that any changes pushed to GitHub, BitBucket, GitLab or another Git host server after this lesson will include this information.
For this lesson, we will be interacting with GitHub and so the email address used should be the same as the one used when setting up your GitHub account. If you are concerned about privacy, please review GitHub’s instructions for keeping your email address private.
Keeping your email private
If you elect to use a private email address with GitHub, then use
that same email address for the user.email value,
e.g. username@users.noreply.github.com replacing
username with your GitHub one.
Line Endings
As with other keys, when you hit Enter or ↵ or on Macs, Return on your keyboard, your computer encodes this input as a character. Different operating systems use different character(s) to represent the end of a line. (You may also hear these referred to as newlines or line breaks.) Because Git uses these characters to compare files, it may cause unexpected issues when editing a file on different machines. Though it is beyond the scope of this lesson, you can read more about this issue in the Pro Git book.
You can change the way Git recognizes and encodes line endings using
the core.autocrlf command to git config. The
following settings are recommended:
On macOS and Linux:
And on Windows:
Set the default text editor:
| Editor | Configuration command |
|---|---|
| Atom | $ git config --global core.editor "atom --wait" |
| nano | $ git config --global core.editor "nano -w" |
| BBEdit (Mac, with command line tools) | $ git config --global core.editor "bbedit -w" |
| Sublime Text (Mac) | $ git config --global core.editor "/Applications/Sublime\ Text.app/Contents/SharedSupport/bin/subl -n -w" |
| Sublime Text (Win, 32-bit install) | $ git config --global core.editor "'c:/program files (x86)/sublime text 3/sublime_text.exe' -w" |
| Sublime Text (Win, 64-bit install) | $ git config --global core.editor "'c:/program files/sublime text 3/sublime_text.exe' -w" |
| Notepad (Win) | $ git config --global core.editor "c:/Windows/System32/notepad.exe" |
| Notepad++ (Win, 32-bit install) | $ git config --global core.editor "'c:/program files (x86)/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Notepad++ (Win, 64-bit install) | $ git config --global core.editor "'c:/program files/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Kate (Linux) | $ git config --global core.editor "kate" |
| Gedit (Linux) | $ git config --global core.editor "gedit --wait --new-window" |
| Scratch (Linux) | $ git config --global core.editor "scratch-text-editor" |
| Emacs | $ git config --global core.editor "emacs" |
| Vim | $ git config --global core.editor "vim" |
| VS Code | $ git config --global core.editor "code --wait" |
It is possible to reconfigure the text editor for Git whenever you want to change it.
Exiting Vim
Note that Vim is the default editor for many programs. If you haven’t
used Vim before and wish to exit a session without saving your changes,
press Esc then type :q! and hit Enter
or ↵ or on Macs, Return. If you want to save your
changes and quit, press Esc then type :wq and
hit Enter or ↵ or on Macs, Return.
Git (2.28+) allows configuration of the name of the branch created when you initialize any new repository.
Default Git branch naming
Source file changes are associated with a “branch.” For new learners
in this lesson, it’s enough to know that branches exist, and this lesson
uses one branch.
By default, Git will create a branch called master when you
create a new repository with git init (as explained in the
next Episode). This term evokes the racist practice of human slavery and
the software development
community has moved to adopt more inclusive language.
In 2020, most Git code hosting services transitioned to using
main as the default branch. As an example, any new
repository that is opened in GitHub and GitLab default to
main. However, Git has not yet made the same change. As a
result, local repositories must be manually configured have the same
main branch name as most cloud services.
For versions of Git prior to 2.28, the change can be made on an
individual repository level. The command for this is in the next
episode. Note that if this value is unset in your local Git
configuration, the init.defaultBranch value defaults to
master.
The five commands we just ran above only need to be run once: the
flag --global tells Git to use the settings for every
project, in your user account, on this computer.
Let’s review those settings and test our core.editor
right away:
Let’s close the file without making any additional changes. Remember, since typos in the config file will cause issues, it’s safer to view the configuration with:
And if necessary, change your configuration using the same commands to choose another editor or update your email address. This can be done as many times as you want.
Proxy
In some networks you need to use a proxy. If this is the case, you may also need to tell Git about the proxy:
To disable the proxy, use
Git Help and Manual
Always remember that if you forget the subcommands or options of a
git command, you can access the relevant list of options
typing git <command> -h or access the corresponding
Git manual by typing git <command> --help, e.g.:
While viewing the manual, remember the : is a prompt
waiting for commands and you can press Q to exit the
manual.
More generally, you can get the list of available git
commands and further resources of the Git manual typing:
Key Points
- Use
git configwith the--globaloption to configure a user name, email address, editor, and other preferences once per machine.
Content from Creating a Repository
Last updated on 2023-10-19 | Edit this page
Overview
Questions
- Where does Git store information?
Objectives
- Create a local Git repository.
- Describe the purpose of the
.gitdirectory.
Once Git is configured, we can start using it. Let’s imagine we want to create a simple web page about our work. We can track revisions to the page using git and, later, publish it using GitHub pages.
First, let’s create a new directory in the Desktop
folder for our work and then change the current working directory to the
newly created one:
Then we tell Git to make simple-site a repository -- a place where Git can
store versions of our files:
It is important to note that git init will create a
repository that can include subdirectories and their files—there is no
need to create separate repositories nested within the
simple-site repository, whether subdirectories are present
from the beginning or added later. Also, note that the creation of the
simple-site directory and its initialization as a
repository are completely separate processes.
If we use ls to show the directory’s contents, it
appears that nothing has changed:
But if we add the -a flag to show everything, we can see
that Git has created a hidden directory within simple-site
called .git:
OUTPUT
. .. .gitGit uses this special subdirectory to store all the information about
the project, including the tracked files and sub-directories located
within the project’s directory. If we ever delete the .git
subdirectory, we will lose the project’s history.
Next, we will change the default branch to be called
main. This might be the default branch depending on your
settings and version of git. See the setup episode for
more information on this change.
OUTPUT
Switched to a new branch 'main'We can check that everything is set up correctly by asking Git to tell us the status of our project:
OUTPUT
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)If you are using a different version of git, the exact
wording of the output might be slightly different.
Places to Create Git Repositories
Imagine you create a directory for your website images:
BASH
$ cd ~/Desktop # return to Desktop directory
$ cd simple-site # go into simple-site directory, which is already a Git repository
$ ls -a # ensure the .git subdirectory is still present in the simple-site directory
$ mkdir images # make a subdirectory simple-site/images
$ cd images # go into images subdirectory
$ git init # make the images subdirectory a Git repository
$ ls -a # ensure the .git subdirectory is present indicating we have created a new Git repositoryIs the git init command, run inside the
images subdirectory, required for tracking files stored in
the images subdirectory?
You don’t need to make the images subdirectory a Git
repository because the simple-site repository can track any
files, sub-directories, and subdirectory files under the
simple-site directory.
Additionally, Git repositories can interfere with each other if they
are “nested”: the outer repository will try to version-control the inner
repository. Therefore, it’s best to create each new Git repository in a
separate directory. To be sure that there is no conflicting repository
in the directory, check the output of git status. If it
looks like the following, you are good to go to create a new repository
as shown above:
OUTPUT
fatal: Not a git repository (or any of the parent directories): .gitCorrecting git init Mistakes
Can you undo the last git init in the
images subdirectory?
Background
Removing files from a Git repository needs to be done with caution. But we have not learned yet how to tell Git to track a particular file; we will learn this in the next episode. Files that are not tracked by Git can easily be removed like any other “ordinary” files with
Similarly a directory can be removed using rm -r dirname
or rm -rf dirname. If the files or folder being removed in
this fashion are tracked by Git, then their removal becomes another
change that we will need to track, as we will see in the next
episode.
Solution
Git keeps all of its files in the .git directory. To
recover from this little mistake, you can just remove the
.git folder in the images subdirectory by running the
following command from inside the simple-site
directory:
But be careful! Running this command in the wrong directory will
remove the entire Git history of a project you might want to keep.
Therefore, always check your current directory using the command
pwd.
Key Points
-
git initinitializes a repository. - Git stores all of its repository data in the
.gitdirectory.
Content from Tracking Changes
Last updated on 2023-10-19 | Edit this page
Overview
Questions
- How do I record changes in Git?
- How do I check the status of my version control repository?
- How do I record notes about what changes I made and why?
Objectives
- Go through the modify-add-commit cycle for one or more files.
- Explain where information is stored at each stage of that cycle.
- Distinguish between descriptive and non-descriptive commit messages.
First let’s make sure we’re still in the right directory. You should
be in the simple-site directory.
Let’s create a text file called index.md and add it to
our repository. The file will later be converted into a webpage by
GitHub pages. We’ll write the file using a syntax called Markdown, which
is why we use the .md extensions.
Markdown
Markdown is a language
used to simplify writing HTML. Plain text characters like #
and * are used in place of HTML tags. These characters are
then processed (by GitHub pages) and transformed into HTML tags. As the
name Markdown suggests, the language has been trimmed down to a minimum.
The most frequently used elements, like headings, paragraphs, lists,
tables and basic text formatting (i.e. bold, italic) are part of
Markdown. Markdown’s simplified syntax keeps content human-readable.
We’ll use nano to edit the file; you can use whatever
editor you like. In particular, this does not have to be the
core.editor you set globally earlier. But remember, the
bash command to create or edit a new file will depend on the editor you
choose (it might not be nano). For a refresher on text
editors, check out “Which
Editor?” in The Unix Shell
lesson.
Type the text below into the index.md file:
OUTPUT
I am a ___ at UCSBLet’s first verify that the file was properly created by running the
list command (ls):
OUTPUT
index.mdindex.md contains a single line, which we can see by
running:
OUTPUT
I am a ___ at UCSBIf we check the status of our project again, Git tells us that it’s noticed the new file:
OUTPUT
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
index.md
nothing added to commit but untracked files present (use "git add" to track)The “untracked files” message means that there’s a file in the
directory that Git isn’t keeping track of. We can tell Git to track a
file using git add:
and then check that the right thing happened:
OUTPUT
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: index.md
Git now knows that it’s supposed to keep track of
index.md, but it hasn’t recorded these changes as a commit
yet. To get it to do that, we need to run one more command:
OUTPUT
[main (root-commit) f22b25e] Start new webpage
1 file changed, 1 insertion(+)
create mode 100644 index.mdWhen we run git commit, Git takes everything we have
told it to save by using git add and stores a copy
permanently inside the special .git directory. This
permanent copy is called a commit
(or revision) and its short
identifier is f22b25e. Your commit may have another
identifier.
We use the -m flag (for “message”) to record a short,
descriptive, and specific comment that will help us remember later on
what we did and why. If we just run git commit without the
-m option, Git will launch nano (or whatever
other editor we configured as core.editor) so that we can
write a longer message.
Good commit
messages start with a brief (<50 characters) statement about the
changes made in the commit. Generally, the message should complete the
sentence “If applied, this commit will”
If we run git status now:
OUTPUT
On branch main
nothing to commit, working tree cleanit tells us everything is up to date. If we want to know what we’ve
done recently, we can ask Git to show us the project’s history using
git log:
OUTPUT
commit f22b25e3233b4645dabd0d81e651fe074bd8e73b
Author: ...
Date: Thu Aug 22 09:51:46 2013 -0400
Start new webpagegit log lists all commits made to a repository in
reverse chronological order. The listing for each commit includes the
commit’s full identifier (which starts with the same characters as the
short identifier printed by the git commit command
earlier), the commit’s author, when it was created, and the log message
Git was given when the commit was created.
Where Are My Changes?
If we run ls at this point, we will still see just one
file called index.md. That’s because Git saves information
about files’ history in the special .git directory
mentioned earlier so that our filesystem doesn’t become cluttered (and
so that we can’t accidentally edit or delete an old version).
Let’s adds more information to the file. (Again, we’ll edit with
nano and then cat the file to show its
contents; you may use a different editor, and don’t need to
cat.)
OUTPUT
# Your Name
I am a ___ at UCSBWhen we run git status now, it tells us that a file it
already knows about has been modified:
OUTPUT
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: index.md
no changes added to commit (use "git add" and/or "git commit -a")The last line is the key phrase: “no changes added to commit”. We
have changed this file, but we haven’t told Git we will want to save
those changes (which we do with git add) nor have we saved
them (which we do with git commit). So let’s do that now.
It is good practice to always review our changes before saving them. We
do this using git diff. This shows us the differences
between the current state of the file and the most recently saved
version:
OUTPUT
diff --git a/index.md b/index.md
index 7d781a7..bbb33fe 100644
--- a/index.md
+++ b/index.md
@@ -1 +1,3 @@
+# Your Name
+
I am a ___ at UCSBThe output is cryptic because it is actually a series of commands for
tools like editors and patch telling them how to
reconstruct one file given the other. If we break it down into
pieces:
- The first line tells us that Git is producing output similar to the
Unix
diffcommand comparing the old and new versions of the file. - The second line tells exactly which versions of the file Git is
comparing;
7d781a7andbbb33feare unique computer-generated labels for those versions. - The third and fourth lines once again show the name of the file being changed.
- The remaining lines are the most interesting, they show us the
actual differences and the lines on which they occur. In particular, the
+marker in the first column shows where we added a line.
After reviewing our change, it’s time to commit it:
OUTPUT
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: index.md
no changes added to commit (use "git add" and/or "git commit -a")Whoops: Git won’t commit because we didn’t use git add
first. Let’s fix that:
OUTPUT
[main 019f377] add header
1 file changed, 2 insertions(+)Git insists that we add files to the set we want to commit before actually committing anything. This allows us to commit our changes in stages and capture changes in logical portions rather than only large batches. For example, suppose we’re adding a few citations to relevant research to our thesis. We might want to commit those additions, and the corresponding bibliography entries, but not commit some of our work drafting the conclusion (which we haven’t finished yet).
To allow for this, Git has a special staging area where it keeps track of things that have been added to the current changeset but not yet committed.
Staging Area
If you think of Git as taking snapshots of changes over the life of a
project, git add specifies what will go in a
snapshot (putting things in the staging area), and
git commit then actually takes the snapshot, and
makes a permanent record of it (as a commit). If you don’t have anything
staged when you type git commit, Git will prompt you to use
git commit -a or git commit --all, which is
kind of like gathering everyone to take a group photo! However,
it’s almost always better to explicitly add things to the staging area,
because you might commit changes you forgot you made. (Going back to the
group photo simile, you might get an extra with incomplete makeup
walking on the stage for the picture because you used -a!)
Try to stage things manually, or you might find yourself searching for
“git undo commit” more than you would like!

Let’s watch as our changes to a file move from our editor to the staging area and into long-term storage. First, we’ll add another line to the file:
OUTPUT
# Your Name
I am a ___ at UCSB. My responsibilities include:
- Carpentry WorkshopsOUTPUT
diff --git a/index.md b/index.md
index bbb33fe..22a33eb 100644
--- a/index.md
+++ b/index.md
@@ -1,3 +1,5 @@
# Your Name
-I am a ___ at UCSB
+I am a ___ at UCSB. My responsibilities include:
+
+- Carpentry WorkshopsSo far, so good: we’ve added one line to the end of the file (shown
with a + in the first column). Now let’s put that change in
the staging area and see what git diff reports:
There is no output: as far as Git can tell, there’s no difference between what it’s been asked to save permanently and what’s currently in the directory. However, if we do this:
OUTPUT
diff --git a/index.md b/index.md
index bbb33fe..22a33eb 100644
--- a/index.md
+++ b/index.md
@@ -1,3 +1,5 @@
# Your Name
-I am a ___ at UCSB
+I am a ___ at UCSB. My responsibilities include:
+
+- Carpentry Workshopsit shows us the difference between the last committed change and what’s in the staging area. Let’s save our changes:
OUTPUT
[main d11d7e5] add responsibilities
1 file changed, 3 insertions(+), 1 deletion(-)check our status:
OUTPUT
On branch main
nothing to commit, working tree cleanand look at the history of what we’ve done so far:
OUTPUT
commit d11d7e52ab98d3d4c18cde4c4a0bbeea3fe40983 (HEAD -> main)
Author: ...
Date: Thu Oct 19 12:07:51 2023 -0400
add responsibilities
commit 019f37773f9f18b77f508990df65e56a34df45de
Author: ...
Date: Thu Oct 19 12:03:04 2023 -0400
add header
commit 8defaab26aa641a4233896ec68e603c541aa77b4
Author: ...
Date: Thu Oct 19 12:01:17 2023 -0400
add pageWord-based diffing
Sometimes, e.g. in the case of the text documents a line-wise diff is
too coarse. That is where the --color-words option of
git diff comes in very useful as it highlights the changed
words using colors.
Paging the Log
When the output of git log is too long to fit in your
screen, git uses a program to split it into pages of the
size of your screen. When this “pager” is called, you will notice that
the last line in your screen is a :, instead of your usual
prompt.
- To get out of the pager, press Q.
- To move to the next page, press Spacebar.
- To search for
some_wordin all pages, press / and typesome_word. Navigate through matches pressing N.
Limit Log Size
To avoid having git log cover your entire terminal
screen, you can limit the number of commits that Git lists by using
-N, where N is the number of commits that you
want to view. For example, if you only want information from the last
commit you can use:
OUTPUT
commit d11d7e52ab98d3d4c18cde4c4a0bbeea3fe40983 (HEAD -> main)
Author: ...
Date: Thu Oct 19 12:07:51 2023 -0400
add responsibilitiesYou can also reduce the quantity of information using the
--oneline option:
OUTPUT
d11d7e5 (HEAD -> main) add responsibilities
019f377 add header
8defaab add pageYou can also combine the --oneline option with others.
One useful combination adds --graph to display the commit
history as a text-based graph and to indicate which commits are
associated with the current HEAD, the current branch
main, or other
Git references:
OUTPUT
* d11d7e5 (HEAD -> main) add responsibilities
* 019f377 add header
* 8defaab add pageDirectories
Two important facts you should know about directories in Git.
- Git does not track directories on their own, only files within them. Try it for yourself:
Note, our newly created empty directory spaceships does
not appear in the list of untracked files even if we explicitly add it
(via git add) to our repository. This is the
reason why you will sometimes see .gitkeep files in
otherwise empty directories. Unlike .gitignore, these files
are not special and their sole purpose is to populate a directory so
that Git adds it to the repository. In fact, you can name such files
anything you like.
- If you create a directory in your Git repository and populate it with files, you can add all files in the directory at once by:
Try it for yourself:
BASH
$ touch spaceships/apollo-11 spaceships/sputnik-1
$ git status
$ git add spaceships
$ git statusBefore moving on, we will commit these changes.
To recap, when we want to add changes to our repository, we first
need to add the changed files to the staging area (git add)
and then commit the staged changes to the repository
(git commit):

Choosing a Commit Message
Which of the following commit messages would be most appropriate for
the last commit made to index.md?
- “Changes”
- “Added line ‘But the Mummy will appreciate the lack of humidity’ to index.md”
- “Discuss effects of Mars’ climate on the Mummy”
Answer 1 is not descriptive enough, and the purpose of the commit is unclear; and answer 2 is redundant to using “git diff” to see what changed in this commit; but answer 3 is good: short, descriptive, and imperative.
Committing Changes to Git
Which command(s) below would save the changes of
myfile.txt to my local Git repository?
- Would only create a commit if files have already been staged.
- Would try to create a new repository.
- Is correct: first add the file to the staging area, then commit.
- Would try to commit a file “my recent changes” with the message myfile.txt.
Committing Multiple Files
The staging area can hold changes from any number of files that you want to commit as a single snapshot.
- Add some text to
index.mdnoting your decision to consider Venus as a base - Create a new file
venus.txtwith your initial thoughts about Venus as a base for you and your friends - Add changes from both files to the staging area, and commit those changes.
The output below from cat index.md reflects only content
added during this exercise. Your output may vary.
First we make our changes to the index.md and
venus.txt files:
OUTPUT
Maybe I should start with a base on Venus.OUTPUT
Venus is a nice planet and I definitely should consider it as a base.Now you can add both files to the staging area. We can do that in one line:
Or with multiple commands:
Now the files are ready to commit. You can check that using
git status. If you are ready to commit use:
OUTPUT
[main cc127c2]
Write plans to start a base on Venus
2 files changed, 2 insertions(+)
create mode 100644 venus.txt
bio Repository
- Create a new Git repository on your computer called
bio. - Write a three-line biography for yourself in a file called
me.txt, commit your changes - Modify one line, add a fourth line
- Display the differences between its updated state and its original state.
If needed, move out of the simple-site folder:
Create a new folder called bio and ‘move’ into it:
Initialise git:
Create your biography file me.txt using
nano or another text editor. Once in place, add and commit
it to the repository:
Modify the file as described (modify one line, add a fourth line). To
display the differences between its updated state and its original
state, use git diff:
Key Points
-
git statusshows the status of a repository. - Files can be stored in a project’s working directory (which users see), the staging area (where the next commit is being built up) and the local repository (where commits are permanently recorded).
-
git addputs files in the staging area. -
git commitsaves the staged content as a new commit in the local repository. - Write a commit message that accurately describes your changes.
Content from Exploring History
Last updated on 2023-10-19 | Edit this page
Overview
Questions
- How can I identify old versions of files?
- How do I review my changes?
- How can I recover old versions of files?
Objectives
- Explain what the HEAD of a repository is and how to use it.
- Identify and use Git commit numbers.
- Compare various versions of tracked files.
- Restore old versions of files.
As we saw in the previous episode, we can refer to commits by their
identifiers. You can refer to the most recent commit of the
working directory by using the identifier HEAD.
We’ve been adding one line at a time to
`, so it's easy to track our progress by looking, so let's do that using ourHEADs. Before we start, let's make a change toindex.md`,
adding yet another line.
MD
# Your Name
I am a ___ at UCSB. My responsibilities include:
- Carpentry Workshops
- Teaching/Learning GitNow, let’s see what we get.
OUTPUT
diff --git a/index.md b/index.md
index 22a33eb..e96b16e 100644
--- a/index.md
+++ b/index.md
@@ -3,3 +3,4 @@
I am a ___ at UCSB. My responsibilities include:
- Carpentry Workshops
+- Teaching/Leaning Gitwhich is the same as what you would get if you leave out
HEAD (try it). The real goodness in all this is when you
can refer to previous commits. We do that by adding ~1
(where “~” is “tilde”, pronounced [til-duh])
to refer to the commit one before HEAD.
If we want to see the differences between older commits we can use
git diff again, but with the notation HEAD~1,
HEAD~2, and so on, to refer to them:
OUTPUT
diff --git a/index.md b/index.md
index 7d781a7..e96b16e 100644
--- a/index.md
+++ b/index.md
@@ -1 +1,6 @@
-I am a ___ at UCSB
+# Seth Erickson
+
+I am a ___ at UCSB. My responsibilities include:
+
+- Carpentry Workshops
+- Teaching/Leaning GitWe could also use git show which shows us what changes
we made at an older commit as well as the commit message, rather than
the differences between a commit and our working directory that
we see by using git diff.
OUTPUT
commit 8defaab26aa641a4233896ec68e603c541aa77b4
Author: ...
Date: Thu Oct 19 12:01:17 2023 -0400
add page
diff --git a/index.md b/index.md
new file mode 100644
index 0000000..7d781a7
--- /dev/null
+++ b/index.md
@@ -0,0 +1 @@
+I am a ___ at UCSBIn this way, we can build up a chain of commits. The most recent end
of the chain is referred to as HEAD; we can refer to
previous commits using the ~ notation, so
HEAD~1 means “the previous commit”, while
HEAD~123 goes back 123 commits from where we are now.
We can also refer to commits using those long strings of digits and
letters that git log displays. These are unique IDs for the
changes, and “unique” really does mean unique: every change to any set
of files on any computer has a unique 40-character identifier. Our first
commit was given the ID
8defaab26aa641a4233896ec68e603c541aa77b4, so let’s try
this:
OUTPUT
ddiff --git a/index.md b/index.md
index 7d781a7..e96b16e 100644
--- a/index.md
+++ b/index.md
@@ -1 +1,6 @@
-I am a ___ at UCSB
+# Seth Erickson
+
+I am a ___ at UCSB. My responsibilities include:
+
+- Carpentry Workshops
+- Teaching/Leaning GitThat’s the right answer, but typing out random 40-character strings is annoying, so Git lets us use just the first few characters (typically seven for normal size projects):
OUTPUT
diff --git a/index.md b/index.md
index 7d781a7..e96b16e 100644
--- a/index.md
+++ b/index.md
@@ -1 +1,6 @@
-I am a ___ at UCSB
+# Seth Erickson
+
+I am a ___ at UCSB. My responsibilities include:
+
+- Carpentry Workshops
+- Teaching/Leaning GitAll right! So we can save changes to files and see what we’ve
changed. Now, how can we restore older versions of things? Let’s suppose
we change our mind about the last update to index.md (the
“ill-considered change”).
git status now tells us that the file has been changed,
but those changes haven’t been staged:
OUTPUT
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: index.md
no changes added to commit (use "git add" and/or "git commit -a")We can put things back the way they were by using
git checkout:
OUTPUT
# Seth Erickson
I am a ___ at UCSB. My responsibilities include:
- Carpentry WorkshopsAs you might guess from its name, git checkout checks
out (i.e., restores) an old version of a file. In this case, we’re
telling Git that we want to recover the version of the file recorded in
HEAD, which is the last saved commit. If we want to go back
even further, we can use a commit identifier instead:
OUTPUT
I am a ___ at UCSBOUTPUT
On branch main
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: index.md
Notice that the changes are currently in the staging area. Again, we
can put things back the way they were by using
git checkout:
Don’t Lose Your HEAD
Above we used
to revert index.md to its state after the commit
f22b25e. But be careful! The command checkout
has other important functionalities and Git will misunderstand your
intentions if you are not accurate with the typing. For example, if you
forget index.md in the previous command.
ERROR
Note: checking out 'f22b25e'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at f22b25e Start notes on Mars as a baseThe “detached HEAD” is like “look, but don’t touch” here, so you
shouldn’t make any changes in this state. After investigating your
repo’s past state, reattach your HEAD with
git checkout main.
It’s important to remember that we must use the commit number that
identifies the state of the repository before the change we’re
trying to undo. A common mistake is to use the number of the commit in
which we made the change we’re trying to discard. In the example below,
we want to retrieve the state from before the most recent commit
(HEAD~1), which is commit f22b25e:

So, to put it all together, here’s how Git works in cartoon form:

Simplifying the Common Case
If you read the output of git status carefully, you’ll
see that it includes this hint:
OUTPUT
(use "git checkout -- <file>..." to discard changes in working directory)As it says, git checkout without a version identifier
restores files to the state saved in HEAD. The double dash
-- is needed to separate the names of the files being
recovered from the command itself: without it, Git would try to use the
name of the file as the commit identifier.
The fact that files can be reverted one by one tends to change the way people organize their work. If everything is in one large document, it’s hard (but not impossible) to undo changes to the introduction without also undoing changes made later to the conclusion. If the introduction and conclusion are stored in separate files, on the other hand, moving backward and forward in time becomes much easier.
Recovering Older Versions of a File
Jennifer has made changes to the Python script that she has been working on for weeks, and the modifications she made this morning “broke” the script and it no longer runs. She has spent ~ 1hr trying to fix it, with no luck…
Luckily, she has been keeping track of her project’s versions using
Git! Which commands below will let her recover the last committed
version of her Python script called data_cruncher.py?
$ git checkout HEAD$ git checkout HEAD data_cruncher.py$ git checkout HEAD~1 data_cruncher.py$ git checkout <unique ID of last commit> data_cruncher.pyBoth 2 and 4
The answer is (5)-Both 2 and 4.
The checkout command restores files from the repository,
overwriting the files in your working directory. Answers 2 and 4 both
restore the latest version in the repository of the
file data_cruncher.py. Answer 2 uses HEAD to
indicate the latest, whereas answer 4 uses the unique ID of the
last commit, which is what HEAD means.
Answer 3 gets the version of data_cruncher.py from the
commit before HEAD, which is NOT what we
wanted.
Answer 1 can be dangerous! Without a filename,
git checkout will restore all files in the
current directory (and all directories below it) to their state at the
commit specified. This command will restore
data_cruncher.py to the latest commit version, but it will
also restore any other files that are changed to that version,
erasing any changes you may have made to those files! As discussed
above, you are left in a detached HEAD state, and
you don’t want to be there.
Reverting a Commit
Jennifer is collaborating with colleagues on her Python script. She
realizes her last commit to the project’s repository contained an error,
and wants to undo it. Jennifer wants to undo correctly so everyone in
the project’s repository gets the correct change. The command
git revert [erroneous commit ID] will create a new commit
that reverses the erroneous commit.
The command git revert is different from
git checkout [commit ID] because git checkout
returns the files not yet committed within the local repository to a
previous state, whereas git revert reverses changes
committed to the local and project repositories.
Below are the right steps and explanations for Jennifer to use
git revert, what is the missing command?
________ # Look at the git history of the project to find the commit IDCopy the ID (the first few characters of the ID, e.g. 0b1d055).
git revert [commit ID]Type in the new commit message.
Save and close
The command git log lists project history with commit
IDs.
The command git show HEAD shows changes made at the
latest commit, and lists the commit ID; however, Jennifer should
double-check it is the correct commit, and no one else has committed
changes to the repository.
Understanding Workflow and History
What is the output of the last command in
BASH
$ cd planets
$ echo "Venus is beautiful and full of love" > venus.txt
$ git add venus.txt
$ echo "Venus is too hot to be suitable as a base" >> venus.txt
$ git commit -m "Comment on Venus as an unsuitable base"
$ git checkout HEAD venus.txt
$ cat venus.txt #this will print the contents of venus.txt to the screenOUTPUT
Venus is too hot to be suitable as a baseOUTPUT
Venus is beautiful and full of loveOUTPUT
Venus is beautiful and full of love Venus is too hot to be suitable as a baseOUTPUT
Error because you have changed venus.txt without committing the changes
The answer is 2.
The command git add venus.txt places the current version
of venus.txt into the staging area. The changes to the file
from the second echo command are only applied to the
working copy, not the version in the staging area.
So, when
git commit -m "Comment on Venus as an unsuitable base" is
executed, the version of venus.txt committed to the
repository is the one from the staging area and has only one line.
At this time, the working copy still has the second line (and
git status will show that the file is modified). However,
git checkout HEAD venus.txt replaces the working copy with
the most recently committed version of venus.txt.
So, cat venus.txt will output
OUTPUT
Venus is beautiful and full of love.Checking Understanding of
git diff
Consider this command: git diff HEAD~9 index.md. What do
you predict this command will do if you execute it? What happens when
you do execute it? Why?
Try another command, git diff [ID] index.md, where [ID]
is replaced with the unique identifier for your most recent commit. What
do you think will happen, and what does happen?
Getting Rid of Staged Changes
git checkout can be used to restore a previous commit
when unstaged changes have been made, but will it also work for changes
that have been staged but not committed? Make a change to
index.md, add that change using git add, then
use git checkout to see if you can remove your change.
After adding a change, git checkout can not be used
directly. Let’s look at the output of git status:
OUTPUT
On branch main
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: index.md
Note that if you don’t have the same output you may either have forgotten to change the file, or you have added it and committed it.
Using the command git checkout -- index.md now does not
give an error, but it does not restore the file either. Git helpfully
tells us that we need to use git reset first to unstage the
file:
OUTPUT
Unstaged changes after reset:
M index.mdNow, git status gives us:
OUTPUT
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: index.md
no changes added to commit (use "git add" and/or "git commit -a")This means we can now use git checkout to restore the
file to the previous commit:
OUTPUT
On branch main
nothing to commit, working tree cleanExplore and Summarize Histories
Exploring history is an important part of Git, and often it is a challenge to find the right commit ID, especially if the commit is from several months ago.
Imagine the simple-site project has more than 50 files.
You would like to find a commit that modifies some specific text in
index.md. When you type git log, a very long
list appeared. How can you narrow down the search?
Recall that the git diff command allows us to explore
one specific file, e.g., git diff index.md. We can apply a
similar idea here.
Unfortunately some of these commit messages are very ambiguous, e.g.,
update files. How can you search through these files?
Both git diff and git log are very useful
and they summarize a different part of the history for you. Is it
possible to combine both? Let’s try the following:
You should get a long list of output, and you should be able to see both commit messages and the difference between each commit.
Question: What does the following command do?
Key Points
-
git diffdisplays differences between commits. -
git checkoutrecovers old versions of files.
Content from Ignoring Things
Last updated on 2023-09-25 | Edit this page
Overview
Questions
- How can I tell Git to ignore files I don’t want to track?
Objectives
- Configure Git to ignore specific files.
- Explain why ignoring files can be useful.
What if we have files that we do not want Git to track for us, like backup files created by our editor or intermediate files created during data analysis? Let’s create a few dummy files:
and see what Git says:
OUTPUT
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
a.csv
b.csv
c.csv
results/
nothing added to commit but untracked files present (use "git add" to track)Putting these files under version control would be a waste of disk space. What’s worse, having them all listed could distract us from changes that actually matter, so let’s tell Git to ignore them.
We do this by creating a file in the root directory of our project
called .gitignore:
OUTPUT
*.csv
results/These patterns tell Git to ignore any file whose name ends in
.csv and everything in the results directory.
(If any of these files were already being tracked, Git would continue to
track them.)
Once we have created this file, the output of git status
is much cleaner:
OUTPUT
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)The only thing Git notices now is the newly-created
.gitignore file. You might think we wouldn’t want to track
it, but everyone we’re sharing our repository with will probably want to
ignore the same things that we’re ignoring. Let’s add and commit
.gitignore:
OUTPUT
On branch main
nothing to commit, working tree cleanAs a bonus, using .gitignore helps us avoid accidentally
adding files to the repository that we don’t want to track:
OUTPUT
The following paths are ignored by one of your .gitignore files:
a.csv
Use -f if you really want to add them.If we really want to override our ignore settings, we can use
git add -f to force Git to add something. For example,
git add -f a.csv. We can also always see the status of
ignored files if we want:
OUTPUT
On branch main
Ignored files:
(use "git add -f <file>..." to include in what will be committed)
a.csv
b.csv
c.csv
results/
nothing to commit, working tree cleanIf you only want to ignore the contents of
results/plots, you can change your .gitignore
to ignore only the /plots/ subfolder by adding the
following line to your .gitignore:
OUTPUT
results/plots/This line will ensure only the contents of results/plots
is ignored, and not the contents of results/data.
As with most programming issues, there are a few alternative ways that one may ensure this ignore rule is followed. The “Ignoring Nested Files: Variation” exercise has a slightly different directory structure that presents an alternative solution. Further, the discussion page has more detail on ignore rules.
Including Specific Files
How would you ignore all .csv files in your root
directory except for final.csv? Hint: Find out what
! (the exclamation point operator) does
You would add the following two lines to your .gitignore:
OUTPUT
*.csv # ignore all data files
!final.csv # except final.csvThe exclamation point operator will include a previously excluded entry.
Note also that because you’ve previously committed .csv
files in this lesson they will not be ignored with this new rule. Only
future additions of .csv files added to the root directory
will be ignored.
Ignoring Nested Files: Variation
Given a directory structure that looks similar to the earlier Nested Files exercise, but with a slightly different directory structure:
How would you ignore all of the contents in the results folder, but
not results/data?
Hint: think a bit about how you created an exception with the
! operator before.
If you want to ignore the contents of results/ but not
those of results/data/, you can change your
.gitignore to ignore the contents of results folder, but
create an exception for the contents of the results/data
subfolder. Your .gitignore would look like this:
OUTPUT
results/* # ignore everything in results folder
!results/data/ # do not ignore results/data/ contentsIgnoring all data Files in a Directory
Assuming you have an empty .gitignore file, and given a directory structure that looks like:
BASH
results/data/position/gps/a.csv
results/data/position/gps/b.csv
results/data/position/gps/c.csv
results/data/position/gps/info.txt
results/plotsWhat’s the shortest .gitignore rule you could write to
ignore all .csv files in
result/data/position/gps? Do not ignore the
info.txt.
Appending results/data/position/gps/*.csv will match
every file in results/data/position/gps that ends with
.csv. The file
results/data/position/gps/info.txt will not be ignored.
Ignoring all data Files in the repository
Let us assume you have many .csv files in different
subdirectories of your repository. For example, you might have:
BASH
results/a.csv
data/experiment_1/b.csv
data/experiment_2/c.csv
data/experiment_2/variation_1/d.csvHow do you ignore all the .csv files, without explicitly
listing the names of the corresponding folders?
In the .gitignore file, write:
OUTPUT
**/*.csvThis will ignore all the .csv files, regardless of their
position in the directory tree. You can still include some specific
exception with the exclamation point operator.
The ! modifier will negate an entry from a previously
defined ignore pattern. Because the !*.csv entry negates
all of the previous .csv files in the
.gitignore, none of them will be ignored, and all
.csv files will be tracked.
Log Files
You wrote a script that creates many intermediate log-files of the
form log_01, log_02, log_03, etc.
You want to keep them but you do not want to track them through
git.
Write one
.gitignoreentry that excludes files of the formlog_01,log_02, etc.Test your “ignore pattern” by creating some dummy files of the form
log_01, etc.You find that the file
log_01is very important after all, add it to the tracked files without changing the.gitignoreagain.Discuss with your neighbor what other types of files could reside in your directory that you do not want to track and thus would exclude via
.gitignore.
- append either
log_*orlog*as a new entry in your .gitignore - track
log_01usinggit add -f log_01
Key Points
- The
.gitignorefile tells Git what files to ignore.
Content from Remotes in GitHub
Last updated on 2023-09-25 | Edit this page
Overview
Questions
- How do I share my changes with others on the web?
Objectives
- Explain what remote repositories are and why they are useful.
- Push to or pull from a remote repository.
Version control really comes into its own when we begin to collaborate with other people. We already have most of the machinery we need to do this; the only thing missing is to copy changes from one repository to another.
Systems like Git allow us to move work between any two repositories. In practice, though, it’s easiest to use one copy as a central hub, and to keep it on the web rather than on someone’s laptop. Most programmers use hosting services like GitHub, Bitbucket or GitLab to hold those main copies; we’ll explore the pros and cons of this in a later episode.
Let’s start by sharing the changes we’ve made to our current project with the world. To this end we are going to create a remote repository that will be linked to our local repository.
1. Create a remote repository
Log in to GitHub, then click on the
icon in the top right corner to create a new repository called
planets:
Name your repository “planets” and then click “Create Repository”.
Note: Since this repository will be connected to a local repository, it needs to be empty. Leave “Initialize this repository with a README” unchecked, and keep “None” as options for both “Add .gitignore” and “Add a license.” See the “GitHub License and README files” exercise below for a full explanation of why the repository needs to be empty.
As soon as the repository is created, GitHub displays a page with a URL and some information on how to configure your local repository:
This effectively does the following on GitHub’s servers:
If you remember back to the earlier episode where we added and committed our
earlier work on mars.txt, we had a diagram of the local
repository which looked like this:
Now that we have two repositories, we need a diagram like this:

Note that our local repository still contains our earlier work on
mars.txt, but the remote repository on GitHub appears empty
as it doesn’t contain any files yet.
2. Connect local to remote repository
Now we connect the two repositories. We do this by making the GitHub repository a remote for the local repository. The home page of the repository on GitHub includes the URL string we need to identify it:

Click on the ‘SSH’ link to change the protocol from HTTPS to SSH.
HTTPS vs. SSH
We use SSH here because, while it requires some additional configuration, it is a security protocol widely used by many applications. The steps below describe SSH at a minimum level for GitHub.

Copy that URL from the browser, go into the local
planets repository, and run this command:
Make sure to use the URL for your repository rather than Vlad’s: the
only difference should be your username instead of
vlad.
origin is a local name used to refer to the remote
repository. It could be called anything, but origin is a
convention that is often used by default in git and GitHub, so it’s
helpful to stick with this unless there’s a reason not to.
We can check that the command has worked by running
git remote -v:
OUTPUT
origin git@github.com:vlad/planets.git (fetch)
origin git@github.com:vlad/planets.git (push)We’ll discuss remotes in more detail in the next episode, while talking about how they might be used for collaboration.
3. SSH Background and Setup
Before Dracula can connect to a remote repository, he needs to set up a way for his computer to authenticate with GitHub so it knows it’s him trying to connect to his remote repository.
We are going to set up the method that is commonly used by many different services to authenticate access on the command line. This method is called Secure Shell Protocol (SSH). SSH is a cryptographic network protocol that allows secure communication between computers using an otherwise insecure network.
SSH uses what is called a key pair. This is two keys that work together to validate access. One key is publicly known and called the public key, and the other key called the private key is kept private. Very descriptive names.
You can think of the public key as a padlock, and only you have the key (the private key) to open it. You use the public key where you want a secure method of communication, such as your GitHub account. You give this padlock, or public key, to GitHub and say “lock the communications to my account with this so that only computers that have my private key can unlock communications and send git commands as my GitHub account.”
What we will do now is the minimum required to set up the SSH keys and add the public key to a GitHub account.
Advanced SSH
A supplemental episode in this lesson discusses SSH and key pairs in more depth and detail.
The first thing we are going to do is check if this has already been done on the computer you’re on. Because generally speaking, this setup only needs to happen once and then you can forget about it.
Keeping your keys secure
You shouldn’t really forget about your SSH keys, since they keep your account secure. It’s good practice to audit your secure shell keys every so often. Especially if you are using multiple computers to access your account.
We will run the list command to check what key pairs already exist on your computer.
Your output is going to look a little different depending on whether or not SSH has ever been set up on the computer you are using.
Dracula has not set up SSH on his computer, so his output is
OUTPUT
ls: cannot access '/c/Users/Vlad Dracula/.ssh': No such file or directoryIf SSH has been set up on the computer you’re using, the public and
private key pairs will be listed. The file names are either
id_ed25519/id_ed25519.pub or
id_rsa/id_rsa.pub depending on how the key
pairs were set up.
Since they don’t exist on Dracula’s computer, he uses this command to
create them.
3.1 Create an SSH key pair
To create an SSH key pair Vlad uses this command, where the
-t option specifies which type of algorithm to use and
-C attaches a comment to the key (here, Vlad’s email):
If you are using a legacy system that doesn’t support the Ed25519
algorithm, use:
$ ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
OUTPUT
Generating public/private ed25519 key pair.
Enter file in which to save the key (/c/Users/Vlad Dracula/.ssh/id_ed25519):We want to use the default file, so just press Enter.
OUTPUT
Created directory '/c/Users/Vlad Dracula/.ssh'.
Enter passphrase (empty for no passphrase):Now, it is prompting Dracula for a passphrase. Since he is using his lab’s laptop that other people sometimes have access to, he wants to create a passphrase. Be sure to use something memorable or save your passphrase somewhere, as there is no “reset my password” option.
OUTPUT
Enter same passphrase again:After entering the same passphrase a second time, we receive the confirmation
OUTPUT
Your identification has been saved in /c/Users/Vlad Dracula/.ssh/id_ed25519
Your public key has been saved in /c/Users/Vlad Dracula/.ssh/id_ed25519.pub
The key fingerprint is:
SHA256:SMSPIStNyA00KPxuYu94KpZgRAYjgt9g4BA4kFy3g1o vlad@tran.sylvan.ia
The key's randomart image is:
+--[ED25519 256]--+
|^B== o. |
|%*=.*.+ |
|+=.E =.+ |
| .=.+.o.. |
|.... . S |
|.+ o |
|+ = |
|.o.o |
|oo+. |
+----[SHA256]-----+The “identification” is actually the private key. You should never share it. The public key is appropriately named. The “key fingerprint” is a shorter version of a public key.
Now that we have generated the SSH keys, we will find the SSH files when we check.
OUTPUT
drwxr-xr-x 1 Vlad Dracula 197121 0 Jul 16 14:48 ./
drwxr-xr-x 1 Vlad Dracula 197121 0 Jul 16 14:48 ../
-rw-r--r-- 1 Vlad Dracula 197121 419 Jul 16 14:48 id_ed25519
-rw-r--r-- 1 Vlad Dracula 197121 106 Jul 16 14:48 id_ed25519.pub3.2 Copy the public key to GitHub
Now we have a SSH key pair and we can run this command to check if GitHub can read our authentication.
OUTPUT
The authenticity of host 'github.com (192.30.255.112)' can't be established.
RSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? y
Please type 'yes', 'no' or the fingerprint: yes
Warning: Permanently added 'github.com' (RSA) to the list of known hosts.
git@github.com: Permission denied (publickey).Right, we forgot that we need to give GitHub our public key!
First, we need to copy the public key. Be sure to include the
.pub at the end, otherwise you’re looking at the private
key.
OUTPUT
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIDmRA3d51X0uu9wXek559gfn6UFNF69yZjChyBIU2qKI vlad@tran.sylvan.iaNow, going to GitHub.com, click on your profile icon in the top right corner to get the drop-down menu. Click “Settings,” then on the settings page, click “SSH and GPG keys,” on the left side “Account settings” menu. Click the “New SSH key” button on the right side. Now, you can add the title (Dracula uses the title “Vlad’s Lab Laptop” so he can remember where the original key pair files are located), paste your SSH key into the field, and click the “Add SSH key” to complete the setup.
Now that we’ve set that up, let’s check our authentication again from the command line.
OUTPUT
Hi Vlad! You've successfully authenticated, but GitHub does not provide shell access.Good! This output confirms that the SSH key works as intended. We are now ready to push our work to the remote repository.
4. Push local changes to a remote
Now that authentication is setup, we can return to the remote. This command will push the changes from our local repository to the repository on GitHub:
Since Dracula set up a passphrase, it will prompt him for it. If you completed advanced settings for your authentication, it will not prompt for a passphrase.
OUTPUT
Enumerating objects: 16, done.
Counting objects: 100% (16/16), done.
Delta compression using up to 8 threads.
Compressing objects: 100% (11/11), done.
Writing objects: 100% (16/16), 1.45 KiB | 372.00 KiB/s, done.
Total 16 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), done.
To https://github.com/vlad/planets.git
* [new branch] main -> mainProxy
If the network you are connected to uses a proxy, there is a chance that your last command failed with “Could not resolve hostname” as the error message. To solve this issue, you need to tell Git about the proxy:
BASH
$ git config --global http.proxy http://user:password@proxy.url
$ git config --global https.proxy https://user:password@proxy.urlWhen you connect to another network that doesn’t use a proxy, you will need to tell Git to disable the proxy using:
Password Managers
If your operating system has a password manager configured,
git push will try to use it when it needs your username and
password. For example, this is the default behavior for Git Bash on
Windows. If you want to type your username and password at the terminal
instead of using a password manager, type:
in the terminal, before you run git push. Despite the
name, Git
uses SSH_ASKPASS for all credential entry, so you may
want to unset SSH_ASKPASS whether you are using Git via SSH
or https.
You may also want to add unset SSH_ASKPASS at the end of
your ~/.bashrc to make Git default to using the terminal
for usernames and passwords.
Our local and remote repositories are now in this state:

The ‘-u’ Flag
You may see a -u option used with git push
in some documentation. This option is synonymous with the
--set-upstream-to option for the git branch
command, and is used to associate the current branch with a remote
branch so that the git pull command can be used without any
arguments. To do this, simply use git push -u origin main
once the remote has been set up.
We can pull changes from the remote repository to the local one as well:
OUTPUT
From https://github.com/vlad/planets
* branch main -> FETCH_HEAD
Already up-to-date.Pulling has no effect in this case because the two repositories are already synchronized. If someone else had pushed some changes to the repository on GitHub, though, this command would download them to our local repository.
GitHub GUI
Browse to your planets repository on GitHub. Underneath
the Code button, find and click on the text that says “XX commits”
(where “XX” is some number). Hover over, and click on, the three buttons
to the right of each commit. What information can you gather/explore
from these buttons? How would you get that same information in the
shell?
The left-most button (with the picture of a clipboard) copies the
full identifier of the commit to the clipboard. In the shell,
git log will show you the full commit identifier for each
commit.
When you click on the middle button, you’ll see all of the changes
that were made in that particular commit. Green shaded lines indicate
additions and red ones removals. In the shell we can do the same thing
with git diff. In particular,
git diff ID1..ID2 where ID1 and ID2 are commit identifiers
(e.g. git diff a3bf1e5..041e637) will show the differences
between those two commits.
The right-most button lets you view all of the files in the
repository at the time of that commit. To do this in the shell, we’d
need to checkout the repository at that particular time. We can do this
with git checkout ID where ID is the identifier of the
commit we want to look at. If we do this, we need to remember to put the
repository back to the right state afterwards!
Uploading files directly in GitHub browser
Github also allows you to skip the command line and upload files directly to your repository without having to leave the browser. There are two options. First you can click the “Upload files” button in the toolbar at the top of the file tree. Or, you can drag and drop files from your desktop onto the file tree. You can read more about this on this GitHub page.
GitHub Timestamp
Create a remote repository on GitHub. Push the contents of your local repository to the remote. Make changes to your local repository and push these changes. Go to the repo you just created on GitHub and check the timestamps of the files. How does GitHub record times, and why?
GitHub displays timestamps in a human readable relative format (i.e. “22 hours ago” or “three weeks ago”). However, if you hover over the timestamp, you can see the exact time at which the last change to the file occurred.
Push vs. Commit
In this episode, we introduced the “git push” command. How is “git push” different from “git commit”?
When we push changes, we’re interacting with a remote repository to update it with the changes we’ve made locally (often this corresponds to sharing the changes we’ve made with others). Commit only updates your local repository.
GitHub License and README files
In this episode we learned about creating a remote repository on GitHub, but when you initialized your GitHub repo, you didn’t add a README.md or a license file. If you had, what do you think would have happened when you tried to link your local and remote repositories?
In this case, we’d see a merge conflict due to unrelated histories. When GitHub creates a README.md file, it performs a commit in the remote repository. When you try to pull the remote repository to your local repository, Git detects that they have histories that do not share a common origin and refuses to merge.
OUTPUT
warning: no common commits
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/vlad/planets
* branch main -> FETCH_HEAD
* [new branch] main -> origin/main
fatal: refusing to merge unrelated historiesYou can force git to merge the two repositories with the option
--allow-unrelated-histories. Be careful when you use this
option and carefully examine the contents of local and remote
repositories before merging.
OUTPUT
From https://github.com/vlad/planets
* branch main -> FETCH_HEAD
Merge made by the 'recursive' strategy.
README.md | 1 +
1 file changed, 1 insertion(+)
create mode 100644 README.mdKey Points
- A local Git repository can be connected to one or more remote repositories.
- Use the SSH protocol to connect to remote repositories.
-
git pushcopies changes from a local repository to a remote repository. -
git pullcopies changes from a remote repository to a local repository.
Content from Hosting Websites on GitHub
Last updated on 2023-10-23 | Edit this page
Overview
Questions
- “How do I publish my page or a website on the Web via GitHub?”
Objectives
- “Publish Markdown files as HTML on the Web with GitHub Pages”
Now that you know how to create Markdown files, let’s see how to turn them into Web pages. GitHub has a service just for that called GitHub Pages.
Publishing a Website With GitHub Pages
GitHub Pages is a free website hosting service by GitHub that takes files (Markdown, HTML, CSS, JavaScript, etc.) from your GitHub repository which is configured as a website, optionally runs the files through a build process, combines them and publishes them as a website. Any changes you do to the files in your website’s GitHub repository will be rendered live in the website.
There are other services available to create and publish websites but one of the main advantages of GitHub Pages is that you can version control your website and therefore keep track of all your changes. This is particularly helpful for collaborating on a project website. GitLab offers very similar services but GitHub pages is the simplest approach.
Let’s continue from the GitHub repository we have created in the
previous episode. One important file you should already have is
README.md, which will become the homepage of your project
website (until we add the index file later on).
Enabling GitHub Pages
In order to tell GitHub that your repository contains a website that needs rendering you need to configure GitHub Pages settings. You can do so from your repository’s Settings page, as explained below.
You may have noticed that when we created our repository in previous
episode, by default GitHub created a branch called main and
stored our files there. We now need to tell GitHub Pages that this
branch contains our website files.
What Is a Branch?
You may have never heard about Git branches and wonder what they are.
A branch is one version of your project (the files in your repository)
that can contain its own set of commits - you can have many branches
(versions) of your repository. The default branch automatically created
with a new github repository is called main.
- Click on the repository’s
Settingstab (the one with the little cog/gear icon) as shown on the figure below:
- On the menu on the left hand side, click on
Pages
- You will see that the GitHub Pages settings are currently disabled.
Select branch
mainto tell GitHub which branch to use as a source and clickSaveto enable GitHub Pages for this repository.
- The link to your repository’s website will appear in the highlighted box above. If you click the link - your default browser will open and show your project website. If this does not happen, you should manually open your favourite web browser and paste the URL.
- It may take a while (from a few seconds to a few minutes) for GitHub to compile your website (depending on GitHub’s availability and the complexity of your website) and it may not become visible immediately. You will know it is ready when the link appears in green box with a “tick” in front of the web address (as shown in the figure below).
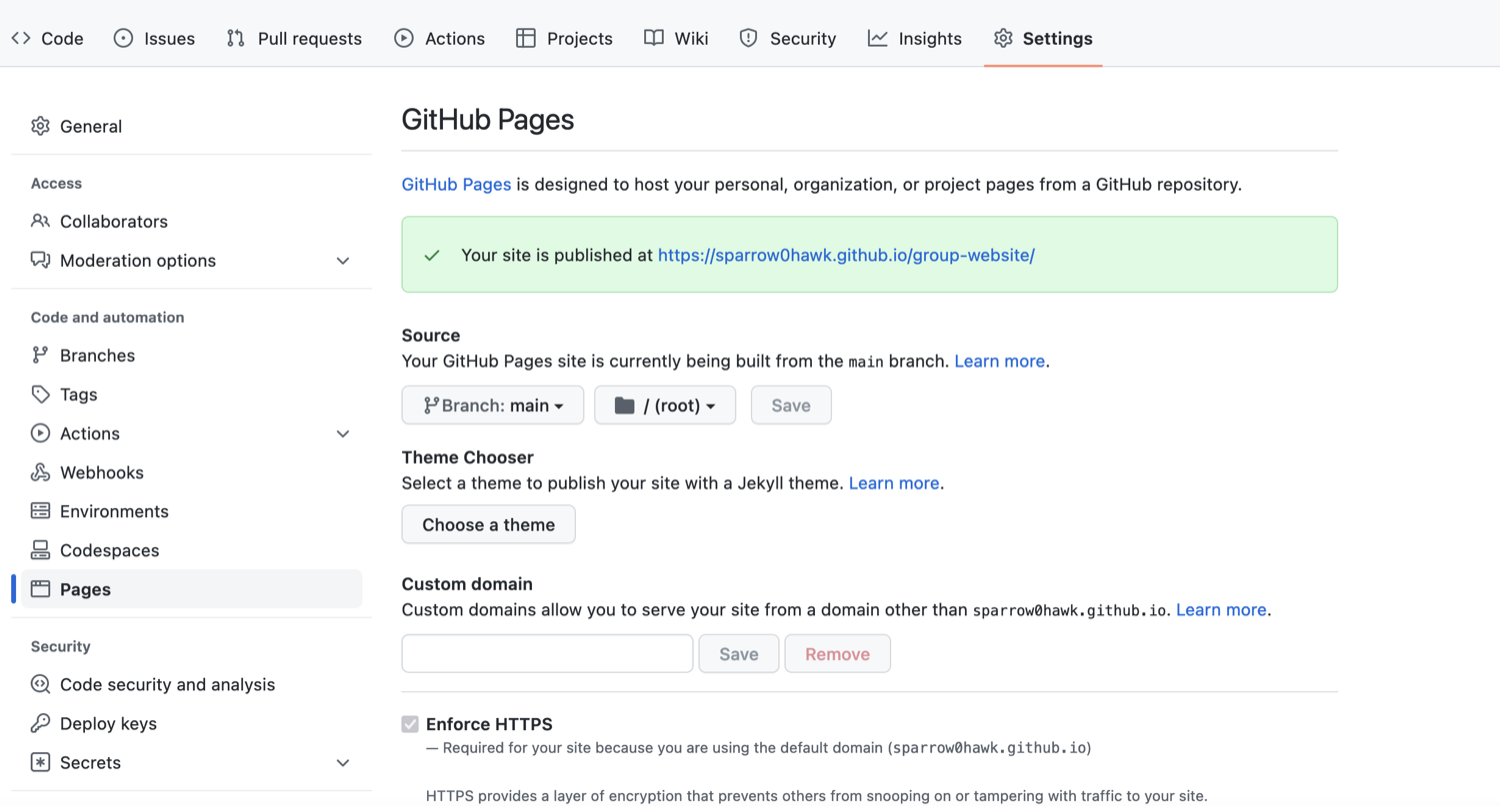
- Once ready, you should see the contents of the
README.mdfile that we created earlier, rendered as a website.
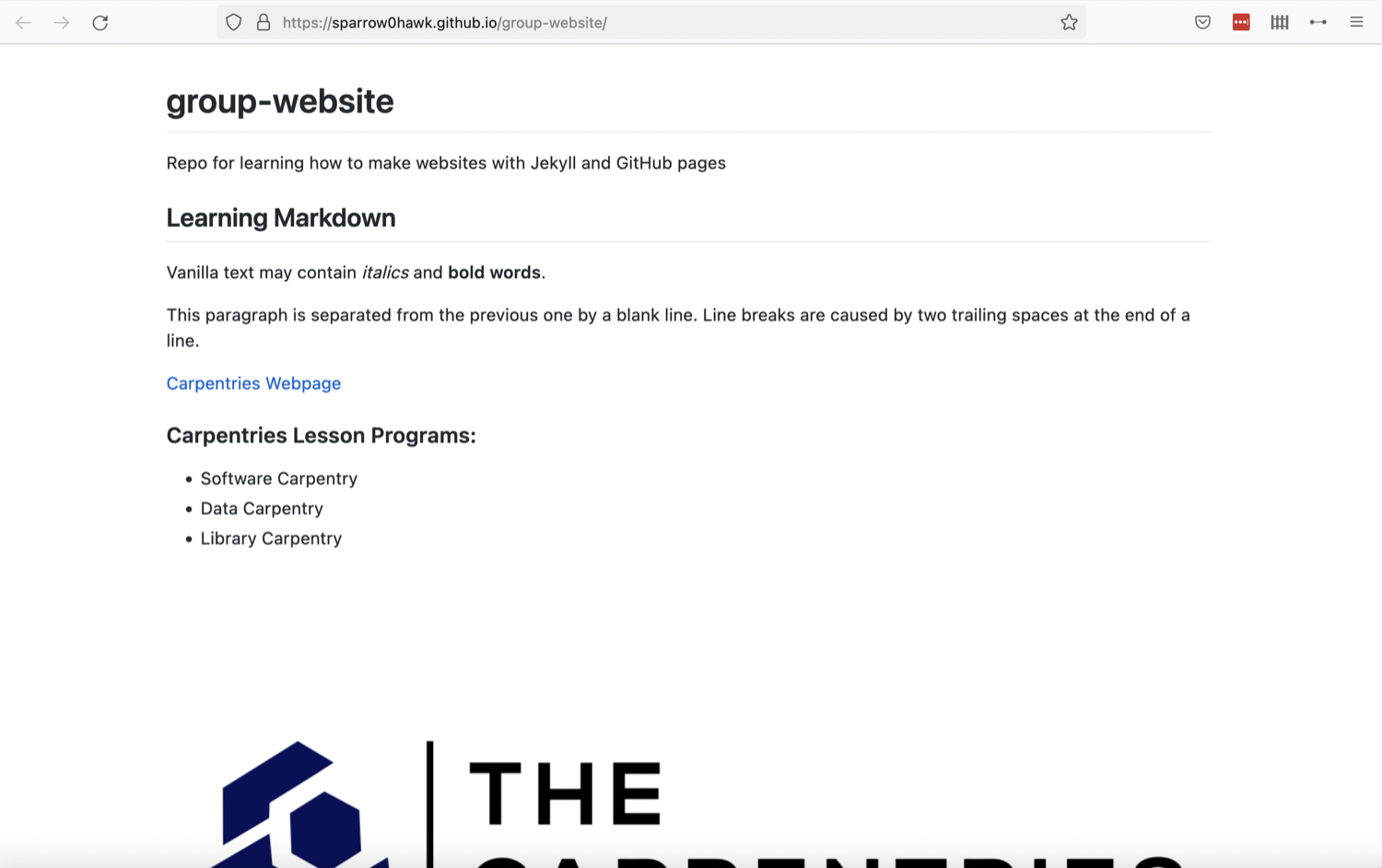
Using Branch gh-pages for
Websites
By convention, GitHub Pages uses branch called gh-pages
to look for the website content. By creating a branch with that name,
you implicitly tell GitHub that you want your content published and you
do not need to configure GitHub Pages in Settings. Once you
create gh-pages from your current branch (typically
main, created by default when you created the repository),
you can then choose to delete the other branch to avoid any confusion
about where your content is stored.
Either of the above two approaches to turning a repository to a
website will give you the same result - the gh-pages
approach is perhaps more common as it favours convention over
configuration.
Understanding GitHub Pages’ URLs
You may have noticed a slightly strange URL for your website appearing in that green box with a “tick” in front of it. This URL was generated by GitHub Pages and is not random. It is formatted as ‘https://GITHUB_USERNAME.github.io/REPOSITORY_NAME’ and is formed by appending:
- your GitHub username or organisation name under which the repository is created (GITHUB_USERNAME)
- ‘.github.io/’ (GitHub’s web hosting domain)
- the repository name (REPOSITORY_NAME)
Because the repository name is unique within one’s personal or organisational GitHub account - this naming convention gives us a way of neatly creating Web addresses for any GitHub repository without any conflicts.
Customising Domain
GitHub Pages supports using custom domains, or changing your site’s URL from the default ‘https://GITHUB_USERNAME.github.io/REPOSITORY_NAME’ to any domain you own. Check out the documentation on configuring a custom domain for your GitHub Pages site.
Making Your Pages More Findable
On the right hand side of your repository on GitHub, you can see the
details of your repository under ‘About’. It is good practice to update
your repository details with a brief description. This is also a place
where you can put your repository’s Web URL (as not everyone will have
access to your repository’s Settings to find it) and add
descriptive topics or tags about the content or technologies used in
your repository or project.
You can edit the details of your repository by clicking on the little cog/gear button as shown on the figure below.
By doing this, you add a link to the repository’s website on your repository’s landing page and anyone (including yourself) can access it quickly when visiting your GitHub repository.
Index Page
Up to now, the content of your webpage is identical to what visitors
to your repository on GitHub will see in the project’s
README.md file. It is often better to have different
content in the homepage of your site - aimed at visitors to the website
- than in the README, which is supposed to provide information about the
GitHub repository e.g. license information, local installation
instructions, the structure and configuration of the repository, list of
collaborators/authors, etc. By default, the homepage for a GitHub Pages
website is built from a file called index.md: in the
absence of a file with that name the “fallback” option is to use
README.md, which is why your homepage is currently being
built from that file.
To separate the contents of the repository’s README from the
website’s homepage, create a new file called index.md.
To create a new file from GitHub interface, click the
Add file button and select Create new file
from the dropdown.
Next, type some text into index.md. As shown below add a
first level header that says
Building Websites in GitHub.
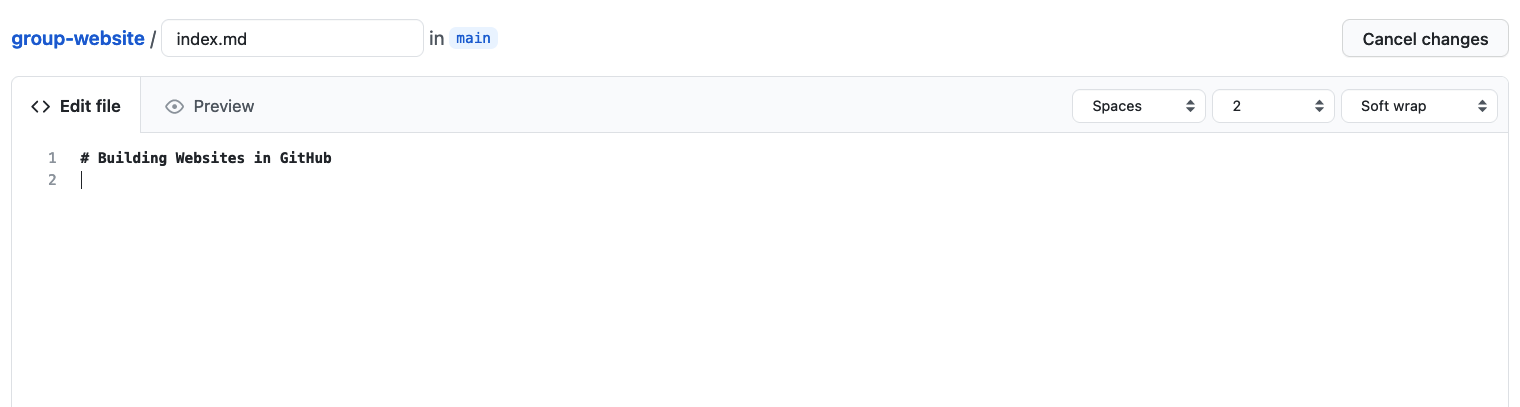
We are now ready to start adding more content to our website. Let’s do some exercises.
Exercise: Add New Content to the Website
Add a new section ‘Description’ to file index.md and add
some description. 1. From the GitHub interface, edit file
index.md and add a new section called
Description to it, with some text about the project. 2.
View the changes on the website.
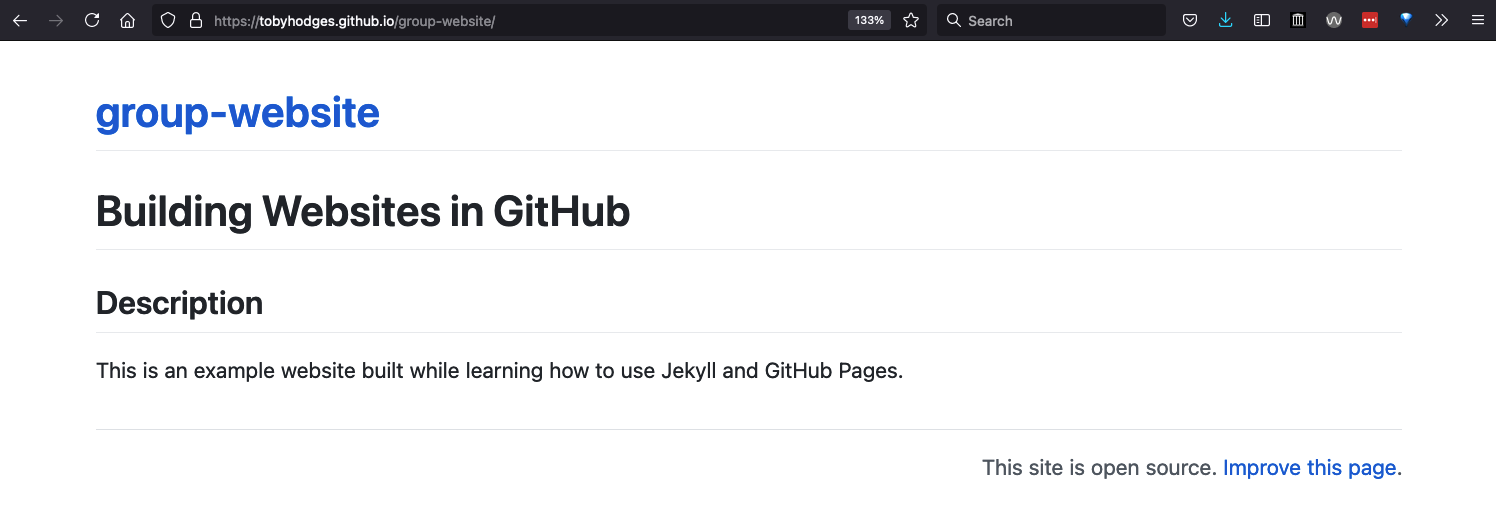
Both the pages built from README.md and
index.md have been served to us at the “root” of our site:
the page we see when we point our browser to
https://YOURUSERNAME.github.io/REPONAME/. The actual name
of this page is index.html (navigate to
https://YOURUSERNAME.github.io/REPONAME/index.html to see
this for yourself), i.e. the file index.md is converted
by Jekyll to a page called index.html.
As more Markdown files are added to your repository, the same process
will automatically occur for those files too. For example, a file called
contact.md will be converted to contact.html
and cake-recipes.md will become
cake-recipes.html. However, unlike the special
index.html file, which Web servers look for as the default
“landing page” to display when handling a request for a URL with a
trailing forward slash, we must request these pages by name when we want
to view them on the Web. Continuing with the above examples, if we
wanted to visit the cake-recipes.html page, we would need
to point our browser at
https://YOURUSERNAME.github.io/REPONAME/cake-recipes.html,
and https://YOURUSERNAME.github.io/REPONAME/contact.html
for the page built from contact.md.
However, when linking between pages of the same site
(relative linking), GitHub Pages allows us to refer to the name
of the original Markdown file, and handles the URL conversion for us.
This means that, to link to cake-recipes.html from
index.html, we can write a link such as
[Read our recipe for Triple Chocolate Raspberry Surprise Cake and more](cake-recipes.md)
and Jekyll will convert this to the appropriate URL. (It won’t write or
bake the recipe for us, unfortunately.) Relative links can point to
files in other directories too:
recipes/chocolate-salted-caramel-pudding.md and
../local-dentists.md are both valid link targets (assuming
the relevant files exist in your repository).
Exercise: Create Links Between Pages
Create a new file about.md and link to it from
index.md. 1. From the GitHub interface, create a new
Markdown file called about.md and add some content to it.
2. Add a link to about.md from index.md. 3.
View the changes on the website.
- Create a new file called
about.mdfrom the GitHub interface:
Edit about.md file to look something like:
MD
# About
## Project
This research project is all about teaching you how to create websites with GitHub pages.
## Funders
We gratefully acknowledge funding from the XYZ Founding Council, under grant number 'abc'.
## Cite us
You can cite the project as:
> *The Carpentries 2019 Annual Report. Zenodo. https://doi.org/10.5281/zenodo.3840372*
## Contact us
- Email: [team@carpentries.org](mailto:team@carpentries.org)
- Twitter: [@thecarpentries](https://twitter.com/thecarpentries)Note how we used various Markdown syntax: quoted text
(>), italic font (*) and external links (a
combination of square [] and round brackets ()
containing the link text and mailto or regular Web URLs
respectively).
- Edit
index.mdto add a link toabout.md.
MD
# Building Websites in GitHub
## Description
This is an example website built while learning how to use Jekyll and GitHub Pages.
More details about the project are available from the [About page](about).- Go to your website and click the link to ‘About’ page. It should look like:
Note that the URL has ‘/about’ appended to it - you can use this URL to access the ‘About’ page directly.
Adding a Theme
We can configure out site by adding a new file
_config.yml. Let’s add a basic theme:
OUTPUT
theme: minima
title: YOUR NAMEWe also need to commit the file and push it to GitHub:
Key Points
- “GitHub Pages is a static site hosting service that takes files in various formats (Markdown, HTML, CSS, JavaScript, etc.) straight from a repository on GitHub, runs them through its website engine Jekyll, builds them into a website, and publishes them on the Web”
- “By convention, if you create a branch called
gh-pagesin your repository, it will automatically be published as a website by GitHub” - “You can configure any branch of a repository to be used for website
(it does not have to be
gh-pages)” - “GitHub publishes websites on special URLs formatted as ‘https://GITHUB_USERNAME.github.io/REPOSITORY_NAME’”
Content from Collaborating
Last updated on 2023-10-23 | Edit this page
Overview
Questions
- How can I use version control to collaborate with other people?
Objectives
- Clone a remote repository.
- Collaborate by pushing to a common repository.
- Describe the basic collaborative workflow.
For the next step, get into pairs. One person will be the “Owner” and the other will be the “Collaborator”. The goal is that the Collaborator add changes into the Owner’s repository. We will switch roles at the end, so both persons will play Owner and Collaborator.
Practicing By Yourself
If you’re working through this lesson on your own, you can carry on by opening a second terminal window. This window will represent your partner, working on another computer. You won’t need to give anyone access on GitHub, because both ‘partners’ are you.
The Owner needs to give the Collaborator access. In your repository page on GitHub, click the “Settings” button on the right, select “Collaborators”, click “Add people”, and then enter your partner’s username.
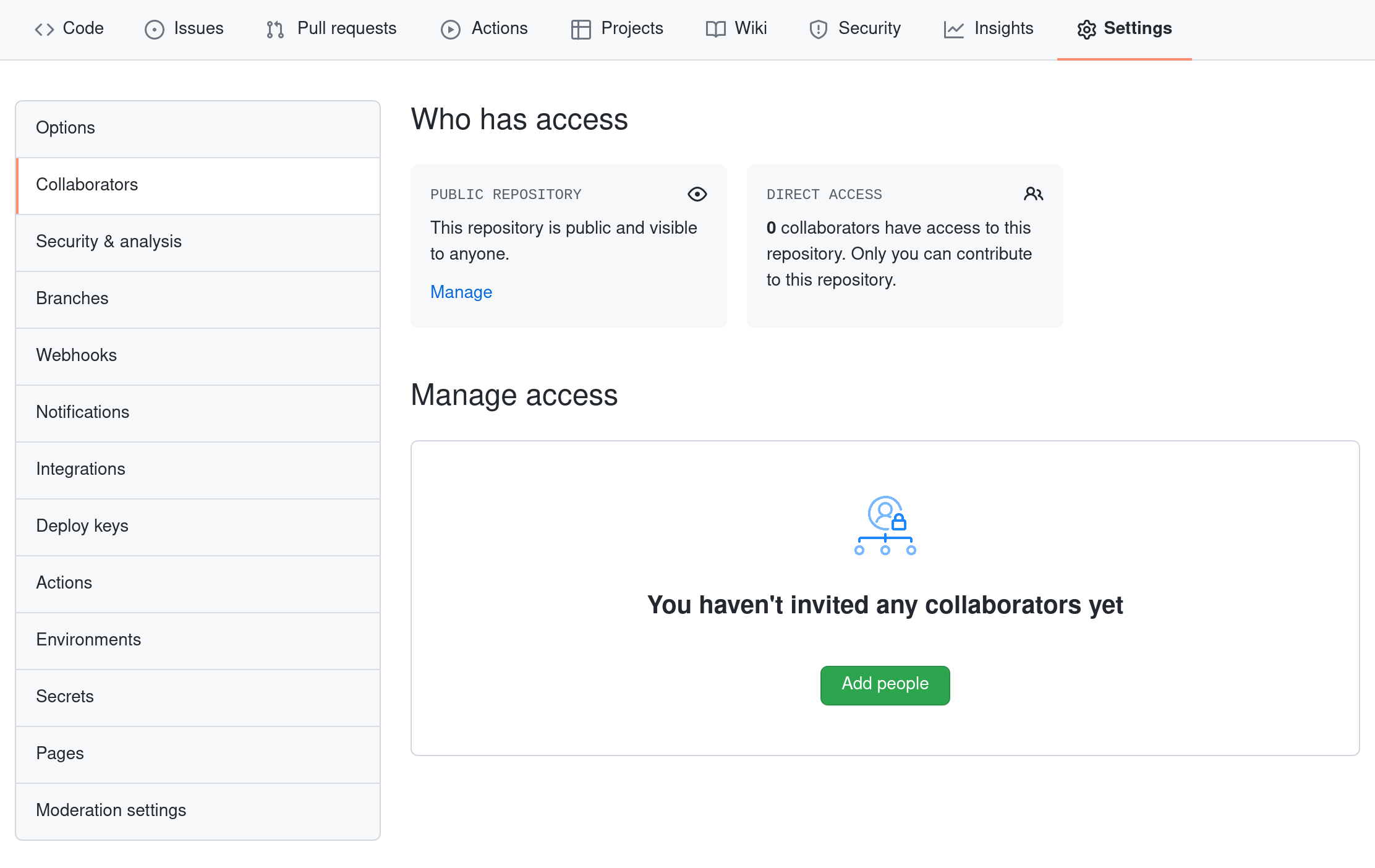
To accept access to the Owner’s repo, the Collaborator needs to go to https://github.com/notifications or check for email notification. Once there she can accept access to the Owner’s repo.
Next, the Collaborator needs to download a copy of the Owner’s repository to her machine. This is called “cloning a repo”.
The Collaborator doesn’t want to overwrite her own version of
simple-site.git, so needs to clone the Owner’s repository
to a different location than her own repository with the same name.
To clone the Owner’s repo into her Desktop folder, the
Collaborator enters:
Replace ‘vlad’ with the Owner’s username.
If you choose to clone without the clone path
(~/Desktop/vlad-simple-site) specified at the end, you will
clone inside your own simple-site folder! Make sure to navigate to the
Desktop folder first.

The Collaborator can now make a change in her clone of the Owner’s repository, exactly the same way as we’ve been doing before:
OUTPUT
---
title: "Our Team"
---
[Name] is a __ at UCSB. Their responsibilities include:
- Carpentry Workshops
[Name] is a ___ at UCSB. Their responsibilities include:
- Learning Git
OUTPUT
1 file changed, 1 insertion(+)
create mode 100644 index.mdThen push the change to the Owner’s repository on GitHub:
OUTPUT
Enumerating objects: 4, done.
Counting objects: 4, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 306 bytes, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/vlad/simple-site.git
9272da5..29aba7c main -> mainNote that we didn’t have to create a remote called
origin: Git uses this name by default when we clone a
repository. (This is why origin was a sensible choice
earlier when we were setting up remotes by hand.)
Take a look at the Owner’s repository on GitHub again, and you should be able to see the new commit made by the Collaborator. You may need to refresh your browser to see the new commit.
Some more about remotes
In this episode and the previous one, our local repository has had a
single “remote”, called origin. A remote is a copy of the
repository that is hosted somewhere else, that we can push to and pull
from, and there’s no reason that you have to work with only one. For
example, on some large projects you might have your own copy in your own
GitHub account (you’d probably call this origin) and also
the main “upstream” project repository (let’s call this
upstream for the sake of examples). You would pull from
upstream from time to time to get the latest updates that
other people have committed.
Remember that the name you give to a remote only exists locally. It’s
an alias that you choose - whether origin, or
upstream, or fred - and not something
intrinstic to the remote repository.
The git remote family of commands is used to set up and
alter the remotes associated with a repository. Here are some of the
most useful ones:
-
git remote -vlists all the remotes that are configured (we already used this in the last episode) -
git remote add [name] [url]is used to add a new remote -
git remote remove [name]removes a remote. Note that it doesn’t affect the remote repository at all - it just removes the link to it from the local repo. -
git remote set-url [name] [newurl]changes the URL that is associated with the remote. This is useful if it has moved, e.g. to a different GitHub account, or from GitHub to a different hosting service. Or, if we made a typo when adding it! -
git remote rename [oldname] [newname]changes the local alias by which a remote is known - its name. For example, one could use this to changeupstreamtofred.
To download the Collaborator’s changes from GitHub, the Owner now enters:
OUTPUT
remote: Enumerating objects: 4, done.
remote: Counting objects: 100% (4/4), done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 3 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/vlad/simple-site
* branch main -> FETCH_HEAD
9272da5..29aba7c main -> origin/main
Updating 9272da5..29aba7c
Fast-forward
index.md | 1 +
1 file changed, 1 insertion(+)
create mode 100644 index.mdNow the three repositories (Owner’s local, Collaborator’s local, and Owner’s on GitHub) are back in sync.
A Basic Collaborative Workflow
In practice, it is good to be sure that you have an updated version
of the repository you are collaborating on, so you should
git pull before making our changes. The basic collaborative
workflow would be:
- update your local repo with
git pull origin main, - make your changes and stage them with
git add, - commit your changes with
git commit -m, and - upload the changes to GitHub with
git push origin main
It is better to make many commits with smaller changes rather than of one commit with massive changes: small commits are easier to read and review.
Switch Roles and Repeat
Switch roles and repeat the whole process.
Review Changes
The Owner pushed commits to the repository without giving any information to the Collaborator. How can the Collaborator find out what has changed with command line? And on GitHub?
On the command line, the Collaborator can use
git fetch origin main to get the remote changes into the
local repository, but without merging them. Then by running
git diff main origin/main the Collaborator will see the
changes output in the terminal.
On GitHub, the Collaborator can go to the repository and click on “commits” to view the most recent commits pushed to the repository.
Version History, Backup, and Version Control
Some backup software can keep a history of the versions of your files. They also allows you to recover specific versions. How is this functionality different from version control? What are some of the benefits of using version control, Git and GitHub?
Key Points
-
git clonecopies a remote repository to create a local repository with a remote calledoriginautomatically set up.
Content from Conflicts
Last updated on 2023-10-23 | Edit this page
Overview
Questions
- What do I do when my changes conflict with someone else’s?
Objectives
- Explain what conflicts are and when they can occur.
- Resolve conflicts resulting from a merge.
As soon as people can work in parallel, they’ll likely step on each other’s toes. This will even happen with a single person: if we are working on a piece of software on both our laptop and a server in the lab, we could make different changes to each copy. Version control helps us manage these conflicts by giving us tools to resolve overlapping changes.
To see how we can resolve conflicts, we must first create one. The
file _config.yml currently looks like this in both
partners’ copies of our simple-site repository:
OUTPUT
theme: minima
title: YOUR NAMELet’s add a line to the collaborator’s copy only:
OUTPUT
theme: minima
title: YOUR NAME
description: My personal websiteand then push the change to GitHub:
OUTPUT
[main 5ae9631] Add a line in our home copy
1 file changed, 1 insertion(+)OUTPUT
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 8 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 331 bytes | 331.00 KiB/s, done.
Total 3 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
To https://github.com/vlad/simple-site.git
29aba7c..dabb4c8 main -> mainNow let’s have the owner make a different change to their copy without updating from GitHub:
OUTPUT
theme: minima
title: YOUR NAME
description: work and projectsWe can commit the change locally:
OUTPUT
[main 07ebc69] Add a line in my copy
1 file changed, 1 insertion(+)but Git won’t let us push it to GitHub:
OUTPUT
To https://github.com/vlad/simple-site.git
! [rejected] main -> main (fetch first)
error: failed to push some refs to 'https://github.com/vlad/simple-site.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Git rejects the push because it detects that the remote repository has new updates that have not been incorporated into the local branch. What we have to do is pull the changes from GitHub, merge them into the copy we’re currently working in, and then push that. Let’s start by pulling:
OUTPUT
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Compressing objects: 100% (1/1), done.
remote: Total 3 (delta 2), reused 3 (delta 2), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/vlad/simple-site
* branch main -> FETCH_HEAD
29aba7c..dabb4c8 main -> origin/main
Auto-merging _config.yml
CONFLICT (content): Merge conflict in _config.yml
Automatic merge failed; fix conflicts and then commit the result.The git pull command updates the local repository to
include those changes already included in the remote repository. After
the changes from remote branch have been fetched, Git detects that
changes made to the local copy overlap with those made to the remote
repository, and therefore refuses to merge the two versions to stop us
from trampling on our previous work. The conflict is marked in in the
affected file:
OUTPUT
theme: minima
title: YOUR NAME
<<<<<<< HEAD
description: My personal website
=======
description: work and projects
>>>>>>> dabb4c8c450e8475aee9b14b4383acc99f42af1dOur change is preceded by
<<<<<<< HEAD. Git has then inserted
======= as a separator between the conflicting changes and
marked the end of the content downloaded from GitHub with
>>>>>>>. (The string of letters and
digits after that marker identifies the commit we’ve just
downloaded.)
It is now up to us to edit this file to remove these markers and reconcile the changes. We can do anything we want: keep the change made in the local repository, keep the change made in the remote repository, write something new to replace both, or get rid of the change entirely. Let’s replace both so that the file looks like this:
OUTPUT
theme: minima
title: YOUR NAME
description: My work and projectsTo finish merging, we add _config.yml to the changes
being made by the merge and then commit:
OUTPUT
On branch main
All conflicts fixed but you are still merging.
(use "git commit" to conclude merge)
Changes to be committed:
modified: _config.yml
OUTPUT
[main 2abf2b1] Merge changes from GitHubNow we can push our changes to GitHub:
OUTPUT
Enumerating objects: 10, done.
Counting objects: 100% (10/10), done.
Delta compression using up to 8 threads
Compressing objects: 100% (6/6), done.
Writing objects: 100% (6/6), 645 bytes | 645.00 KiB/s, done.
Total 6 (delta 4), reused 0 (delta 0)
remote: Resolving deltas: 100% (4/4), completed with 2 local objects.
To https://github.com/vlad/simple-site.git
dabb4c8..2abf2b1 main -> mainGit keeps track of what we’ve merged with what, so we don’t have to fix things by hand again when the collaborator who made the first change pulls again:
OUTPUT
remote: Enumerating objects: 10, done.
remote: Counting objects: 100% (10/10), done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 6 (delta 4), reused 6 (delta 4), pack-reused 0
Unpacking objects: 100% (6/6), done.
From https://github.com/vlad/simple-site
* branch main -> FETCH_HEAD
dabb4c8..2abf2b1 main -> origin/main
Updating dabb4c8..2abf2b1
Fast-forward
_config.yml | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)We get the merged file:
OUTPUT
theme: minima
title: YOUR NAME
description: My work and projectsWe don’t need to merge again because Git knows someone has already done that.
Git’s ability to resolve conflicts is very useful, but conflict resolution costs time and effort, and can introduce errors if conflicts are not resolved correctly. If you find yourself resolving a lot of conflicts in a project, consider these technical approaches to reducing them:
- Pull from upstream more frequently, especially before starting new work
- Use topic branches to segregate work, merging to main when complete
- Make smaller more atomic commits
- Push your work when it is done and encourage your team to do the same to reduce work in progress and, by extension, the chance of having conflicts
- Where logically appropriate, break large files into smaller ones so that it is less likely that two authors will alter the same file simultaneously
Conflicts can also be minimized with project management strategies:
- Clarify who is responsible for what areas with your collaborators
- Discuss what order tasks should be carried out in with your collaborators so that tasks expected to change the same lines won’t be worked on simultaneously
- If the conflicts are stylistic churn (e.g. tabs vs. spaces),
establish a project convention that is governing and use code style
tools (e.g.
htmltidy,perltidy,rubocop, etc.) to enforce, if necessary
Solving Conflicts that You Create
Clone the repository created by your instructor. Add a new file to it, and modify an existing file (your instructor will tell you which one). When asked by your instructor, pull her changes from the repository to create a conflict, then resolve it.
Conflicts on Non-textual files
What does Git do when there is a conflict in an image or some other non-textual file that is stored in version control?
Let’s try it. Suppose Dracula takes a picture of Martian surface and
calls it mars.jpg.
If you do not have an image file of Mars available, you can create a dummy binary file like this:
OUTPUT
-rw-r--r-- 1 vlad 57095 1.0K Mar 8 20:24 mars.jpgls shows us that this created a 1-kilobyte file. It is
full of random bytes read from the special file,
/dev/urandom.
Now, suppose Dracula adds mars.jpg to his
repository:
OUTPUT
[main 8e4115c] Add picture of Martian surface
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 mars.jpgSuppose that Wolfman has added a similar picture in the meantime. His
is a picture of the Martian sky, but it is also called
mars.jpg. When Dracula tries to push, he gets a familiar
message:
OUTPUT
To https://github.com/vlad/simple-site.git
! [rejected] main -> main (fetch first)
error: failed to push some refs to 'https://github.com/vlad/simple-site.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.We’ve learned that we must pull first and resolve any conflicts:
When there is a conflict on an image or other binary file, git prints a message like this:
OUTPUT
$ git pull origin main
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
From https://github.com/vlad/simple-site.git
* branch main -> FETCH_HEAD
6a67967..439dc8c main -> origin/main
warning: Cannot merge binary files: mars.jpg (HEAD vs. 439dc8c08869c342438f6dc4a2b615b05b93c76e)
Auto-merging mars.jpg
CONFLICT (add/add): Merge conflict in mars.jpg
Automatic merge failed; fix conflicts and then commit the result.The conflict message here is mostly the same as it was for
_config.yml, but there is one key additional line:
OUTPUT
warning: Cannot merge binary files: mars.jpg (HEAD vs. 439dc8c08869c342438f6dc4a2b615b05b93c76e)Git cannot automatically insert conflict markers into an image as it does for text files. So, instead of editing the image file, we must check out the version we want to keep. Then we can add and commit this version.
On the key line above, Git has conveniently given us commit
identifiers for the two versions of mars.jpg. Our version
is HEAD, and Wolfman’s version is 439dc8c0....
If we want to use our version, we can use git checkout:
BASH
$ git checkout HEAD mars.jpg
$ git add mars.jpg
$ git commit -m "Use image of surface instead of sky"OUTPUT
[main 21032c3] Use image of surface instead of skyIf instead we want to use Wolfman’s version, we can use
git checkout with Wolfman’s commit identifier,
439dc8c0:
BASH
$ git checkout 439dc8c0 mars.jpg
$ git add mars.jpg
$ git commit -m "Use image of sky instead of surface"OUTPUT
[main da21b34] Use image of sky instead of surfaceWe can also keep both images. The catch is that we cannot keep them under the same name. But, we can check out each version in succession and rename it, then add the renamed versions. First, check out each image and rename it:
BASH
$ git checkout HEAD mars.jpg
$ git mv mars.jpg mars-surface.jpg
$ git checkout 439dc8c0 mars.jpg
$ mv mars.jpg mars-sky.jpgThen, remove the old mars.jpg and add the two new
files:
BASH
$ git rm mars.jpg
$ git add mars-surface.jpg
$ git add mars-sky.jpg
$ git commit -m "Use two images: surface and sky"OUTPUT
[main 94ae08c] Use two images: surface and sky
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 mars-sky.jpg
rename mars.jpg => mars-surface.jpg (100%)Now both images of Mars are checked into the repository, and
mars.jpg no longer exists.
A Typical Work Session
You sit down at your computer to work on a shared project that is tracked in a remote Git repository. During your work session, you take the following actions, but not in this order:
-
Make changes by appending the number
100to a text filenumbers.txt - Update remote repository to match the local repository
- Celebrate your success with some fancy beverage(s)
- Update local repository to match the remote repository
- Stage changes to be committed
- Commit changes to the local repository
In what order should you perform these actions to minimize the chances of conflicts? Put the commands above in order in the action column of the table below. When you have the order right, see if you can write the corresponding commands in the command column. A few steps are populated to get you started.
| order | action . . . . . . . . . . | command . . . . . . . . . . |
|---|---|---|
| 1 | ||
| 2 | echo 100 >> numbers.txt |
|
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | Celebrate! | AFK |
| order | action . . . . . . | command . . . . . . . . . . . . . . . . . . . |
|---|---|---|
| 1 | Update local | git pull origin main |
| 2 | Make changes | echo 100 >> numbers.txt |
| 3 | Stage changes | git add numbers.txt |
| 4 | Commit changes | git commit -m "Add 100 to numbers.txt" |
| 5 | Update remote | git push origin main |
| 6 | Celebrate! | AFK |
Key Points
- Conflicts occur when two or more people change the same lines of the same file.
- The version control system does not allow people to overwrite each other’s changes blindly, but highlights conflicts so that they can be resolved.
Comment Changes in GitHub
The Collaborator has some questions about one line change made by the Owner and has some suggestions to propose.
With GitHub, it is possible to comment on the diff of a commit. Over the line of code to comment, a blue comment icon appears to open a comment window.
The Collaborator posts her comments and suggestions using the GitHub interface.